 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Mixed Training: Scaling Parametric Knowledge Acquisition Beyond RAG
Mar 24, 2026Synthetic data augmentation helps language models learn new knowledge in data-constrained domains. However, naively scaling existing synthetic data methods by training on more synthetic tokens or using stronger generators yields diminishing returns below the performance of RAG. To break the RAG ceiling, we introduce Synthetic Mixed Training, which combines synthetic QAs and synthetic documents. This leverages their complementary training signals, and enables log-linear improvements as both synthetic data volume and generator strength increase. This allows the model to outperform RAG by a 2.6\% relative gain on QuaLITY, a long-document reading comprehension benchmark. In addition, we introduce Focal Rewriting, a simple technique for synthetic document generation that explicitly conditions document generation on specific questions, improving the diversity of synthetic documents and yielding a steeper log-linear scaling curve. On QuaLITY, our final recipe trains a Llama 8B model that outperforms RAG by 4.4\% relatively. Across models and benchmarks (QuaLITY, LongHealth, FinanceBench), our training enables models to beat RAG in five of six settings, outperforms by 2.6\%, and achieves a 9.1\% gain when combined with RAG.
Data-efficient pre-training by scaling synthetic megadocs
Mar 19, 2026Synthetic data augmentation has emerged as a promising solution when pre-training is constrained by data rather than compute. We study how to design synthetic data algorithms that achieve better loss scaling: not only lowering loss at finite compute but especially as compute approaches infinity. We first show that pre-training on web data mixed with synthetically generated rephrases improves i.i.d. validation loss on the web data, despite the synthetic data coming from an entirely different distribution. With optimal mixing and epoching, loss and benchmark accuracy improve without overfitting as the number of synthetic generations grows, plateauing near $1.48\times$ data efficiency at 32 rephrases per document. We find even better loss scaling under a new perspective: synthetic generations from the same document can form a single substantially longer megadocument instead of many short documents. We show two ways to construct megadocs: stitching synthetic rephrases from the same web document or stretching a document by inserting rationales. Both methods improve i.i.d. loss, downstream benchmarks, and especially long-context loss relative to simple rephrasing, increasing data efficiency from $1.48\times$ to $1.80\times$ at $32$ generations per document. Importantly, the improvement of megadocs over simple rephrasing widens as more synthetic data is generated. Our results show how to design synthetic data algorithms that benefit more from increasing compute when data-constrained.
Replaying pre-training data improves fine-tuning
Mar 05, 2026To obtain a language model for a target domain (e.g. math), the current paradigm is to pre-train on a vast amount of generic web text and then fine-tune on the relatively limited amount of target data. Typically, generic data is only mixed in during fine-tuning to prevent catastrophic forgetting of the generic domain. We surprisingly find that replaying the generic data during fine-tuning can actually improve performance on the (less related) target task. Concretely, in a controlled pre-training environment with 4M target tokens, 4B total tokens, and 150M parameter models, generic replay increases target data efficiency by up to $1.87\times$ for fine-tuning and $2.06\times$ for mid-training. We further analyze data schedules that introduce target data during pre-training and find that replay helps more when there is less target data present in pre-training. We demonstrate the success of replay in practice for fine-tuning 8B parameter models, improving agentic web navigation success by $4.5\%$ and Basque question-answering accuracy by $2\%$.
Pre-training under infinite compute
Sep 18, 2025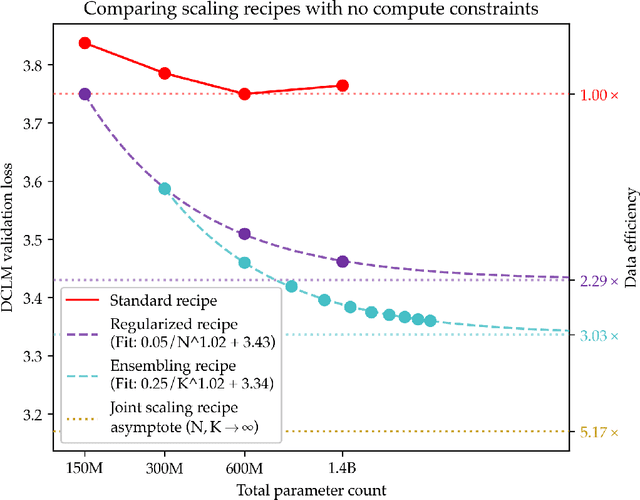

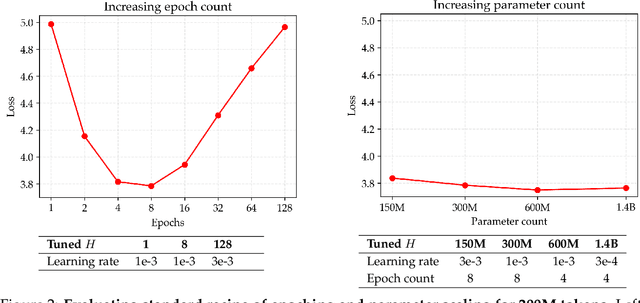
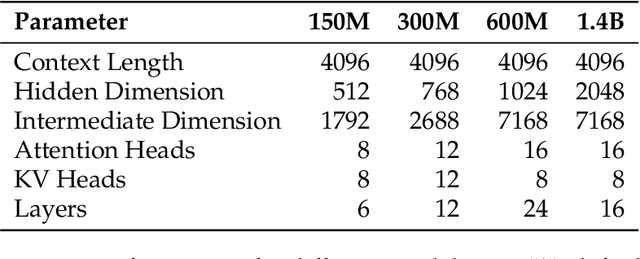
Since compute grows much faster than web text available for language model pre-training, we ask how one should approach pre-training under fixed data and no compute constraints. We first show that existing data-constrained approaches of increasing epoch count and parameter count eventually overfit, and we significantly improve upon such recipes by properly tuning regularization, finding that the optimal weight decay is $30\times$ larger than standard practice. Since our regularized recipe monotonically decreases loss following a simple power law in parameter count, we estimate its best possible performance via the asymptote of its scaling law rather than the performance at a fixed compute budget. We then identify that ensembling independently trained models achieves a significantly lower loss asymptote than the regularized recipe. Our best intervention combining epoching, regularization, parameter scaling, and ensemble scaling achieves an asymptote at 200M tokens using $5.17\times$ less data than our baseline, and our data scaling laws predict that this improvement persists at higher token budgets. We find that our data efficiency gains can be realized at much smaller parameter counts as we can distill an ensemble into a student model that is 8$\times$ smaller and retains $83\%$ of the ensembling benefit. Finally, our interventions designed for validation loss generalize to downstream benchmarks, achieving a $9\%$ improvement for pre-training evals and a $17.5\times$ data efficiency improvement over continued pre-training on math mid-training data. Our results show that simple algorithmic improvements can enable significantly more data-efficient pre-training in a compute-rich future.
Jailbreaking is Best Solved by Definition
Mar 20, 2024



The rise of "jailbreak" attacks on language models has led to a flurry of defenses aimed at preventing the output of undesirable responses. In this work, we critically examine the two stages of the defense pipeline: (i) the definition of what constitutes unsafe outputs, and (ii) the enforcement of the definition via methods such as input processing or fine-tuning. We cast severe doubt on the efficacy of existing enforcement mechanisms by showing that they fail to defend even for a simple definition of unsafe outputs--outputs that contain the word "purple". In contrast, post-processing outputs is perfectly robust for such a definition. Drawing on our results, we present our position that the real challenge in defending jailbreaks lies in obtaining a good definition of unsafe responses: without a good definition, no enforcement strategy can succeed, but with a good definition, output processing already serves as a robust baseline albeit with inference-time overheads.
A Safe Harbor for AI Evaluation and Red Teaming
Mar 07, 2024



Independent evaluation and red teaming are critical for identifying the risks posed by generative AI systems. However, the terms of service and enforcement strategies used by prominent AI companies to deter model misuse have disincentives on good faith safety evaluations. This causes some researchers to fear that conducting such research or releasing their findings will result in account suspensions or legal reprisal. Although some companies offer researcher access programs, they are an inadequate substitute for independent research access, as they have limited community representation, receive inadequate funding, and lack independence from corporate incentives. We propose that major AI developers commit to providing a legal and technical safe harbor, indemnifying public interest safety research and protecting it from the threat of account suspensions or legal reprisal. These proposals emerged from our collective experience conducting safety, privacy, and trustworthiness research on generative AI systems, where norms and incentives could be better aligned with public interests, without exacerbating model misuse. We believe these commitments are a necessary step towards more inclusive and unimpeded community efforts to tackle the risks of generative AI.
Repetition Improves Language Model Embeddings
Feb 23, 2024



Recent approaches to improving the extraction of text embeddings from autoregressive large language models (LLMs) have largely focused on improvements to data, backbone pretrained language models, or improving task-differentiation via instructions. In this work, we address an architectural limitation of autoregressive models: token embeddings cannot contain information from tokens that appear later in the input. To address this limitation, we propose a simple approach, "echo embeddings," in which we repeat the input twice in context and extract embeddings from the second occurrence. We show that echo embeddings of early tokens can encode information about later tokens, allowing us to maximally leverage high-quality LLMs for embeddings. On the MTEB leaderboard, echo embeddings improve over classical embeddings by over 9% zero-shot and by around 0.7% when fine-tuned. Echo embeddings with a Mistral-7B model achieve state-of-the-art compared to prior open source models that do not leverage synthetic fine-tuning data.
Understanding Catastrophic Forgetting in Language Models via Implicit Inference
Sep 18, 2023



Fine-tuning (via methods such as instruction-tuning or reinforcement learning from human feedback) is a crucial step in training language models to robustly carry out tasks of interest. However, we lack a systematic understanding of the effects of fine-tuning, particularly on tasks outside the narrow fine-tuning distribution. In a simplified scenario, we demonstrate that improving performance on tasks within the fine-tuning data distribution comes at the expense of suppressing model capabilities on other tasks. This degradation is especially pronounced for tasks "closest" to the fine-tuning distribution. We hypothesize that language models implicitly infer the task of the prompt corresponds, and the fine-tuning process predominantly skews this task inference towards tasks in the fine-tuning distribution. To test this hypothesis, we propose Conjugate Prompting to see if we can recover pretrained capabilities. Conjugate prompting artificially makes the task look farther from the fine-tuning distribution while requiring the same capability. We find that conjugate prompting systematically recovers some of the pretraining capabilities on our synthetic setup. We then apply conjugate prompting to real-world LLMs using the observation that fine-tuning distributions are typically heavily skewed towards English. We find that simply translating the prompts to different languages can cause the fine-tuned models to respond like their pretrained counterparts instead. This allows us to recover the in-context learning abilities lost via instruction tuning, and more concerningly, to recover harmful content generation suppressed by safety fine-tuning in chatbots like ChatGPT.
Provably Bounding Neural Network Preimages
Feb 07, 2023Most work on the formal verification of neural networks has focused on bounding forward images of neural networks, i.e., the set of outputs of a neural network that correspond to a given set of inputs (for example, bounded perturbations of a nominal input). However, many use cases of neural network verification require solving the inverse problem, i.e, over-approximating the set of inputs that lead to certain outputs. In this work, we present the first efficient bound propagation algorithm, INVPROP, for verifying properties over the preimage of a linearly constrained output set of a neural network, which can be combined with branch-and-bound to achieve completeness. Our efficient algorithm allows multiple passes of intermediate bound refinements, which are crucial for tight inverse verification because the bounds of an intermediate layer depend on relaxations both before and after this layer. We demonstrate our algorithm on applications related to quantifying safe control regions for a dynamical system and detecting out-of-distribution inputs to a neural network. Our results show that in certain settings, we can find over-approximations that are over 2500 times tighter than prior work while being 2.5 times faster on the same hardware.
CELESTIAL: Classification Enabled via Labelless Embeddings with Self-supervised Telescope Image Analysis Learning
Jan 20, 2022

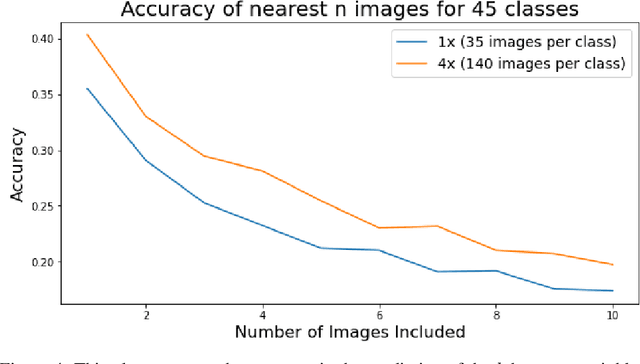
A common class of problems in remote sensing is scene classification, a fundamentally important task for natural hazards identification, geographic image retrieval, and environment monitoring. Recent developments in this field rely label-dependent supervised learning techniques which is antithetical to the 35 petabytes of unlabelled satellite imagery in NASA GIBS. To solve this problem, we establish CELESTIAL-a self-supervised learning pipeline for effectively leveraging sparsely-labeled satellite imagery. This pipeline successfully adapts SimCLR, an algorithm that first learns image representations on unlabelled data and then fine-tunes this knowledge on the provided labels. Our results show CELESTIAL requires only a third of the labels that the supervised method needs to attain the same accuracy on an experimental dataset. The first unsupervised tier can enable applications such as reverse image search for NASA Worldview (i.e. searching similar atmospheric phenomenon over years of unlabelled data with minimal samples) and the second supervised tier can lower the necessity of expensive data annotation significantly. In the future, we hope we can generalize the CELESTIAL pipeline to other data types, algorithms, and applications.