 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning as an Adaptive Defense for Safety
Jul 01, 2025



Reasoning methods that adaptively allocate test-time compute have advanced LLM performance on easy to verify domains such as math and code. In this work, we study how to utilize this approach to train models that exhibit a degree of robustness to safety vulnerabilities, and show that doing so can provide benefits. We build a recipe called $\textit{TARS}$ (Training Adaptive Reasoners for Safety), a reinforcement learning (RL) approach that trains models to reason about safety using chain-of-thought traces and a reward signal that balances safety with task completion. To build TARS, we identify three critical design choices: (1) a "lightweight" warmstart SFT stage, (2) a mix of harmful, harmless, and ambiguous prompts to prevent shortcut behaviors such as too many refusals, and (3) a reward function to prevent degeneration of reasoning capabilities during training. Models trained with TARS exhibit adaptive behaviors by spending more compute on ambiguous queries, leading to better safety-refusal trade-offs. They also internally learn to better distinguish between safe and unsafe prompts and attain greater robustness to both white-box (e.g., GCG) and black-box attacks (e.g., PAIR). Overall, our work provides an effective, open recipe for training LLMs against jailbreaks and harmful requests by reasoning per prompt.
Mitigating Bias in RAG: Controlling the Embedder
Feb 24, 2025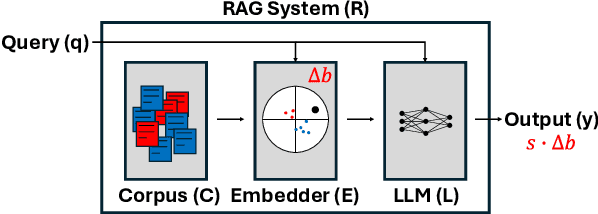


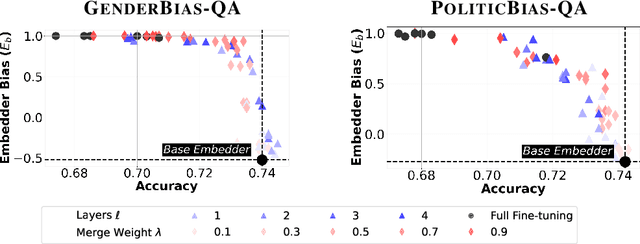
In retrieval augmented generation (RAG) systems, each individual component -- the LLM, embedder, and corpus -- could introduce biases in the form of skews towards outputting certain perspectives or identities. In this work, we study the conflict between biases of each component and their relationship to the overall bias of the RAG system, which we call bias conflict. Examining both gender and political biases as case studies, we show that bias conflict can be characterized through a linear relationship among components despite its complexity in 6 different LLMs. Through comprehensive fine-tuning experiments creating 120 differently biased embedders, we demonstrate how to control bias while maintaining utility and reveal the importance of reverse-biasing the embedder to mitigate bias in the overall system. Additionally, we find that LLMs and tasks exhibit varying sensitivities to the embedder bias, a crucial factor to consider for debiasing. Our results underscore that a fair RAG system can be better achieved by carefully controlling the bias of the embedder rather than increasing its fairness.
Predicting the Performance of Foundation Models via Agreement-on-the-Line
Apr 02, 2024



Estimating the out-of-distribution performance in regimes where labels are scarce is critical to safely deploy foundation models. Recently, it was shown that ensembles of neural networks observe the phenomena ``agreement-on-the-line'', which can be leveraged to reliably predict OOD performance without labels. However, in contrast to classical neural networks that are trained on in-distribution data from scratch for numerous epochs, foundation models undergo minimal finetuning from heavily pretrained weights, which may reduce the ensemble diversity needed to observe agreement-on-the-line. In our work, we demonstrate that when lightly finetuning multiple runs from a $\textit{single}$ foundation model, the choice of randomness during training (linear head initialization, data ordering, and data subsetting) can lead to drastically different levels of agreement-on-the-line in the resulting ensemble. Surprisingly, only random head initialization is able to reliably induce agreement-on-the-line in finetuned foundation models across vision and language benchmarks. Second, we demonstrate that ensembles of $\textit{multiple}$ foundation models pretrained on different datasets but finetuned on the same task can also show agreement-on-the-line. In total, by careful construction of a diverse ensemble, we can utilize agreement-on-the-line-based methods to predict the OOD performance of foundation models with high precision.
Heuristic Algorithm-based Action Masking Reinforcement Learning (HAAM-RL) with Ensemble Inference Method
Mar 21, 2024This paper presents a novel reinforcement learning (RL) approach called HAAM-RL (Heuristic Algorithm-based Action Masking Reinforcement Learning) for optimizing the color batching re-sequencing problem in automobile painting processes. The existing heuristic algorithms have limitations in adequately reflecting real-world constraints and accurately predicting logistics performance. Our methodology incorporates several key techniques including a tailored Markov Decision Process (MDP) formulation, reward setting including Potential-Based Reward Shaping, action masking using heuristic algorithms (HAAM-RL), and an ensemble inference method that combines multiple RL models. The RL agent is trained and evaluated using FlexSim, a commercial 3D simulation software, integrated with our RL MLOps platform BakingSoDA. Experimental results across 30 scenarios demonstrate that HAAM-RL with an ensemble inference method achieves a 16.25% performance improvement over the conventional heuristic algorithm, with stable and consistent results. The proposed approach exhibits superior performance and generalization capability, indicating its effectiveness in optimizing complex manufacturing processes. The study also discusses future research directions, including alternative state representations, incorporating model-based RL methods, and integrating additional real-world constraints.
Jailbreaking is Best Solved by Definition
Mar 20, 2024



The rise of "jailbreak" attacks on language models has led to a flurry of defenses aimed at preventing the output of undesirable responses. In this work, we critically examine the two stages of the defense pipeline: (i) the definition of what constitutes unsafe outputs, and (ii) the enforcement of the definition via methods such as input processing or fine-tuning. We cast severe doubt on the efficacy of existing enforcement mechanisms by showing that they fail to defend even for a simple definition of unsafe outputs--outputs that contain the word "purple". In contrast, post-processing outputs is perfectly robust for such a definition. Drawing on our results, we present our position that the real challenge in defending jailbreaks lies in obtaining a good definition of unsafe responses: without a good definition, no enforcement strategy can succeed, but with a good definition, output processing already serves as a robust baseline albeit with inference-time overheads.
Toward Reinforcement Learning-based Rectilinear Macro Placement Under Human Constraints
Nov 03, 2023Macro placement is a critical phase in chip design, which becomes more intricate when involving general rectilinear macros and layout areas. Furthermore, macro placement that incorporates human-like constraints, such as design hierarchy and peripheral bias, has the potential to significantly reduce the amount of additional manual labor required from designers. This study proposes a methodology that leverages an approach suggested by Google's Circuit Training (G-CT) to provide a learning-based macro placer that not only supports placing rectilinear cases, but also adheres to crucial human-like design principles. Our experimental results demonstrate the effectiveness of our framework in achieving power-performance-area (PPA) metrics and in obtaining placements of high quality, comparable to those produced with human intervention. Additionally, our methodology shows potential as a generalized model to address diverse macro shapes and layout areas.