 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Thumbs Up/Down: Untangling Challenges of Fine-Grained Feedback for Text-to-Image Generation
Jun 24, 2024Human feedback plays a critical role in learning and refining reward models for text-to-image generation, but the optimal form the feedback should take for learning an accurate reward function has not been conclusively established. This paper investigates the effectiveness of fine-grained feedback which captures nuanced distinctions in image quality and prompt-alignment, compared to traditional coarse-grained feedback (for example, thumbs up/down or ranking between a set of options). While fine-grained feedback holds promise, particularly for systems catering to diverse societal preferences, we show that demonstrating its superiority to coarse-grained feedback is not automatic. Through experiments on real and synthetic preference data, we surface the complexities of building effective models due to the interplay of model choice, feedback type, and the alignment between human judgment and computational interpretation. We identify key challenges in eliciting and utilizing fine-grained feedback, prompting a reassessment of its assumed benefits and practicality. Our findings -- e.g., that fine-grained feedback can lead to worse models for a fixed budget, in some settings; however, in controlled settings with known attributes, fine grained rewards can indeed be more helpful -- call for careful consideration of feedback attributes and potentially beckon novel modeling approaches to appropriately unlock the potential value of fine-grained feedback in-the-wild.
A Design Space for Intelligent and Interactive Writing Assistants
Mar 26, 2024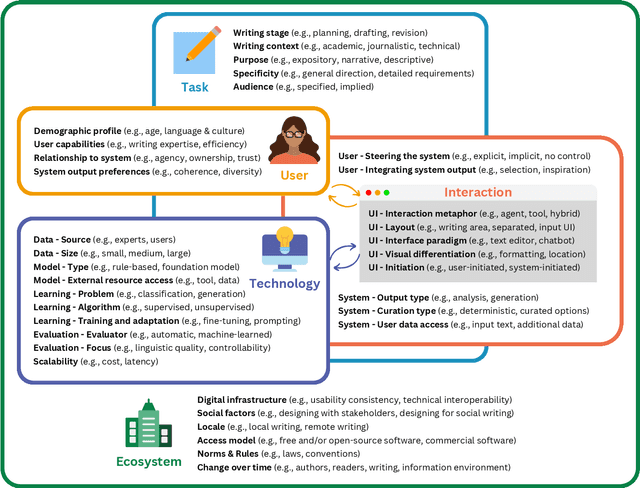
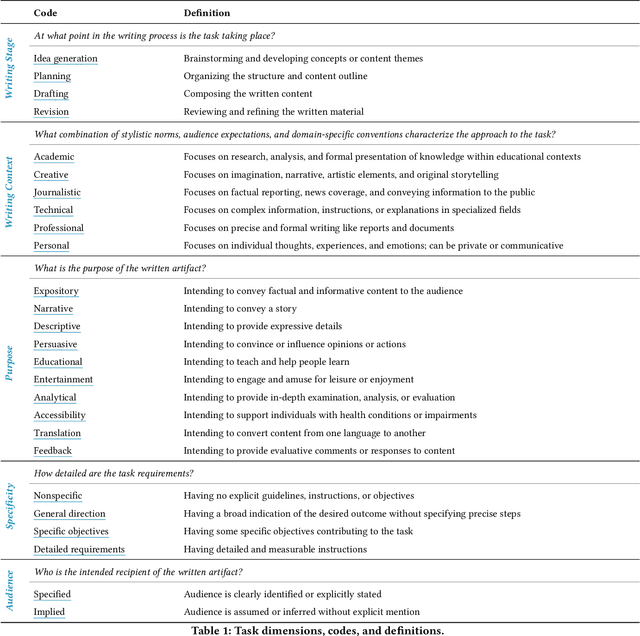
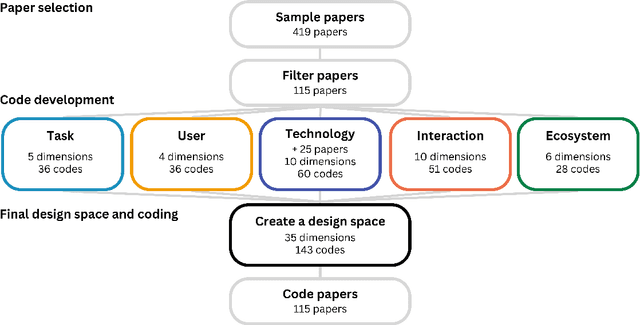
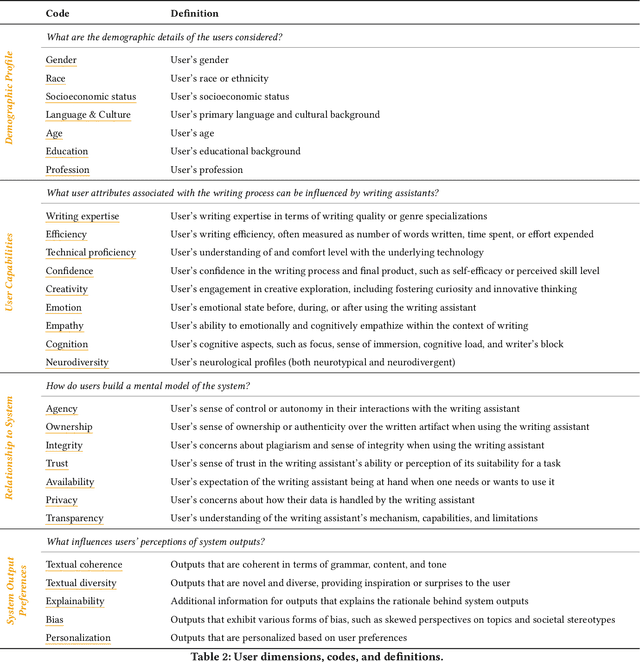
In our era of rapid technological advancement, the research landscape for writing assistants has become increasingly fragmented across various research communities. We seek to address this challenge by proposing a design space as a structured way to examine and explore the multidimensional space of intelligent and interactive writing assistants. Through a large community collaboration, we explore five aspects of writing assistants: task, user, technology, interaction, and ecosystem. Within each aspect, we define dimensions (i.e., fundamental components of an aspect) and codes (i.e., potential options for each dimension) by systematically reviewing 115 papers. Our design space aims to offer researchers and designers a practical tool to navigate, comprehend, and compare the various possibilities of writing assistants, and aid in the envisioning and design of new writing assistants.
Understanding Subjectivity through the Lens of Motivational Context in Model-Generated Image Satisfaction
Feb 27, 2024



Image generation models are poised to become ubiquitous in a range of applications. These models are often fine-tuned and evaluated using human quality judgments that assume a universal standard, failing to consider the subjectivity of such tasks. To investigate how to quantify subjectivity, and the scale of its impact, we measure how assessments differ among human annotators across different use cases. Simulating the effects of ordinarily latent elements of annotators subjectivity, we contrive a set of motivations (t-shirt graphics, presentation visuals, and phone background images) to contextualize a set of crowdsourcing tasks. Our results show that human evaluations of images vary within individual contexts and across combinations of contexts. Three key factors affecting this subjectivity are image appearance, image alignment with text, and representation of objects mentioned in the text. Our study highlights the importance of taking individual users and contexts into account, both when building and evaluating generative models
Getting aligned on representational alignment
Nov 02, 2023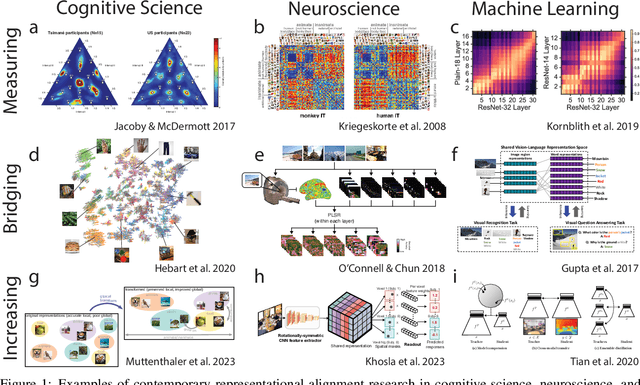
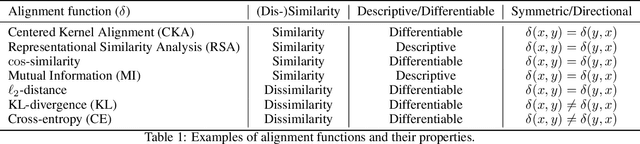
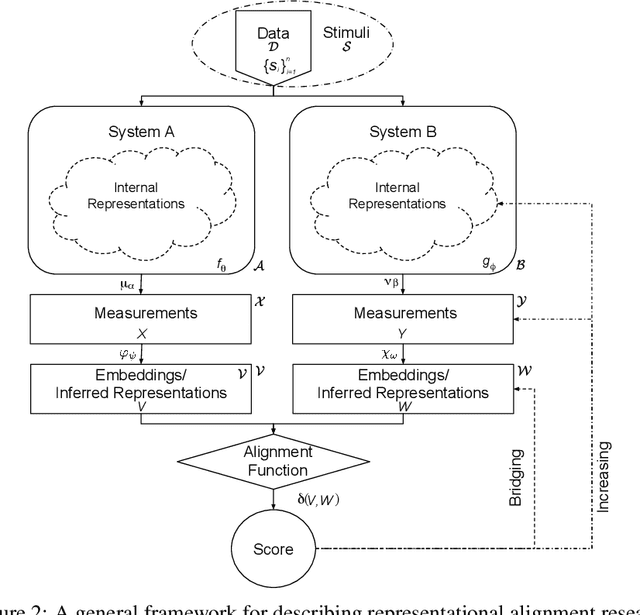
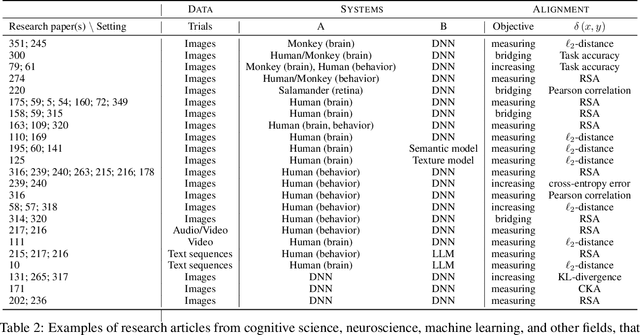
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
Modeling subjectivity (by Mimicking Annotator Annotation) in toxic comment identification across diverse communities
Nov 01, 2023The prevalence and impact of toxic discussions online have made content moderation crucial.Automated systems can play a vital role in identifying toxicity, and reducing the reliance on human moderation.Nevertheless, identifying toxic comments for diverse communities continues to present challenges that are addressed in this paper.The two-part goal of this study is to(1)identify intuitive variances from annotator disagreement using quantitative analysis and (2)model the subjectivity of these viewpoints.To achieve our goal, we published a new dataset\footnote{\url{https://github.com/XXX}} with expert annotators' annotations and used two other public datasets to identify the subjectivity of toxicity.Then leveraging the Large Language Model(LLM),we evaluate the model's ability to mimic diverse viewpoints on toxicity by varying size of the training data and utilizing same set of annotators as the test set used during model training and a separate set of annotators as the test set.We conclude that subjectivity is evident across all annotator groups, demonstrating the shortcomings of majority-rule voting. Moving forward, subjective annotations should serve as ground truth labels for training models for domains like toxicity in diverse communities.
Leveraging Contextual Counterfactuals Toward Belief Calibration
Jul 13, 2023Beliefs and values are increasingly being incorporated into our AI systems through alignment processes, such as carefully curating data collection principles or regularizing the loss function used for training. However, the meta-alignment problem is that these human beliefs are diverse and not aligned across populations; furthermore, the implicit strength of each belief may not be well calibrated even among humans, especially when trying to generalize across contexts. Specifically, in high regret situations, we observe that contextual counterfactuals and recourse costs are particularly important in updating a decision maker's beliefs and the strengths to which such beliefs are held. Therefore, we argue that including counterfactuals is key to an accurate calibration of beliefs during alignment. To do this, we first segment belief diversity into two categories: subjectivity (across individuals within a population) and epistemic uncertainty (within an individual across different contexts). By leveraging our notion of epistemic uncertainty, we introduce `the belief calibration cycle' framework to more holistically calibrate this diversity of beliefs with context-driven counterfactual reasoning by using a multi-objective optimization. We empirically apply our framework for finding a Pareto frontier of clustered optimal belief strengths that generalize across different contexts, demonstrating its efficacy on a toy dataset for credit decisions.