 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Performance of Foundation Models via Agreement-on-the-Line
Apr 02, 2024



Estimating the out-of-distribution performance in regimes where labels are scarce is critical to safely deploy foundation models. Recently, it was shown that ensembles of neural networks observe the phenomena ``agreement-on-the-line'', which can be leveraged to reliably predict OOD performance without labels. However, in contrast to classical neural networks that are trained on in-distribution data from scratch for numerous epochs, foundation models undergo minimal finetuning from heavily pretrained weights, which may reduce the ensemble diversity needed to observe agreement-on-the-line. In our work, we demonstrate that when lightly finetuning multiple runs from a $\textit{single}$ foundation model, the choice of randomness during training (linear head initialization, data ordering, and data subsetting) can lead to drastically different levels of agreement-on-the-line in the resulting ensemble. Surprisingly, only random head initialization is able to reliably induce agreement-on-the-line in finetuned foundation models across vision and language benchmarks. Second, we demonstrate that ensembles of $\textit{multiple}$ foundation models pretrained on different datasets but finetuned on the same task can also show agreement-on-the-line. In total, by careful construction of a diverse ensemble, we can utilize agreement-on-the-line-based methods to predict the OOD performance of foundation models with high precision.
On Extending Amdahl's law to Learn Computer Performance
Oct 15, 2021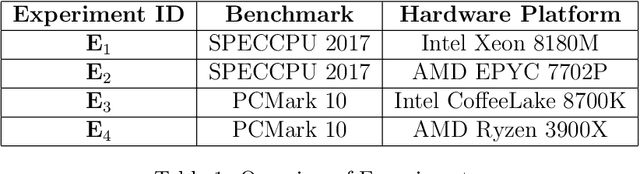


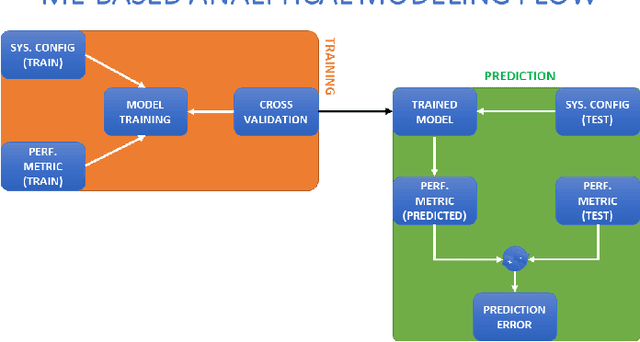
The problem of learning parallel computer performance is investigated in the context of multicore processors. Given a fixed workload, the effect of varying system configuration on performance is sought. Conventionally, the performance speedup due to a single resource enhancement is formulated using Amdahl's law. However, in case of multiple configurable resources the conventional formulation results in several disconnected speedup equations that cannot be combined together to determine the overall speedup. To solve this problem, we propose to (1) extend Amdahl's law to accommodate multiple configurable resources into the overall speedup equation, and (2) transform the speedup equation into a multivariable regression problem suitable for machine learning. Using experimental data from two benchmarks (SPECCPU 2017 and PCMark 10) and four hardware platforms (Intel Xeon 8180M, AMD EPYC 7702P, Intel CoffeeLake 8700K, and AMD Ryzen 3900X), analytical models are developed and cross-validated. Findings indicate that in most cases, the models result in an average cross-validated accuracy higher than 95%, thereby validating the proposed extension of Amdahl's law. The proposed methodology enables rapid generation of intelligent analytical models to support future industrial development, optimization, and simulation needs.
Medical Information Retrieval and Interpretation: A Question-Answer based Interaction Model
Jan 24, 2021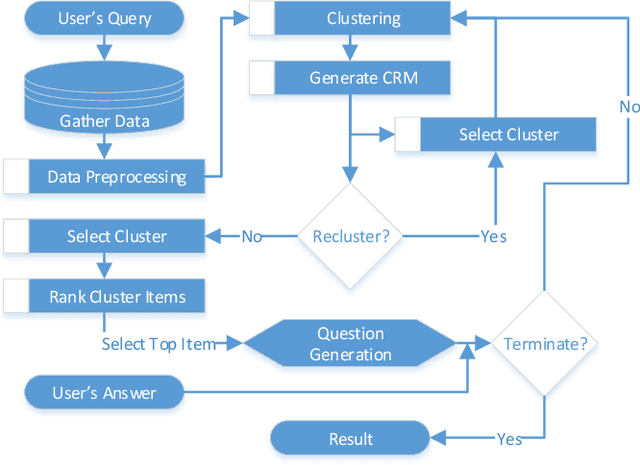
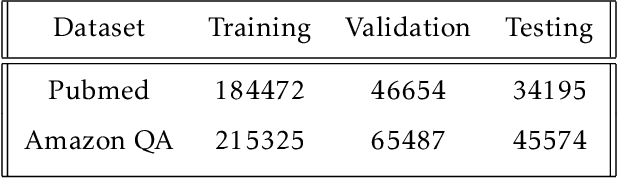
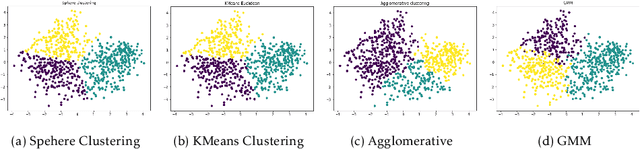
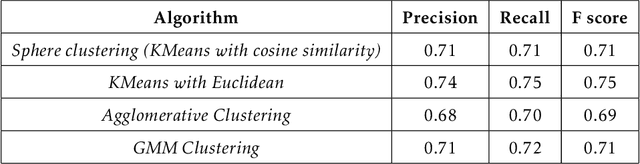
The Internet has become a very powerful platform where diverse medical information are expressed daily. Recently, a huge growth is seen in searches like symptoms, diseases, medicines, and many other health related queries around the globe. The search engines typically populate the result by using the single query provided by the user and hence reaching to the final result may require a lot of manual filtering from the user's end. Current search engines and recommendation systems still lack real time interactions that may provide more precise result generation. This paper proposes an intelligent and interactive system tied up with the vast medical big data repository on the web and illustrates its potential in finding medical information.