 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Subjectivity through the Lens of Motivational Context in Model-Generated Image Satisfaction
Feb 27, 2024



Image generation models are poised to become ubiquitous in a range of applications. These models are often fine-tuned and evaluated using human quality judgments that assume a universal standard, failing to consider the subjectivity of such tasks. To investigate how to quantify subjectivity, and the scale of its impact, we measure how assessments differ among human annotators across different use cases. Simulating the effects of ordinarily latent elements of annotators subjectivity, we contrive a set of motivations (t-shirt graphics, presentation visuals, and phone background images) to contextualize a set of crowdsourcing tasks. Our results show that human evaluations of images vary within individual contexts and across combinations of contexts. Three key factors affecting this subjectivity are image appearance, image alignment with text, and representation of objects mentioned in the text. Our study highlights the importance of taking individual users and contexts into account, both when building and evaluating generative models
Modeling subjectivity (by Mimicking Annotator Annotation) in toxic comment identification across diverse communities
Nov 01, 2023The prevalence and impact of toxic discussions online have made content moderation crucial.Automated systems can play a vital role in identifying toxicity, and reducing the reliance on human moderation.Nevertheless, identifying toxic comments for diverse communities continues to present challenges that are addressed in this paper.The two-part goal of this study is to(1)identify intuitive variances from annotator disagreement using quantitative analysis and (2)model the subjectivity of these viewpoints.To achieve our goal, we published a new dataset\footnote{\url{https://github.com/XXX}} with expert annotators' annotations and used two other public datasets to identify the subjectivity of toxicity.Then leveraging the Large Language Model(LLM),we evaluate the model's ability to mimic diverse viewpoints on toxicity by varying size of the training data and utilizing same set of annotators as the test set used during model training and a separate set of annotators as the test set.We conclude that subjectivity is evident across all annotator groups, demonstrating the shortcomings of majority-rule voting. Moving forward, subjective annotations should serve as ground truth labels for training models for domains like toxicity in diverse communities.
LaMDA: Language Models for Dialog Applications
Feb 10, 2022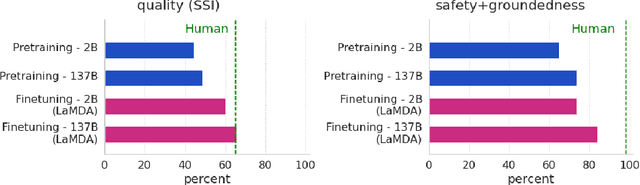
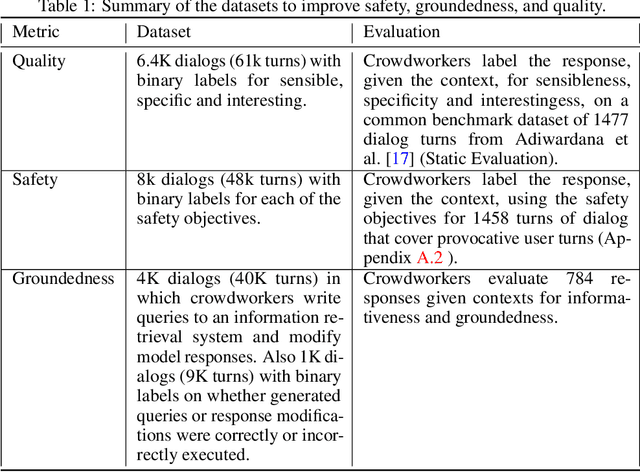
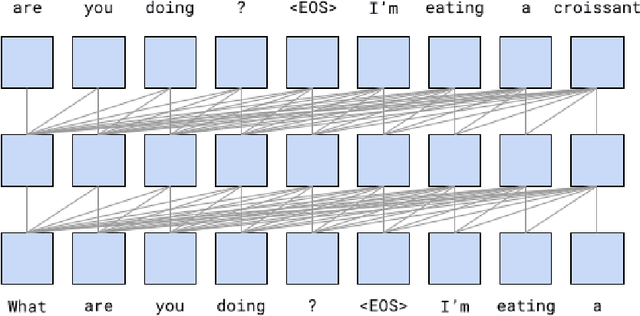

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.