 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Range Correlation Underlying Childhood Language and Generative Models
Paper and Code
Dec 11, 2017
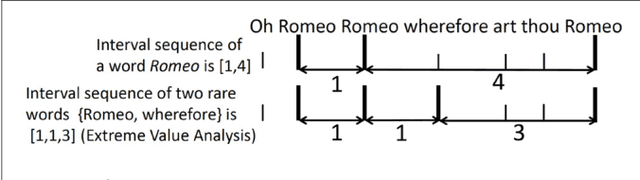

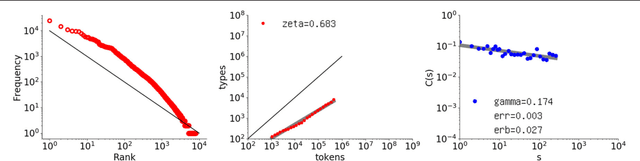
Long-range correlation, a property of time series exhibiting long-term memory, is mainly studied in the statistical physics domain and has been reported to exist in natural language. Using a state-of-the-art method for such analysis, long-range correlation is first shown to occur in long CHILDES data sets. To understand why, Bayesian generative models of language, originally proposed in the cognitive scientific domain, are investigated. Among representative models, the Simon model was found to exhibit surprisingly good long-range correlation, but not the Pitman-Yor model. Since the Simon model is known not to correctly reflect the vocabulary growth of natural language, a simple new model is devised as a conjunct of the Simon and Pitman-Yor models, such that long-range correlation holds with a correct vocabulary growth rate. The investigation overall suggests that uniform sampling is one cause of long-range correlation and could thus have a relation with actual linguistic processes.