 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Spectral Bias of the Deep Image Prior
Dec 18, 2019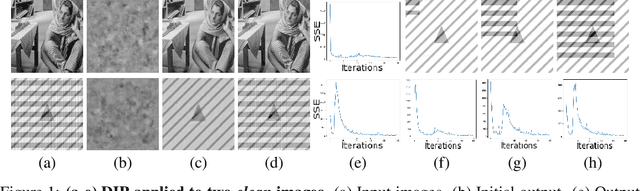

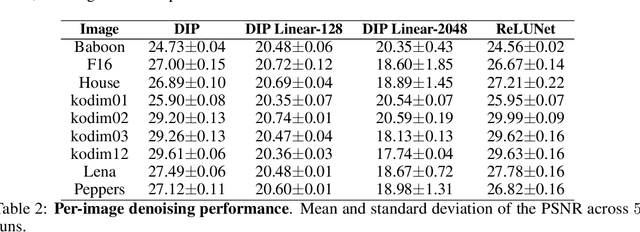

The "deep image prior" proposed by Ulyanov et al. is an intriguing property of neural nets: a convolutional encoder-decoder network can be used as a prior for natural images. The network architecture implicitly introduces a bias; If we train the model to map white noise to a corrupted image, this bias guides the model to fit the true image before fitting the corrupted regions. This paper explores why the deep image prior helps in denoising natural images. We present a novel method to analyze trajectories generated by the deep image prior optimization and demonstrate: (i) convolution layers of the an encoder-decoder decouple the frequency components of the image, learning each at different rates (ii) the model fits lower frequencies first, making early stopping behave as a low pass filter. The experiments study an extension of Cheng et al which showed that at initialization, the deep image prior is equivalent to a stationary Gaussian process.
Automatic adaptation of object detectors to new domains using self-training
Apr 15, 2019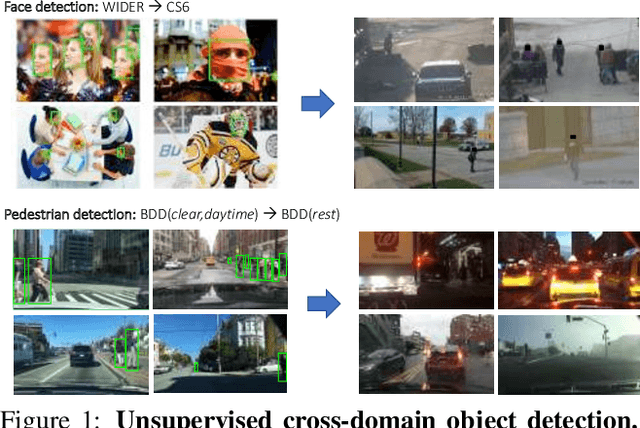
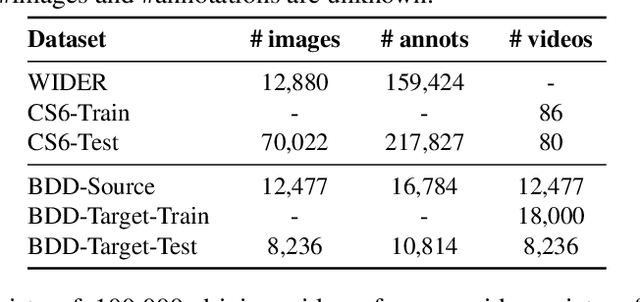

This work addresses the unsupervised adaptation of an existing object detector to a new target domain. We assume that a large number of unlabeled videos from this domain are readily available. We automatically obtain labels on the target data by using high-confidence detections from the existing detector, augmented with hard (misclassified) examples acquired by exploiting temporal cues using a tracker. These automatically-obtained labels are then used for re-training the original model. A modified knowledge distillation loss is proposed, and we investigate several ways of assigning soft-labels to the training examples from the target domain. Our approach is empirically evaluated on challenging face and pedestrian detection tasks: a face detector trained on WIDER-Face, which consists of high-quality images crawled from the web, is adapted to a large-scale surveillance data set; a pedestrian detector trained on clear, daytime images from the BDD-100K driving data set is adapted to all other scenarios such as rainy, foggy, night-time. Our results demonstrate the usefulness of incorporating hard examples obtained from tracking, the advantage of using soft-labels via distillation loss versus hard-labels, and show promising performance as a simple method for unsupervised domain adaptation of object detectors, with minimal dependence on hyper-parameters.
On Optimizing Human-Machine Task Assignments
Sep 24, 2015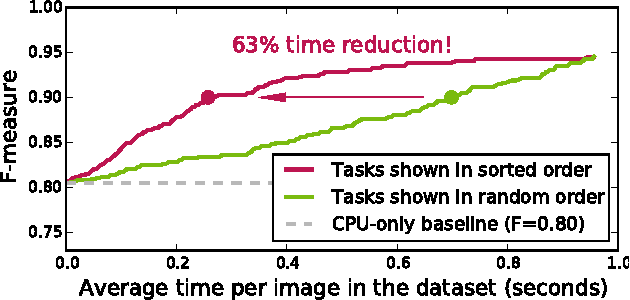
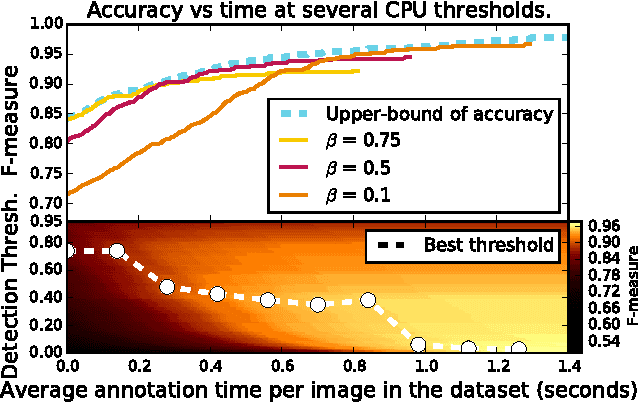
When crowdsourcing systems are used in combination with machine inference systems in the real world, they benefit the most when the machine system is deeply integrated with the crowd workers. However, if researchers wish to integrate the crowd with "off-the-shelf" machine classifiers, this deep integration is not always possible. This work explores two strategies to increase accuracy and decrease cost under this setting. First, we show that reordering tasks presented to the human can create a significant accuracy improvement. Further, we show that greedily choosing parameters to maximize machine accuracy is sub-optimal, and joint optimization of the combined system improves performance.