 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Relate from Captions and Bounding Boxes
Dec 01, 2019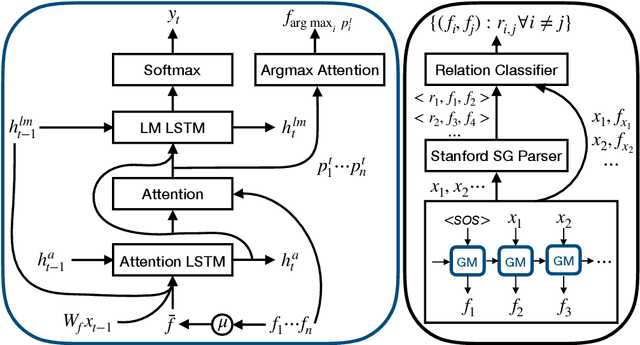



In this work, we propose a novel approach that predicts the relationships between various entities in an image in a weakly supervised manner by relying on image captions and object bounding box annotations as the sole source of supervision. Our proposed approach uses a top-down attention mechanism to align entities in captions to objects in the image, and then leverage the syntactic structure of the captions to align the relations. We use these alignments to train a relation classification network, thereby obtaining both grounded captions and dense relationships. We demonstrate the effectiveness of our model on the Visual Genome dataset by achieving a recall@50 of 15% and recall@100 of 25% on the relationships present in the image. We also show that the model successfully predicts relations that are not present in the corresponding captions.
On Optimizing Human-Machine Task Assignments
Sep 24, 2015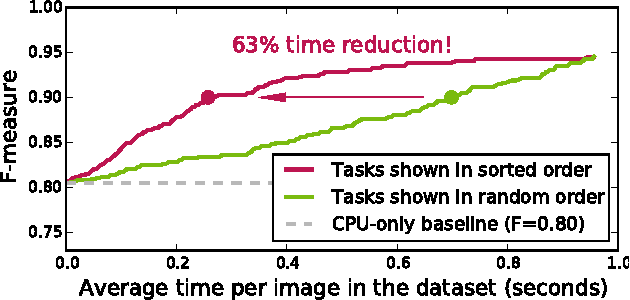
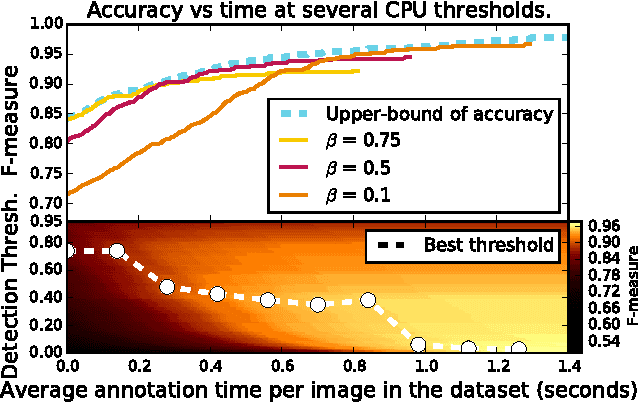
When crowdsourcing systems are used in combination with machine inference systems in the real world, they benefit the most when the machine system is deeply integrated with the crowd workers. However, if researchers wish to integrate the crowd with "off-the-shelf" machine classifiers, this deep integration is not always possible. This work explores two strategies to increase accuracy and decrease cost under this setting. First, we show that reordering tasks presented to the human can create a significant accuracy improvement. Further, we show that greedily choosing parameters to maximize machine accuracy is sub-optimal, and joint optimization of the combined system improves performance.