 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucinated Translations in Large Language Models with Hallucination-focused Preference Optimization
Jan 28, 2025



Machine Translation (MT) is undergoing a paradigm shift, with systems based on fine-tuned large language models (LLM) becoming increasingly competitive with traditional encoder-decoder models trained specifically for translation tasks. However, LLM-based systems are at a higher risk of generating hallucinations, which can severely undermine user's trust and safety. Most prior research on hallucination mitigation focuses on traditional MT models, with solutions that involve post-hoc mitigation - detecting hallucinated translations and re-translating them. While effective, this approach introduces additional complexity in deploying extra tools in production and also increases latency. To address these limitations, we propose a method that intrinsically learns to mitigate hallucinations during the model training phase. Specifically, we introduce a data creation framework to generate hallucination focused preference datasets. Fine-tuning LLMs on these preference datasets reduces the hallucination rate by an average of 96% across five language pairs, while preserving overall translation quality. In a zero-shot setting our approach reduces hallucinations by 89% on an average across three unseen target languages.
* NAACL 2025 Main Conference Long paper (9 pages)
Speech is More Than Words: Do Speech-to-Text Translation Systems Leverage Prosody?
Oct 31, 2024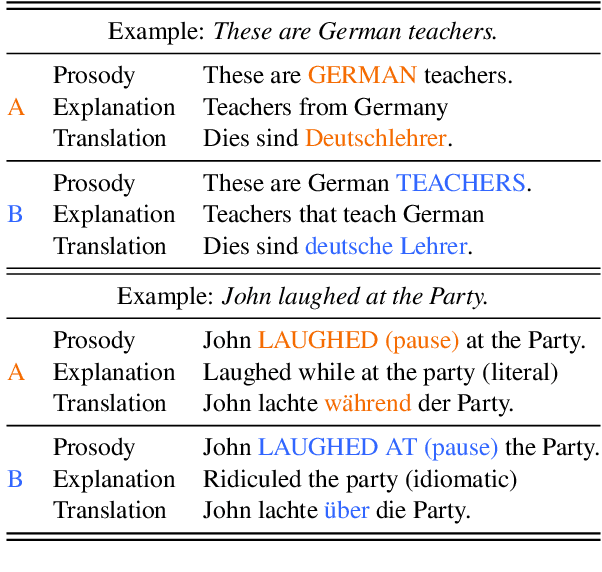
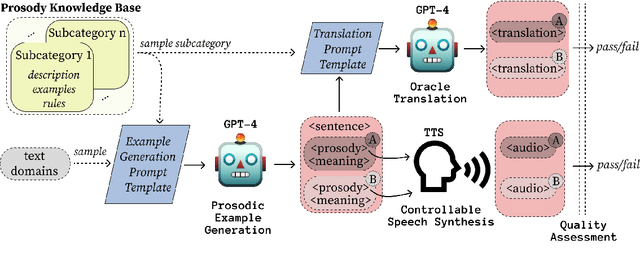

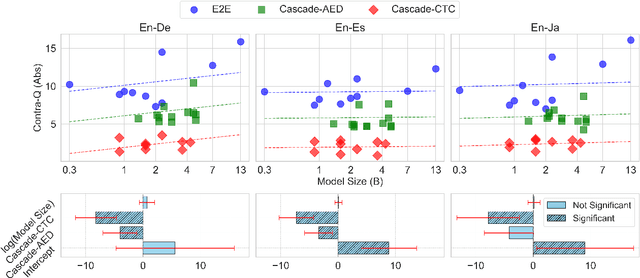
The prosody of a spoken utterance, including features like stress, intonation and rhythm, can significantly affect the underlying semantics, and as a consequence can also affect its textual translation. Nevertheless, prosody is rarely studied within the context of speech-to-text translation (S2TT) systems. In particular, end-to-end (E2E) systems have been proposed as well-suited for prosody-aware translation because they have direct access to the speech signal when making translation decisions, but the understanding of whether this is successful in practice is still limited. A main challenge is the difficulty of evaluating prosody awareness in translation. To address this challenge, we introduce an evaluation methodology and a focused benchmark (named ContraProST) aimed at capturing a wide range of prosodic phenomena. Our methodology uses large language models and controllable text-to-speech (TTS) to generate contrastive examples. Through experiments in translating English speech into German, Spanish, and Japanese, we find that (a) S2TT models possess some internal representation of prosody, but the prosody signal is often not strong enough to affect the translations, (b) E2E systems outperform cascades of speech recognition and text translation systems, confirming their theoretical advantage in this regard, and (c) certain cascaded systems also capture prosodic information in the translation, but only to a lesser extent that depends on the particulars of the transcript's surface form.
Generating Gender Alternatives in Machine Translation
Jul 29, 2024



Machine translation (MT) systems often translate terms with ambiguous gender (e.g., English term "the nurse") into the gendered form that is most prevalent in the systems' training data (e.g., "enfermera", the Spanish term for a female nurse). This often reflects and perpetuates harmful stereotypes present in society. With MT user interfaces in mind that allow for resolving gender ambiguity in a frictionless manner, we study the problem of generating all grammatically correct gendered translation alternatives. We open source train and test datasets for five language pairs and establish benchmarks for this task. Our key technical contribution is a novel semi-supervised solution for generating alternatives that integrates seamlessly with standard MT models and maintains high performance without requiring additional components or increasing inference overhead.
Unconditional Scene Graph Generation
Aug 12, 2021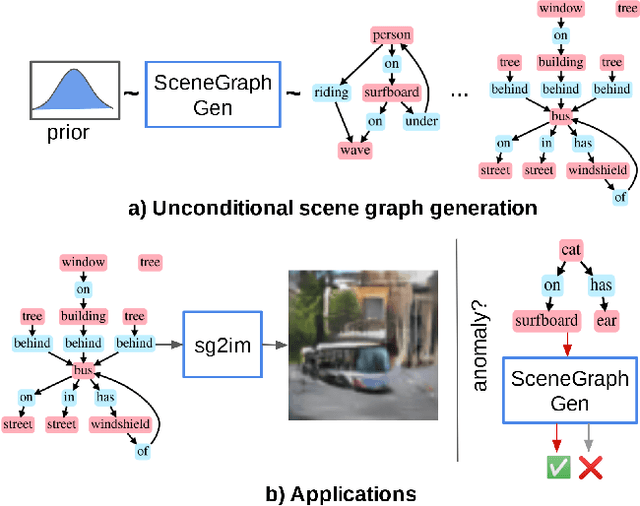

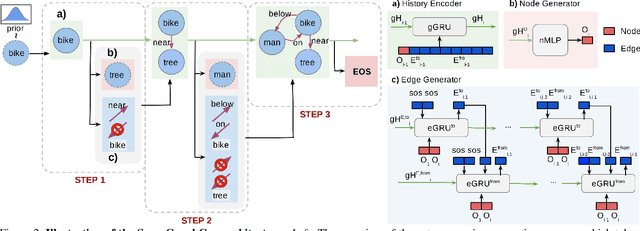
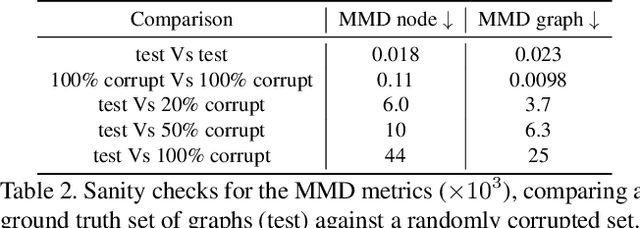
Despite recent advancements in single-domain or single-object image generation, it is still challenging to generate complex scenes containing diverse, multiple objects and their interactions. Scene graphs, composed of nodes as objects and directed-edges as relationships among objects, offer an alternative representation of a scene that is more semantically grounded than images. We hypothesize that a generative model for scene graphs might be able to learn the underlying semantic structure of real-world scenes more effectively than images, and hence, generate realistic novel scenes in the form of scene graphs. In this work, we explore a new task for the unconditional generation of semantic scene graphs. We develop a deep auto-regressive model called SceneGraphGen which can directly learn the probability distribution over labelled and directed graphs using a hierarchical recurrent architecture. The model takes a seed object as input and generates a scene graph in a sequence of steps, each step generating an object node, followed by a sequence of relationship edges connecting to the previous nodes. We show that the scene graphs generated by SceneGraphGen are diverse and follow the semantic patterns of real-world scenes. Additionally, we demonstrate the application of the generated graphs in image synthesis, anomaly detection and scene graph completion.
Efficient Inference For Neural Machine Translation
Oct 07, 2020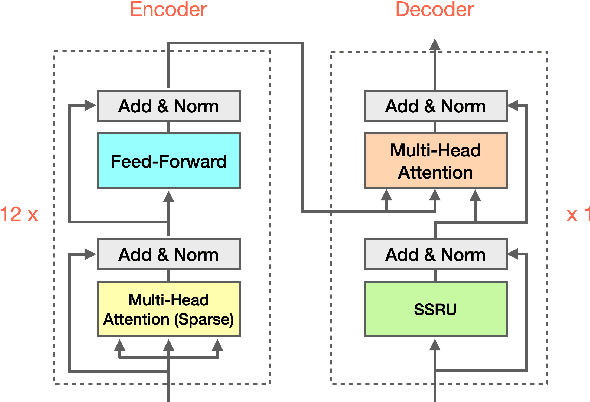
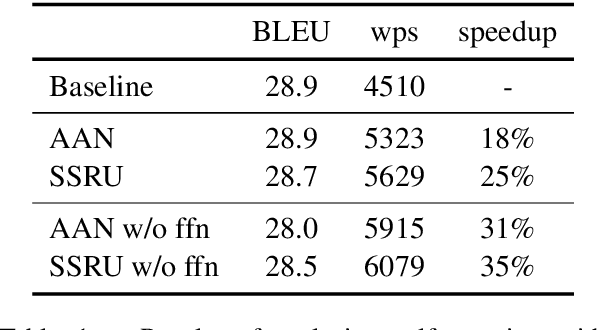
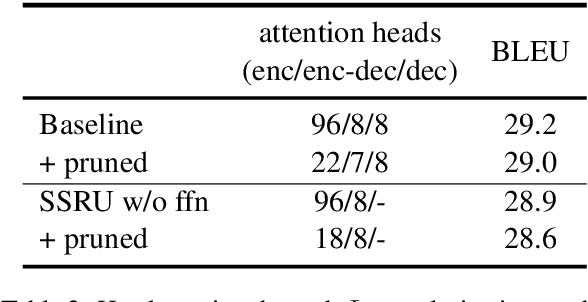
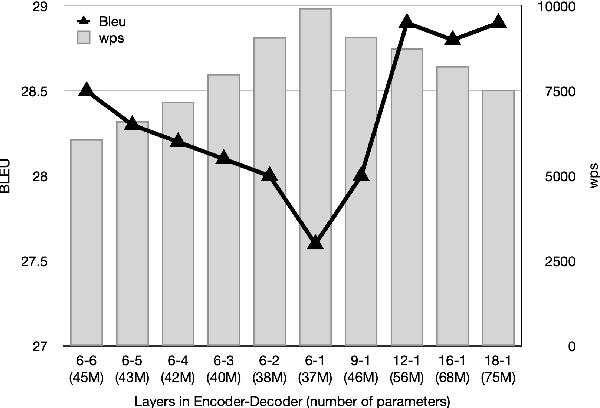
Large Transformer models have achieved state-of-the-art results in neural machine translation and have become standard in the field. In this work, we look for the optimal combination of known techniques to optimize inference speed without sacrificing translation quality. We conduct an empirical study that stacks various approaches and demonstrates that combination of replacing decoder self-attention with simplified recurrent units, adopting a deep encoder and a shallow decoder architecture and multi-head attention pruning can achieve up to 109% and 84% speedup on CPU and GPU respectively and reduce the number of parameters by 25% while maintaining the same translation quality in terms of BLEU.
Learning to Relate from Captions and Bounding Boxes
Dec 01, 2019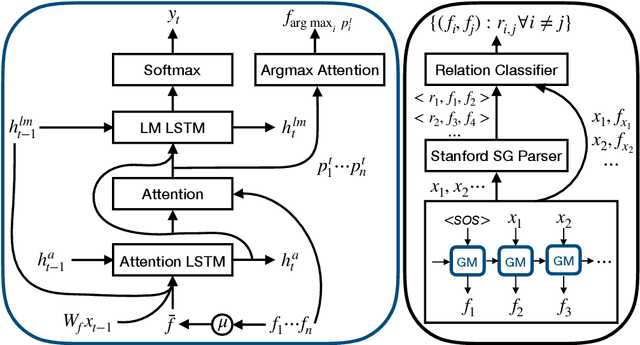



In this work, we propose a novel approach that predicts the relationships between various entities in an image in a weakly supervised manner by relying on image captions and object bounding box annotations as the sole source of supervision. Our proposed approach uses a top-down attention mechanism to align entities in captions to objects in the image, and then leverage the syntactic structure of the captions to align the relations. We use these alignments to train a relation classification network, thereby obtaining both grounded captions and dense relationships. We demonstrate the effectiveness of our model on the Visual Genome dataset by achieving a recall@50 of 15% and recall@100 of 25% on the relationships present in the image. We also show that the model successfully predicts relations that are not present in the corresponding captions.
Jointly Learning to Align and Translate with Transformer Models
Sep 04, 2019

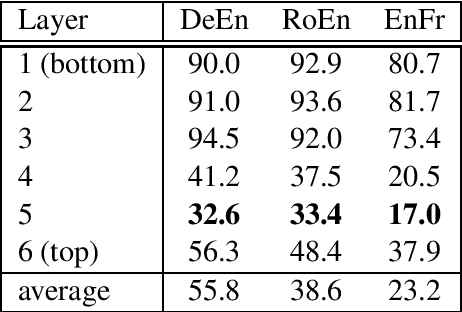
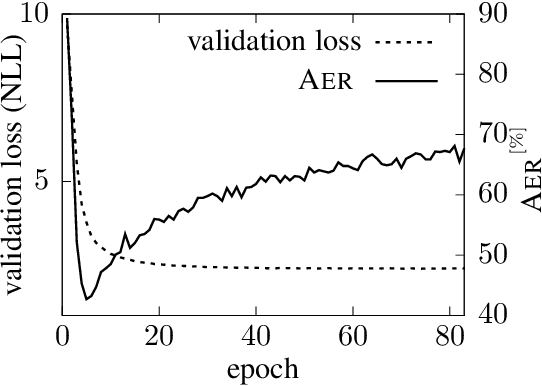
The state of the art in machine translation (MT) is governed by neural approaches, which typically provide superior translation accuracy over statistical approaches. However, on the closely related task of word alignment, traditional statistical word alignment models often remain the go-to solution. In this paper, we present an approach to train a Transformer model to produce both accurate translations and alignments. We extract discrete alignments from the attention probabilities learnt during regular neural machine translation model training and leverage them in a multi-task framework to optimize towards translation and alignment objectives. We demonstrate that our approach produces competitive results compared to GIZA++ trained IBM alignment models without sacrificing translation accuracy and outperforms previous attempts on Transformer model based word alignment. Finally, by incorporating IBM model alignments into our multi-task training, we report significantly better alignment accuracies compared to GIZA++ on three publicly available data sets.
Bilingual Lexicon Induction with Semi-supervision in Non-Isometric Embedding Spaces
Aug 19, 2019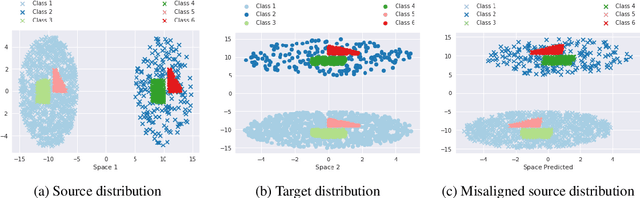

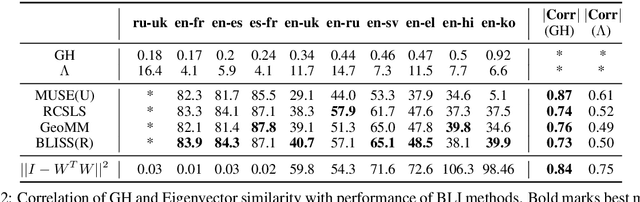

Recent work on bilingual lexicon induction (BLI) has frequently depended either on aligned bilingual lexicons or on distribution matching, often with an assumption about the isometry of the two spaces. We propose a technique to quantitatively estimate this assumption of the isometry between two embedding spaces and empirically show that this assumption weakens as the languages in question become increasingly etymologically distant. We then propose Bilingual Lexicon Induction with Semi-Supervision (BLISS) --- a semi-supervised approach that relaxes the isometric assumption while leveraging both limited aligned bilingual lexicons and a larger set of unaligned word embeddings, as well as a novel hubness filtering technique. Our proposed method obtains state of the art results on 15 of 18 language pairs on the MUSE dataset, and does particularly well when the embedding spaces don't appear to be isometric. In addition, we also show that adding supervision stabilizes the learning procedure, and is effective even with minimal supervision.
* ACL 2019
Compression and Localization in Reinforcement Learning for ATARI Games
Apr 20, 2019
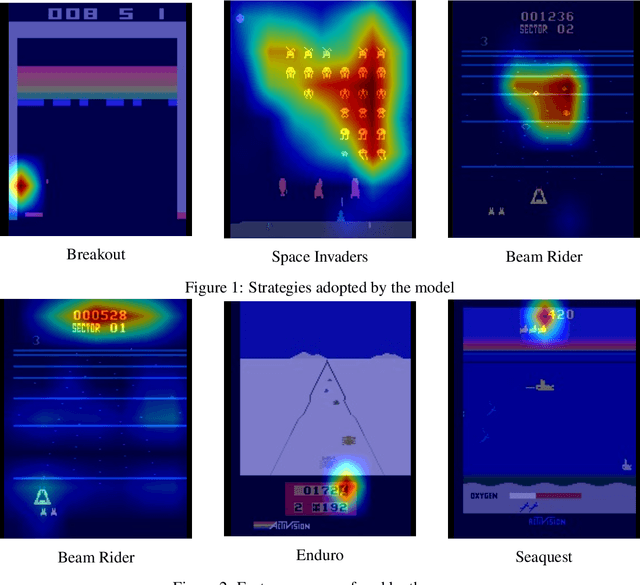

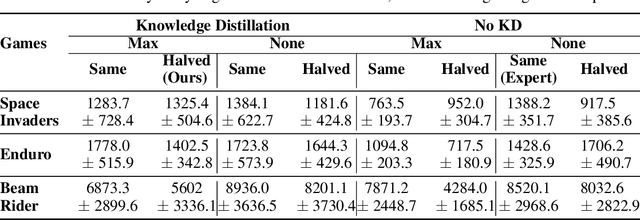
Deep neural networks have become commonplace in the domain of reinforcement learning, but are often expensive in terms of the number of parameters needed. While compressing deep neural networks has of late assumed great importance to overcome this drawback, little work has been done to address this problem in the context of reinforcement learning agents. This work aims at making first steps towards model compression in an RL agent. In particular, we compress networks to drastically reduce the number of parameters in them (to sizes less than 3% of their original size), further facilitated by applying a global max pool after the final convolution layer, and propose using Actor-Mimic in the context of compression. Finally, we show that this global max-pool allows for weakly supervised object localization, improving the ability to identify the agent's points of focus.