 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayered Insights: Generalizable Analysis of Authorial Style by Leveraging All Transformer Layers
Mar 02, 2025We propose a new approach for the authorship attribution task that leverages the various linguistic representations learned at different layers of pre-trained transformer-based models. We evaluate our approach on three datasets, comparing it to a state-of-the-art baseline in in-domain and out-of-domain scenarios. We found that utilizing various transformer layers improves the robustness of authorship attribution models when tested on out-of-domain data, resulting in new state-of-the-art results. Our analysis gives further insights into how our model's different layers get specialized in representing certain stylistic features that benefit the model when tested out of the domain.
Explicit and Implicit Semantic Ranking Framework
Apr 11, 2023


The core challenge in numerous real-world applications is to match an inquiry to the best document from a mutable and finite set of candidates. Existing industry solutions, especially latency-constrained services, often rely on similarity algorithms that sacrifice quality for speed. In this paper we introduce a generic semantic learning-to-rank framework, Self-training Semantic Cross-attention Ranking (sRank). This transformer-based framework uses linear pairwise loss with mutable training batch sizes and achieves quality gains and high efficiency, and has been applied effectively to show gains on two industry tasks at Microsoft over real-world large-scale data sets: Smart Reply (SR) and Ambient Clinical Intelligence (ACI). In Smart Reply, $sRank$ assists live customers with technical support by selecting the best reply from predefined solutions based on consumer and support agent messages. It achieves 11.7% gain in offline top-one accuracy on the SR task over the previous system, and has enabled 38.7% time reduction in composing messages in telemetry recorded since its general release in January 2021. In the ACI task, sRank selects relevant historical physician templates that serve as guidance for a text summarization model to generate higher quality medical notes. It achieves 35.5% top-one accuracy gain, along with 46% relative ROUGE-L gain in generated medical notes.
PreDisM: Pre-Disaster Modelling With CNN Ensembles for At-Risk Communities
Dec 26, 2021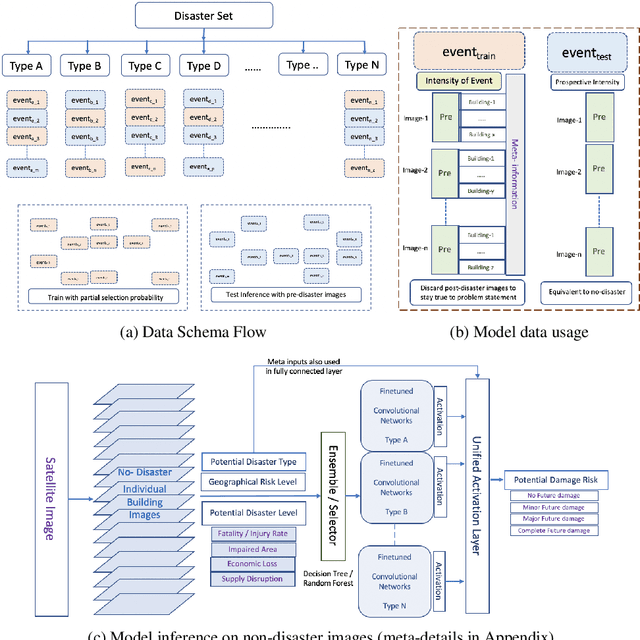

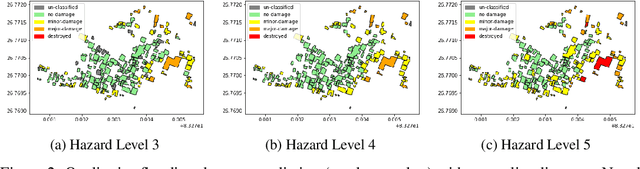
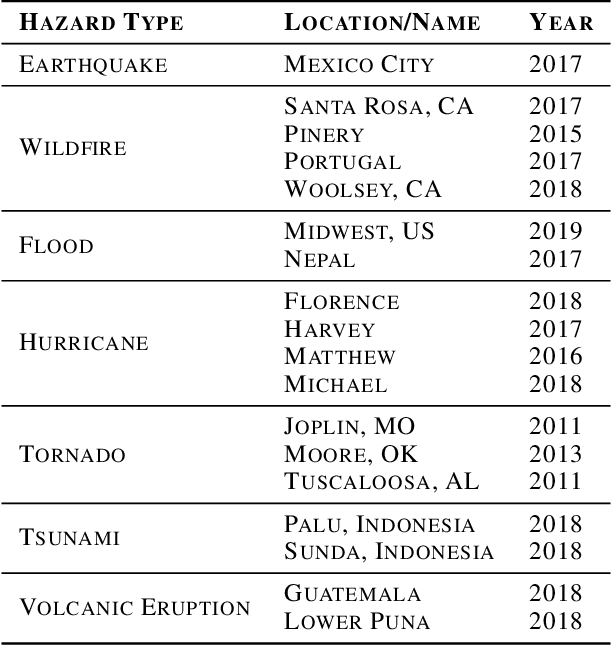
The machine learning community has recently had increased interest in the climate and disaster damage domain due to a marked increased occurrences of natural hazards (e.g., hurricanes, forest fires, floods, earthquakes). However, not enough attention has been devoted to mitigating probable destruction from impending natural hazards. We explore this crucial space by predicting building-level damages on a before-the-fact basis that would allow state actors and non-governmental organizations to be best equipped with resource distribution to minimize or preempt losses. We introduce PreDisM that employs an ensemble of ResNets and fully connected layers over decision trees to capture image-level and meta-level information to accurately estimate weakness of man-made structures to disaster-occurrences. Our model performs well and is responsive to tuning across types of disasters and highlights the space of preemptive hazard damage modelling.
Customized video filtering on YouTube
Nov 19, 2019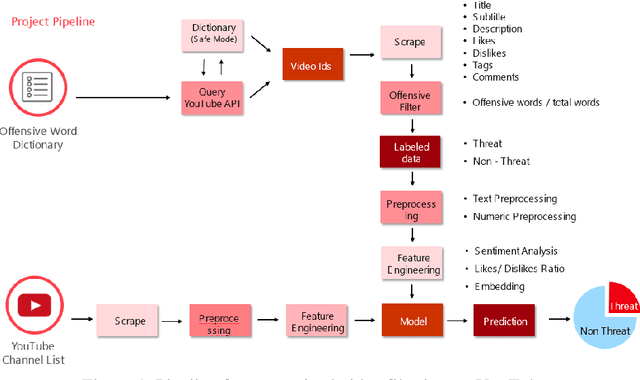

Inappropriate and profane content on social media is exponentially increasing and big corporations are becoming more aware of the type of content on which they are advertising and how it may affect their brand reputation. But with a huge surge in content being posted online it becomes seemingly difficult to filter out related videos on which they can run their ads without compromising brand name. Advertising on youtube videos generates a huge amount of revenue for corporations. It becomes increasingly important for such corporations to advertise on only the videos that don't hurt the feelings, community or harmony of the audience at large. In this paper, we propose a system to identify inappropriate content on YouTube and leverage it to perform a first of its kind, large scale, quantitative characterization that reveals some of the risks of YouTube ads consumption on inappropriate videos. Customization of the architecture have also been included to serve different requirements of corporations. Our analysis reveals that YouTube is still plagued by such disturbing videos and its currently deployed countermeasures are ineffective in terms of detecting them in a timely manner. Our framework tries to fill this gap by providing a handy, add on solution to filter the videos and help corporations and companies to push ads on the platform without worrying about the content on which the ads are displayed.
An automated approach for task evaluation using EEG signals
Nov 14, 2019



Critical task and cognition-based environments, such as in military and defense operations, aviation user-technology interaction evaluation on UI, understanding intuitiveness of a hardware model or software toolkit, etc. require an assessment of how much a particular task is generating mental workload on a user. This is necessary for understanding how those tasks, operations, and activities can be improvised and made better suited for the users so that they reduce the mental workload on the individual and the operators can use them with ease and less difficulty. However, a particular task can be gauged by a user as simple while for others it may be difficult. Understanding the complexity of a particular task can only be done on user level and we propose to do this by understanding the mental workload (MWL) generated on an operator while performing a task which requires processing a lot of information to get the task done. In this work, we have proposed an experimental setup which replicates modern day workload on doing regular day job tasks. We propose an approach to automatically evaluate the task complexity perceived by an individual by using electroencephalogram (EEG) data of a user during operation. Few crucial steps that are addressed in this work include extraction and optimization of different features and selection of relevant features for dimensionality reduction and using supervised machine learning techniques. In addition to this, performance results of the classifiers are compared using all features and also using only the selected features. From the results, it can be inferred that machine learning algorithms perform better as compared to traditional approaches for mental workload estimation.
On Optimizing Human-Machine Task Assignments
Sep 24, 2015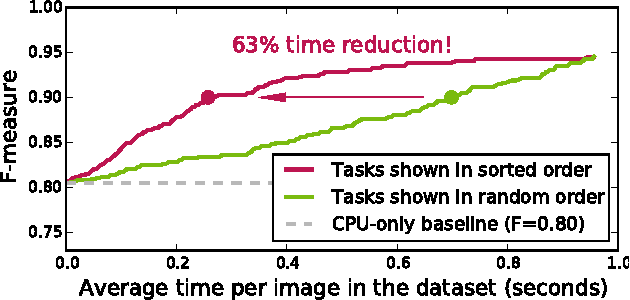
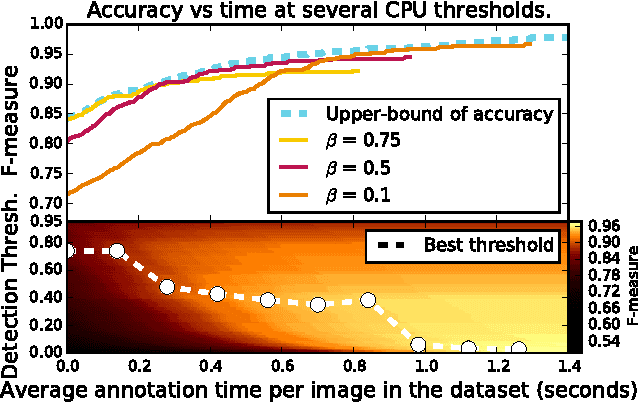
When crowdsourcing systems are used in combination with machine inference systems in the real world, they benefit the most when the machine system is deeply integrated with the crowd workers. However, if researchers wish to integrate the crowd with "off-the-shelf" machine classifiers, this deep integration is not always possible. This work explores two strategies to increase accuracy and decrease cost under this setting. First, we show that reordering tasks presented to the human can create a significant accuracy improvement. Further, we show that greedily choosing parameters to maximize machine accuracy is sub-optimal, and joint optimization of the combined system improves performance.