 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinically Calibrated Machine Learning Benchmarks for Large-Scale Multi-Disorder EEG Classification
Dec 27, 2025Clinical electroencephalography is routinely used to evaluate patients with diverse and often overlapping neurological conditions, yet interpretation remains manual, time-intensive, and variable across experts. While automated EEG analysis has been widely studied, most existing methods target isolated diagnostic problems, particularly seizure detection, and provide limited support for multi-disorder clinical screening. This study examines automated EEG-based classification across eleven clinically relevant neurological disorder categories, encompassing acute time-critical conditions, chronic neurocognitive and developmental disorders, and disorders with indirect or weak electrophysiological signatures. EEG recordings are processed using a standard longitudinal bipolar montage and represented through a multi-domain feature set capturing temporal statistics, spectral structure, signal complexity, and inter-channel relationships. Disorder-aware machine learning models are trained under severe class imbalance, with decision thresholds explicitly calibrated to prioritize diagnostic sensitivity. Evaluation on a large, heterogeneous clinical EEG dataset demonstrates that sensitivity-oriented modeling achieves recall exceeding 80% for the majority of disorder categories, with several low-prevalence conditions showing absolute recall gains of 15-30% after threshold calibration compared to default operating points. Feature importance analysis reveals physiologically plausible patterns consistent with established clinical EEG markers. These results establish realistic performance baselines for multi-disorder EEG classification and provide quantitative evidence that sensitivity-prioritized automated analysis can support scalable EEG screening and triage in real-world clinical settings.
G-MSGINet: A Grouped Multi-Scale Graph-Involution Network for Contactless Fingerprint Recognition
May 14, 2025This paper presents G-MSGINet, a unified and efficient framework for robust contactless fingerprint recognition that jointly performs minutiae localization and identity embedding directly from raw input images. Existing approaches rely on multi-branch architectures, orientation labels, or complex preprocessing steps, which limit scalability and generalization across real-world acquisition scenarios. In contrast, the proposed architecture introduces the GMSGI layer, a novel computational module that integrates grouped pixel-level involution, dynamic multi-scale kernel generation, and graph-based relational modelling into a single processing unit. Stacked GMSGI layers progressively refine both local minutiae-sensitive features and global topological representations through end-to-end optimization. The architecture eliminates explicit orientation supervision and adapts graph connectivity directly from learned kernel descriptors, thereby capturing meaningful structural relationships among fingerprint regions without fixed heuristics. Extensive experiments on three benchmark datasets, namely PolyU, CFPose, and Benchmark 2D/3D, demonstrate that G-MSGINet consistently achieves minutiae F1-scores in the range of $0.83\pm0.02$ and Rank-1 identification accuracies between 97.0% and 99.1%, while maintaining an Equal Error Rate (EER) as low as 0.5%. These results correspond to improvements of up to 4.8% in F1-score and 1.4% in Rank-1 accuracy when compared to prior methods, using only 0.38 million parameters and 6.63 giga floating-point operations, which represents up to ten times fewer parameters than competitive baselines. This highlights the scalability and effectiveness of G-MSGINet in real-world contactless biometric recognition scenarios.
Few-shot Pairwise Rank Prompting: An Effective Non-Parametric Retrieval Model
Sep 27, 2024A supervised ranking model, despite its advantage of being effective, usually involves complex processing - typically multiple stages of task-specific pre-training and fine-tuning. This has motivated researchers to explore simpler pipelines leveraging large language models (LLMs) that are capable of working in a zero-shot manner. However, since zero-shot inference does not make use of a training set of pairs of queries and their relevant documents, its performance is mostly worse than that of supervised models, which are trained on such example pairs. Motivated by the existing findings that training examples generally improve zero-shot performance, in our work, we explore if this also applies to ranking models. More specifically, given a query and a pair of documents, the preference prediction task is improved by augmenting examples of preferences for similar queries from a training set. Our proposed pairwise few-shot ranker demonstrates consistent improvements over the zero-shot baseline on both in-domain (TREC DL) and out-domain (BEIR subset) retrieval benchmarks. Our method also achieves a close performance to that of a supervised model without requiring any complex training pipeline.
DreamCatcher: Revealing the Language of the Brain with fMRI using GPT Embedding
Jun 16, 2023



The human brain possesses remarkable abilities in visual processing, including image recognition and scene summarization. Efforts have been made to understand the cognitive capacities of the visual brain, but a comprehensive understanding of the underlying mechanisms still needs to be discovered. Advancements in brain decoding techniques have led to sophisticated approaches like fMRI-to-Image reconstruction, which has implications for cognitive neuroscience and medical imaging. However, challenges persist in fMRI-to-image reconstruction, such as incorporating global context and contextual information. In this article, we propose fMRI captioning, where captions are generated based on fMRI data to gain insight into the neural correlates of visual perception. This research presents DreamCatcher, a novel framework for fMRI captioning. DreamCatcher consists of the Representation Space Encoder (RSE) and the RevEmbedding Decoder, which transform fMRI vectors into a latent space and generate captions, respectively. We evaluated the framework through visualization, dataset training, and testing on subjects, demonstrating strong performance. fMRI-based captioning has diverse applications, including understanding neural mechanisms, Human-Computer Interaction, and enhancing learning and training processes.
Modeling User Behaviour in Research Paper Recommendation System
Jul 16, 2021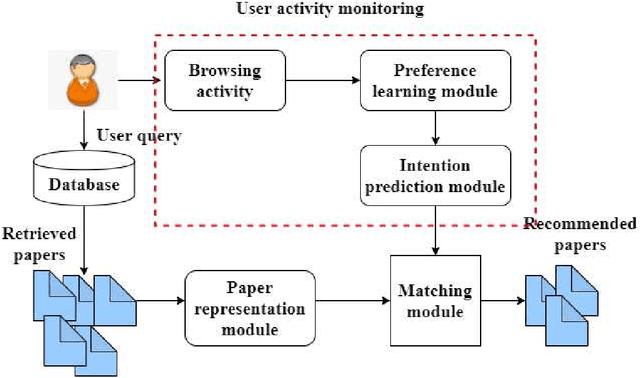


User intention which often changes dynamically is considered to be an important factor for modeling users in the design of recommendation systems. Recent studies are starting to focus on predicting user intention (what users want) beyond user preference (what users like). In this work, a user intention model is proposed based on deep sequential topic analysis. The model predicts a user's intention in terms of the topic of interest. The Hybrid Topic Model (HTM) comprising Latent Dirichlet Allocation (LDA) and Word2Vec is proposed to derive the topic of interest of users and the history of preferences. HTM finds the true topics of papers estimating word-topic distribution which includes syntactic and semantic correlations among words. Next, to model user intention, a Long Short Term Memory (LSTM) based sequential deep learning model is proposed. This model takes into account temporal context, namely the time difference between clicks of two consecutive papers seen by a user. Extensive experiments with the real-world research paper dataset indicate that the proposed approach significantly outperforms the state-of-the-art methods. Further, the proposed approach introduces a new road map to model a user activity suitable for the design of a research paper recommendation system.
Medical Information Retrieval and Interpretation: A Question-Answer based Interaction Model
Jan 24, 2021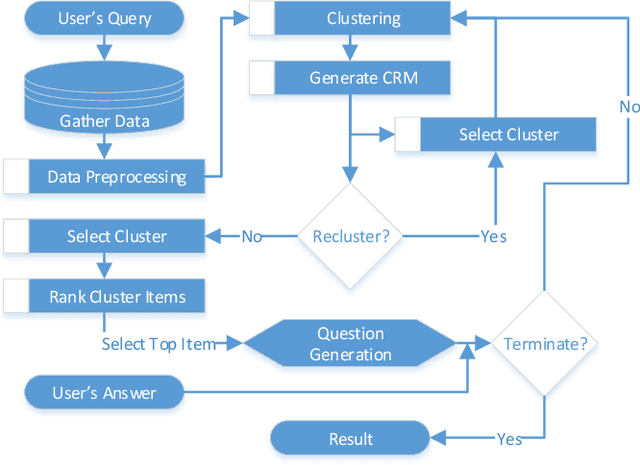
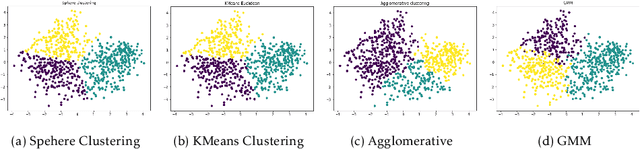
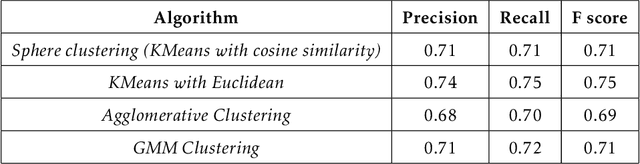
The Internet has become a very powerful platform where diverse medical information are expressed daily. Recently, a huge growth is seen in searches like symptoms, diseases, medicines, and many other health related queries around the globe. The search engines typically populate the result by using the single query provided by the user and hence reaching to the final result may require a lot of manual filtering from the user's end. Current search engines and recommendation systems still lack real time interactions that may provide more precise result generation. This paper proposes an intelligent and interactive system tied up with the vast medical big data repository on the web and illustrates its potential in finding medical information.
Computational Intelligence Approach to Improve the Classification Accuracy of Brain Neoplasm in MRI Data
Jan 24, 2021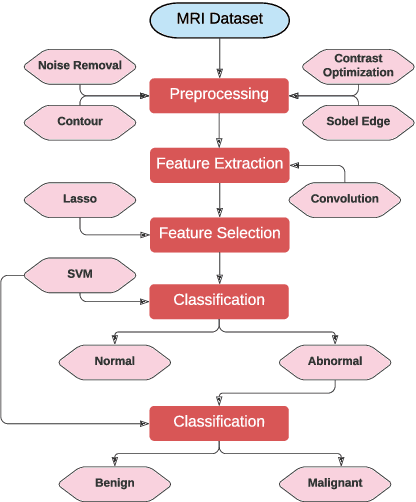
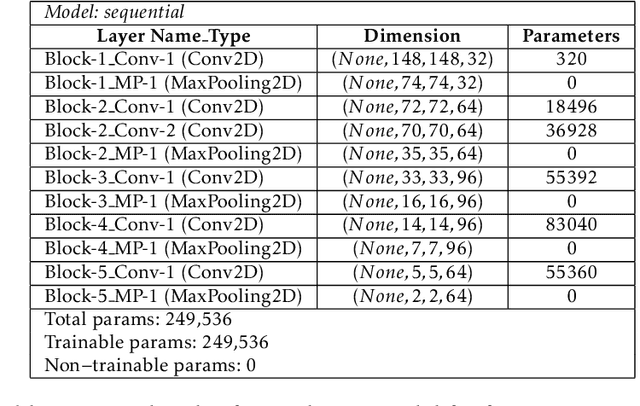
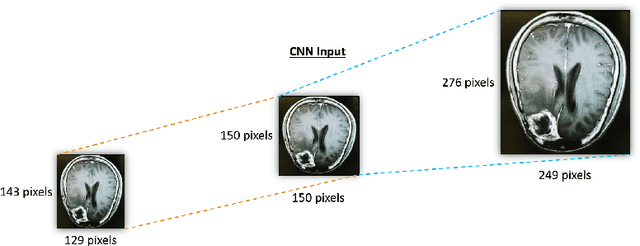
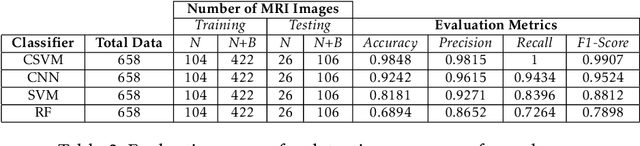
Automatic detection of brain neoplasm in Magnetic Resonance Imaging (MRI) is gaining importance in many medical diagnostic applications. This report presents two improvements for brain neoplasm detection in MRI data: an advanced preprocessing technique is proposed to improve the area of interest in MRI data and a hybrid technique using Convolutional Neural Network (CNN) for feature extraction followed by Support Vector Machine (SVM) for classification. The learning algorithm for SVM is modified with the addition of cost function to minimize false positive prediction addressing the errors in MRI data diagnosis. The proposed approach can effectively detect the presence of neoplasm and also predict whether it is cancerous (malignant) or non-cancerous (benign). To check the effectiveness of the proposed preprocessing technique, it is inspected visually and evaluated using training performance metrics. A comparison study between the proposed classification technique and the existing techniques was performed. The result showed that the proposed approach outperformed in terms of accuracy and can handle errors in classification better than the existing approaches.
An automated approach for task evaluation using EEG signals
Nov 14, 2019



Critical task and cognition-based environments, such as in military and defense operations, aviation user-technology interaction evaluation on UI, understanding intuitiveness of a hardware model or software toolkit, etc. require an assessment of how much a particular task is generating mental workload on a user. This is necessary for understanding how those tasks, operations, and activities can be improvised and made better suited for the users so that they reduce the mental workload on the individual and the operators can use them with ease and less difficulty. However, a particular task can be gauged by a user as simple while for others it may be difficult. Understanding the complexity of a particular task can only be done on user level and we propose to do this by understanding the mental workload (MWL) generated on an operator while performing a task which requires processing a lot of information to get the task done. In this work, we have proposed an experimental setup which replicates modern day workload on doing regular day job tasks. We propose an approach to automatically evaluate the task complexity perceived by an individual by using electroencephalogram (EEG) data of a user during operation. Few crucial steps that are addressed in this work include extraction and optimization of different features and selection of relevant features for dimensionality reduction and using supervised machine learning techniques. In addition to this, performance results of the classifiers are compared using all features and also using only the selected features. From the results, it can be inferred that machine learning algorithms perform better as compared to traditional approaches for mental workload estimation.
Stealing Neural Networks via Timing Side Channels
Dec 31, 2018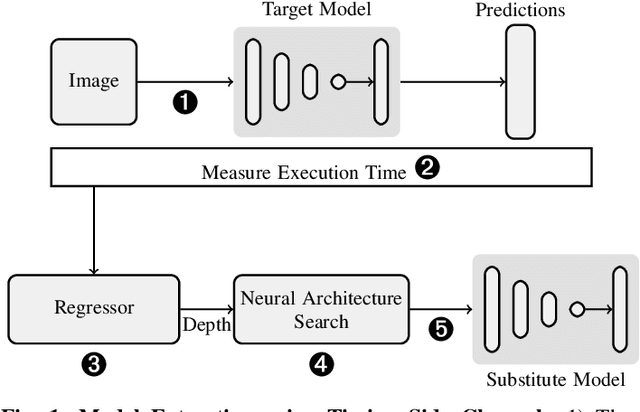
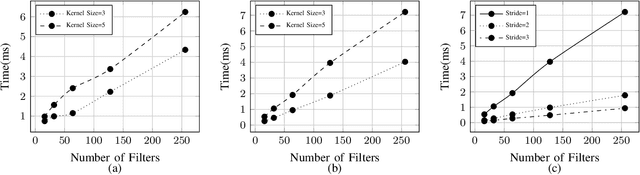
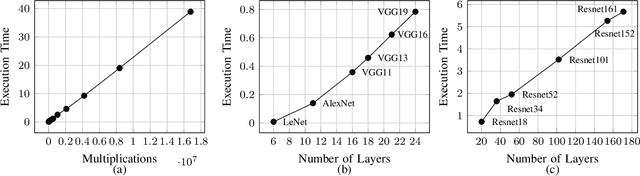
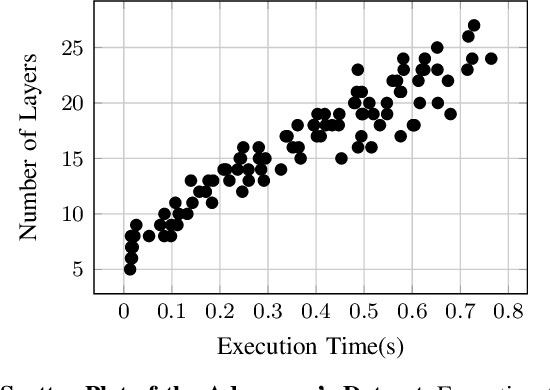
Deep learning is gaining importance in many applications and Cloud infrastructures are being advocated for this computational paradigm. However, there is a security issue which is yet to be addressed. An adversary can extract the neural network architecture for commercial gain. Given the architecture, an adversary can further infer the regularization hyperparameter, input data and generate effective transferable adversarial examples to evade classifiers. We observe that neural networks are vulnerable to timing side channel attacks as the total execution time of the network is dependent on the network depth due to the sequential computation of the layers. In this paper, black box neural network extraction attack by exploiting the timing side channels to infer the depth of the network has been proposed. The proposed approach is independent of the neural network architecture and scalable. Reconstructing substitute architectures with similar functionality as the target model is a search problem. The depth inferred from exploiting the timing side channel reduces the search space. Further, reinforcement learning with knowledge distillation is used to efficiently search for the optimal substitute architecture in the complex yet reduced search space. We evaluate our attack on VGG architectures on CIFAR10 dataset and reconstruct substitute models with test accuracy close to the target models.