 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnder the Influence: Quantifying Persuasion and Vigilance in Large Language Models
Feb 26, 2026With increasing integration of Large Language Models (LLMs) into areas of high-stakes human decision-making, it is important to understand the risks they introduce as advisors. To be useful advisors, LLMs must sift through large amounts of content, written with both benevolent and malicious intent, and then use this information to convince a user to take a specific action. This involves two social capacities: vigilance (the ability to determine which information to use, and which to discard) and persuasion (synthesizing the available evidence to make a convincing argument). While existing work has investigated these capacities in isolation, there has been little prior investigation of how these capacities may be linked. Here, we use a simple multi-turn puzzle-solving game, Sokoban, to study LLMs' abilities to persuade and be rationally vigilant towards other LLM agents. We find that puzzle-solving performance, persuasive capability, and vigilance are dissociable capacities in LLMs. Performing well on the game does not automatically mean a model can detect when it is being misled, even if the possibility of deception is explicitly mentioned. However, LLMs do consistently modulate their token use, using fewer tokens to reason when advice is benevolent and more when it is malicious, even if they are still persuaded to take actions leading them to failure. To our knowledge, our work presents the first investigation of the relationship between persuasion, vigilance, and task performance in LLMs, and suggests that monitoring all three independently will be critical for future work in AI safety.
Why Human Guidance Matters in Collaborative Vibe Coding
Feb 11, 2026Writing code has been one of the most transformative ways for human societies to translate abstract ideas into tangible technologies. Modern AI is transforming this process by enabling experts and non-experts alike to generate code without actually writing code, but instead, through natural language instructions, or "vibe coding". While increasingly popular, the cumulative impact of vibe coding on productivity and collaboration, as well as the role of humans in this process, remains unclear. Here, we introduce a controlled experimental framework for studying collaborative vibe coding and use it to compare human-led, AI-led, and hybrid groups. Across 16 experiments involving 604 human participants, we show that people provide uniquely effective high-level instructions for vibe coding across iterations, whereas AI-provided instructions often result in performance collapse. We further demonstrate that hybrid systems perform best when humans retain directional control (providing the instructions), while evaluation is delegated to AI.
Identifying, Evaluating, and Mitigating Risks of AI Thought Partnerships
May 22, 2025Artificial Intelligence (AI) systems have historically been used as tools that execute narrowly defined tasks. Yet recent advances in AI have unlocked possibilities for a new class of models that genuinely collaborate with humans in complex reasoning, from conceptualizing problems to brainstorming solutions. Such AI thought partners enable novel forms of collaboration and extended cognition, yet they also pose major risks-including and beyond risks of typical AI tools and agents. In this commentary, we systematically identify risks of AI thought partners through a novel framework that identifies risks at multiple levels of analysis, including Real-time, Individual, and Societal risks arising from collaborative cognition (RISc). We leverage this framework to propose concrete metrics for risk evaluation, and finally suggest specific mitigation strategies for developers and policymakers. As AI thought partners continue to proliferate, these strategies can help prevent major harms and ensure that humans actively benefit from productive thought partnerships.
Using the Tools of Cognitive Science to Understand Large Language Models at Different Levels of Analysis
Mar 17, 2025Modern artificial intelligence systems, such as large language models, are increasingly powerful but also increasingly hard to understand. Recognizing this problem as analogous to the historical difficulties in understanding the human mind, we argue that methods developed in cognitive science can be useful for understanding large language models. We propose a framework for applying these methods based on Marr's three levels of analysis. By revisiting established cognitive science techniques relevant to each level and illustrating their potential to yield insights into the behavior and internal organization of large language models, we aim to provide a toolkit for making sense of these new kinds of minds.
When Should We Orchestrate Multiple Agents?
Mar 17, 2025Strategies for orchestrating the interactions between multiple agents, both human and artificial, can wildly overestimate performance and underestimate the cost of orchestration. We design a framework to orchestrate agents under realistic conditions, such as inference costs or availability constraints. We show theoretically that orchestration is only effective if there are performance or cost differentials between agents. We then empirically demonstrate how orchestration between multiple agents can be helpful for selecting agents in a simulated environment, picking a learning strategy in the infamous Rogers' Paradox from social science, and outsourcing tasks to other agents during a question-answer task in a user study.
On Benchmarking Human-Like Intelligence in Machines
Feb 27, 2025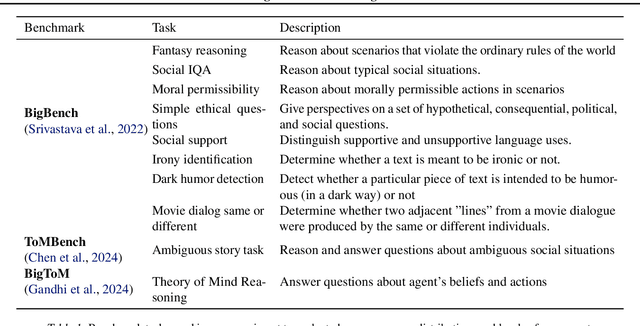
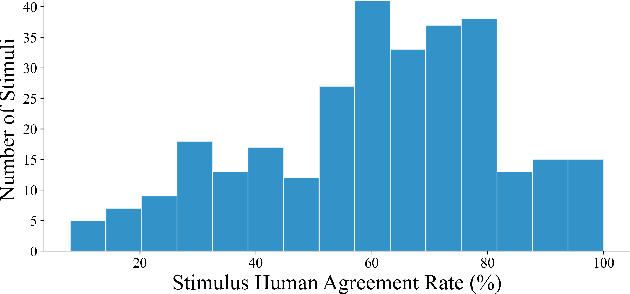
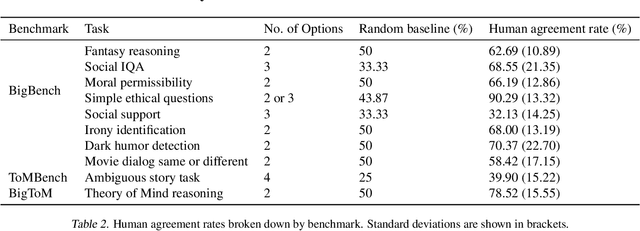
Recent benchmark studies have claimed that AI has approached or even surpassed human-level performances on various cognitive tasks. However, this position paper argues that current AI evaluation paradigms are insufficient for assessing human-like cognitive capabilities. We identify a set of key shortcomings: a lack of human-validated labels, inadequate representation of human response variability and uncertainty, and reliance on simplified and ecologically-invalid tasks. We support our claims by conducting a human evaluation study on ten existing AI benchmarks, suggesting significant biases and flaws in task and label designs. To address these limitations, we propose five concrete recommendations for developing future benchmarks that will enable more rigorous and meaningful evaluations of human-like cognitive capacities in AI with various implications for such AI applications.
What is a Number, That a Large Language Model May Know It?
Feb 03, 2025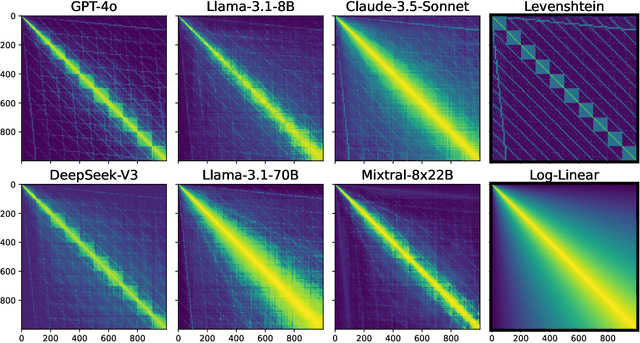

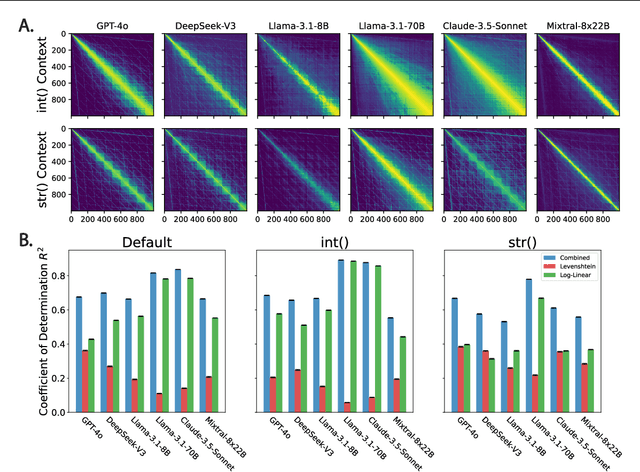

Numbers are a basic part of how humans represent and describe the world around them. As a consequence, learning effective representations of numbers is critical for the success of large language models as they become more integrated into everyday decisions. However, these models face a challenge: depending on context, the same sequence of digit tokens, e.g., 911, can be treated as a number or as a string. What kind of representations arise from this duality, and what are its downstream implications? Using a similarity-based prompting technique from cognitive science, we show that LLMs learn representational spaces that blend string-like and numerical representations. In particular, we show that elicited similarity judgments from these models over integer pairs can be captured by a combination of Levenshtein edit distance and numerical Log-Linear distance, suggesting an entangled representation. In a series of experiments we show how this entanglement is reflected in the latent embeddings, how it can be reduced but not entirely eliminated by context, and how it can propagate into a realistic decision scenario. These results shed light on a representational tension in transformer models that must learn what a number is from text input.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Quantifying Knowledge Distillation Using Partial Information Decomposition
Nov 12, 2024



Knowledge distillation provides an effective method for deploying complex machine learning models in resource-constrained environments. It typically involves training a smaller student model to emulate either the probabilistic outputs or the internal feature representations of a larger teacher model. By doing so, the student model often achieves substantially better performance on a downstream task compared to when it is trained independently. Nevertheless, the teacher's internal representations can also encode noise or additional information that may not be relevant to the downstream task. This observation motivates our primary question: What are the information-theoretic limits of knowledge transfer? To this end, we leverage a body of work in information theory called Partial Information Decomposition (PID) to quantify the distillable and distilled knowledge of a teacher's representation corresponding to a given student and a downstream task. Moreover, we demonstrate that this metric can be practically used in distillation to address challenges caused by the complexity gap between the teacher and the student representations.
Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse
Oct 27, 2024Chain-of-thought (CoT) prompting has become a widely used strategy for working with large language and multimodal models. While CoT has been shown to improve performance across many tasks, determining the settings in which it is effective remains an ongoing effort. In particular, it is still an open question in what settings CoT systematically reduces model performance. In this paper, we seek to identify the characteristics of tasks where CoT reduces performance by drawing inspiration from cognitive psychology, looking at cases where (i) verbal thinking or deliberation hurts performance in humans, and (ii) the constraints governing human performance generalize to language models. Three such cases are implicit statistical learning, visual recognition, and classifying with patterns containing exceptions. In extensive experiments across all three settings, we find that a diverse collection of state-of-the-art models exhibit significant drop-offs in performance (e.g., up to 36.3% absolute accuracy for OpenAI o1-preview compared to GPT-4o) when using inference-time reasoning compared to zero-shot counterparts. We also identify three tasks that satisfy condition (i) but not (ii), and find that while verbal thinking reduces human performance in these tasks, CoT retains or increases model performance. Overall, our results show that while there is not an exact parallel between the cognitive processes of models and those of humans, considering cases where thinking has negative consequences for human performance can help us identify settings where it negatively impacts models. By connecting the literature on human deliberation with evaluations of CoT, we offer a new tool that can be used in understanding the impact of prompt choices and inference-time reasoning.