 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelated Noise Mechanisms for Differentially Private Learning
Jun 09, 2025
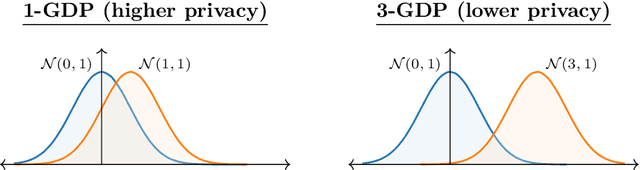

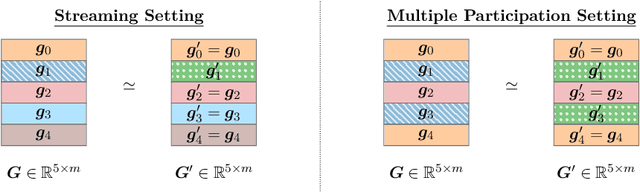
This monograph explores the design and analysis of correlated noise mechanisms for differential privacy (DP), focusing on their application to private training of AI and machine learning models via the core primitive of estimation of weighted prefix sums. While typical DP mechanisms inject independent noise into each step of a stochastic gradient (SGD) learning algorithm in order to protect the privacy of the training data, a growing body of recent research demonstrates that introducing (anti-)correlations in the noise can significantly improve privacy-utility trade-offs by carefully canceling out some of the noise added on earlier steps in subsequent steps. Such correlated noise mechanisms, known variously as matrix mechanisms, factorization mechanisms, and DP-Follow-the-Regularized-Leader (DP-FTRL) when applied to learning algorithms, have also been influential in practice, with industrial deployment at a global scale.
Norm-Bounded Low-Rank Adaptation
Jan 31, 2025



In this work, we propose norm-bounded low-rank adaptation (NB-LoRA) for parameter-efficient fine tuning. We introduce two parameterizations that allow explicit bounds on each singular value of the weight adaptation matrix, which can therefore satisfy any prescribed unitarily invariant norm bound, including the Schatten norms (e.g., nuclear, Frobenius, spectral norm). The proposed parameterizations are unconstrained and complete, i.e. they cover all matrices satisfying the prescribed rank and norm constraints. Experiments on vision fine-tuning benchmarks show that the proposed approach can achieve good adaptation performance while avoiding model catastrophic forgetting and also substantially improve robustness to a wide range of hyper-parameters, including adaptation rank, learning rate and number of training epochs. We also explore applications in privacy-preserving model merging and low-rank matrix completion.
Achieving the Tightest Relaxation of Sigmoids for Formal Verification
Aug 22, 2024



In the field of formal verification, Neural Networks (NNs) are typically reformulated into equivalent mathematical programs which are optimized over. To overcome the inherent non-convexity of these reformulations, convex relaxations of nonlinear activation functions are typically utilized. Common relaxations (i.e., static linear cuts) of "S-shaped" activation functions, however, can be overly loose, slowing down the overall verification process. In this paper, we derive tuneable hyperplanes which upper and lower bound the sigmoid activation function. When tuned in the dual space, these affine bounds smoothly rotate around the nonlinear manifold of the sigmoid activation function. This approach, termed $\alpha$-sig, allows us to tractably incorporate the tightest possible, element-wise convex relaxation of the sigmoid activation function into a formal verification framework. We embed these relaxations inside of large verification tasks and compare their performance to LiRPA and $\alpha$-CROWN, a state-of-the-art verification duo.
Verified Neural Compressed Sensing
May 08, 2024



We develop the first (to the best of our knowledge) provably correct neural networks for a precise computational task, with the proof of correctness generated by an automated verification algorithm without any human input. Prior work on neural network verification has focused on partial specifications that, even when satisfied, are not sufficient to ensure that a neural network never makes errors. We focus on applying neural network verification to computational tasks with a precise notion of correctness, where a verifiably correct neural network provably solves the task at hand with no caveats. In particular, we develop an approach to train and verify the first provably correct neural networks for compressed sensing, i.e., recovering sparse vectors from a number of measurements smaller than the dimension of the vector. We show that for modest problem dimensions (up to 50), we can train neural networks that provably recover a sparse vector from linear and binarized linear measurements. Furthermore, we show that the complexity of the network (number of neurons/layers) can be adapted to the problem difficulty and solve problems where traditional compressed sensing methods are not known to provably work.
Efficient and Near-Optimal Noise Generation for Streaming Differential Privacy
Apr 26, 2024In the task of differentially private (DP) continual counting, we receive a stream of increments and our goal is to output an approximate running total of these increments, without revealing too much about any specific increment. Despite its simplicity, differentially private continual counting has attracted significant attention both in theory and in practice. Existing algorithms for differentially private continual counting are either inefficient in terms of their space usage or add an excessive amount of noise, inducing suboptimal utility. The most practical DP continual counting algorithms add carefully correlated Gaussian noise to the values. The task of choosing the covariance for this noise can be expressed in terms of factoring the lower-triangular matrix of ones (which computes prefix sums). We present two approaches from this class (for different parameter regimes) that achieve near-optimal utility for DP continual counting and only require logarithmic or polylogarithmic space (and time). Our first approach is based on a space-efficient streaming matrix multiplication algorithm for a class of Toeplitz matrices. We show that to instantiate this algorithm for DP continual counting, it is sufficient to find a low-degree rational function that approximates the square root on a circle in the complex plane. We then apply and extend tools from approximation theory to achieve this. We also derive efficient closed-forms for the objective function for arbitrarily many steps, and show direct numerical optimization yields a highly practical solution to the problem. Our second approach combines our first approach with a recursive construction similar to the binary tree mechanism.
Confidence-aware Reward Optimization for Fine-tuning Text-to-Image Models
Apr 02, 2024



Fine-tuning text-to-image models with reward functions trained on human feedback data has proven effective for aligning model behavior with human intent. However, excessive optimization with such reward models, which serve as mere proxy objectives, can compromise the performance of fine-tuned models, a phenomenon known as reward overoptimization. To investigate this issue in depth, we introduce the Text-Image Alignment Assessment (TIA2) benchmark, which comprises a diverse collection of text prompts, images, and human annotations. Our evaluation of several state-of-the-art reward models on this benchmark reveals their frequent misalignment with human assessment. We empirically demonstrate that overoptimization occurs notably when a poorly aligned reward model is used as the fine-tuning objective. To address this, we propose TextNorm, a simple method that enhances alignment based on a measure of reward model confidence estimated across a set of semantically contrastive text prompts. We demonstrate that incorporating the confidence-calibrated rewards in fine-tuning effectively reduces overoptimization, resulting in twice as many wins in human evaluation for text-image alignment compared against the baseline reward models.
Understanding Subjectivity through the Lens of Motivational Context in Model-Generated Image Satisfaction
Feb 27, 2024



Image generation models are poised to become ubiquitous in a range of applications. These models are often fine-tuned and evaluated using human quality judgments that assume a universal standard, failing to consider the subjectivity of such tasks. To investigate how to quantify subjectivity, and the scale of its impact, we measure how assessments differ among human annotators across different use cases. Simulating the effects of ordinarily latent elements of annotators subjectivity, we contrive a set of motivations (t-shirt graphics, presentation visuals, and phone background images) to contextualize a set of crowdsourcing tasks. Our results show that human evaluations of images vary within individual contexts and across combinations of contexts. Three key factors affecting this subjectivity are image appearance, image alignment with text, and representation of objects mentioned in the text. Our study highlights the importance of taking individual users and contexts into account, both when building and evaluating generative models
Private Gradient Descent for Linear Regression: Tighter Error Bounds and Instance-Specific Uncertainty Estimation
Feb 21, 2024We provide an improved analysis of standard differentially private gradient descent for linear regression under the squared error loss. Under modest assumptions on the input, we characterize the distribution of the iterate at each time step. Our analysis leads to new results on the algorithm's accuracy: for a proper fixed choice of hyperparameters, the sample complexity depends only linearly on the dimension of the data. This matches the dimension-dependence of the (non-private) ordinary least squares estimator as well as that of recent private algorithms that rely on sophisticated adaptive gradient-clipping schemes (Varshney et al., 2022; Liu et al., 2023). Our analysis of the iterates' distribution also allows us to construct confidence intervals for the empirical optimizer which adapt automatically to the variance of the algorithm on a particular data set. We validate our theorems through experiments on synthetic data.
Monotone, Bi-Lipschitz, and Polyak-Lojasiewicz Networks
Feb 08, 2024



This paper presents a new \emph{bi-Lipschitz} invertible neural network, the BiLipNet, which has the ability to control both its \emph{Lipschitzness} (output sensitivity to input perturbations) and \emph{inverse Lipschitzness} (input distinguishability from different outputs). The main contribution is a novel invertible residual layer with certified strong monotonicity and Lipschitzness, which we compose with orthogonal layers to build bi-Lipschitz networks. The certification is based on incremental quadratic constraints, which achieves much tighter bounds compared to spectral normalization. Moreover, we formulate the model inverse calculation as a three-operator splitting problem, for which fast algorithms are known. Based on the proposed bi-Lipschitz network, we introduce a new scalar-output network, the PLNet, which satisfies the Polyak-\L{}ojasiewicz condition. It can be applied to learn non-convex surrogate losses with favourable properties, e.g., a unique and efficiently-computable global minimum.
MINT: A wrapper to make multi-modal and multi-image AI models interactive
Jan 22, 2024During the diagnostic process, doctors incorporate multimodal information including imaging and the medical history - and similarly medical AI development has increasingly become multimodal. In this paper we tackle a more subtle challenge: doctors take a targeted medical history to obtain only the most pertinent pieces of information; how do we enable AI to do the same? We develop a wrapper method named MINT (Make your model INTeractive) that automatically determines what pieces of information are most valuable at each step, and ask for only the most useful information. We demonstrate the efficacy of MINT wrapping a skin disease prediction model, where multiple images and a set of optional answers to $25$ standard metadata questions (i.e., structured medical history) are used by a multi-modal deep network to provide a differential diagnosis. We show that MINT can identify whether metadata inputs are needed and if so, which question to ask next. We also demonstrate that when collecting multiple images, MINT can identify if an additional image would be beneficial, and if so, which type of image to capture. We showed that MINT reduces the number of metadata and image inputs needed by 82% and 36.2% respectively, while maintaining predictive performance. Using real-world AI dermatology system data, we show that needing fewer inputs can retain users that may otherwise fail to complete the system submission and drop off without a diagnosis. Qualitative examples show MINT can closely mimic the step-by-step decision making process of a clinical workflow and how this is different for straight forward cases versus more difficult, ambiguous cases. Finally we demonstrate how MINT is robust to different underlying multi-model classifiers and can be easily adapted to user requirements without significant model re-training.