 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProToM: Promoting Prosocial Behaviour via Theory of Mind-Informed Feedback
Sep 05, 2025



While humans are inherently social creatures, the challenge of identifying when and how to assist and collaborate with others - particularly when pursuing independent goals - can hinder cooperation. To address this challenge, we aim to develop an AI system that provides useful feedback to promote prosocial behaviour - actions that benefit others, even when not directly aligned with one's own goals. We introduce ProToM, a Theory of Mind-informed facilitator that promotes prosocial actions in multi-agent systems by providing targeted, context-sensitive feedback to individual agents. ProToM first infers agents' goals using Bayesian inverse planning, then selects feedback to communicate by maximising expected utility, conditioned on the inferred goal distribution. We evaluate our approach against baselines in two multi-agent environments: Doors, Keys, and Gems, as well as Overcooked. Our results suggest that state-of-the-art large language and reasoning models fall short of communicating feedback that is both contextually grounded and well-timed - leading to higher communication overhead and task speedup. In contrast, ProToM provides targeted and helpful feedback, achieving a higher success rate, shorter task completion times, and is consistently preferred by human users.
What's in the Box? Reasoning about Unseen Objects from Multimodal Cues
Jun 17, 2025People regularly make inferences about objects in the world that they cannot see by flexibly integrating information from multiple sources: auditory and visual cues, language, and our prior beliefs and knowledge about the scene. How are we able to so flexibly integrate many sources of information to make sense of the world around us, even if we have no direct knowledge? In this work, we propose a neurosymbolic model that uses neural networks to parse open-ended multimodal inputs and then applies a Bayesian model to integrate different sources of information to evaluate different hypotheses. We evaluate our model with a novel object guessing game called ``What's in the Box?'' where humans and models watch a video clip of an experimenter shaking boxes and then try to guess the objects inside the boxes. Through a human experiment, we show that our model correlates strongly with human judgments, whereas unimodal ablated models and large multimodal neural model baselines show poor correlation.
Belief Attribution as Mental Explanation: The Role of Accuracy, Informativity, and Causality
May 26, 2025A key feature of human theory-of-mind is the ability to attribute beliefs to other agents as mentalistic explanations for their behavior. But given the wide variety of beliefs that agents may hold about the world and the rich language we can use to express them, which specific beliefs are people inclined to attribute to others? In this paper, we investigate the hypothesis that people prefer to attribute beliefs that are good explanations for the behavior they observe. We develop a computational model that quantifies the explanatory strength of a (natural language) statement about an agent's beliefs via three factors: accuracy, informativity, and causal relevance to actions, each of which can be computed from a probabilistic generative model of belief-driven behavior. Using this model, we study the role of each factor in how people selectively attribute beliefs to other agents. We investigate this via an experiment where participants watch an agent collect keys hidden in boxes in order to reach a goal, then rank a set of statements describing the agent's beliefs about the boxes' contents. We find that accuracy and informativity perform reasonably well at predicting these rankings when combined, but that causal relevance is the single factor that best explains participants' responses.
On Benchmarking Human-Like Intelligence in Machines
Feb 27, 2025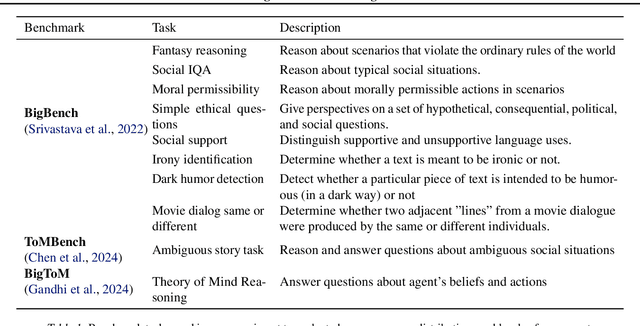
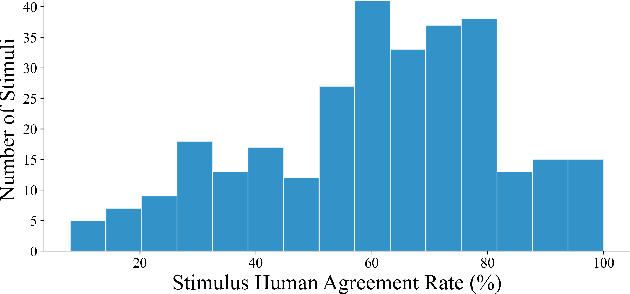
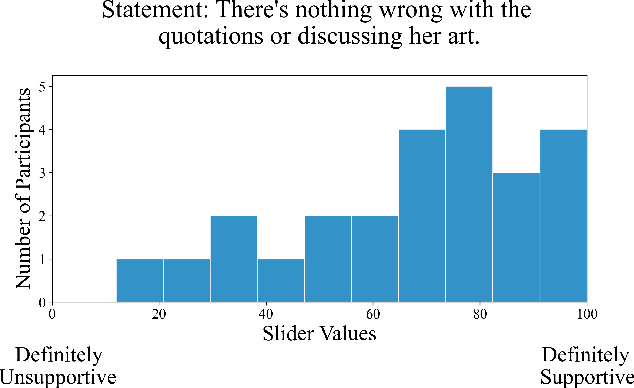
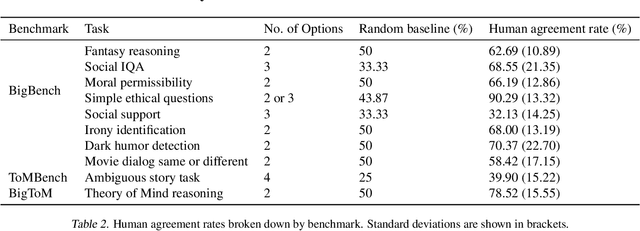
Recent benchmark studies have claimed that AI has approached or even surpassed human-level performances on various cognitive tasks. However, this position paper argues that current AI evaluation paradigms are insufficient for assessing human-like cognitive capabilities. We identify a set of key shortcomings: a lack of human-validated labels, inadequate representation of human response variability and uncertainty, and reliance on simplified and ecologically-invalid tasks. We support our claims by conducting a human evaluation study on ten existing AI benchmarks, suggesting significant biases and flaws in task and label designs. To address these limitations, we propose five concrete recommendations for developing future benchmarks that will enable more rigorous and meaningful evaluations of human-like cognitive capacities in AI with various implications for such AI applications.
Hypothesis-Driven Theory-of-Mind Reasoning for Large Language Models
Feb 17, 2025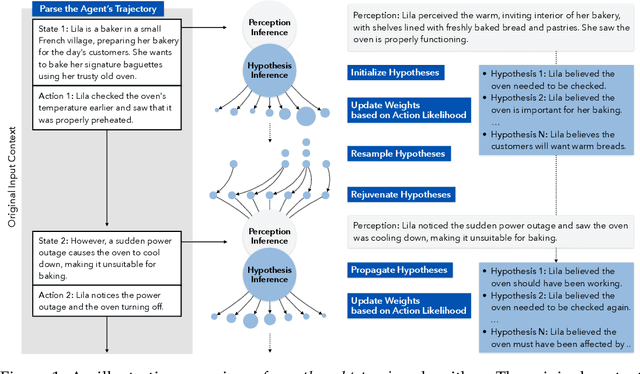

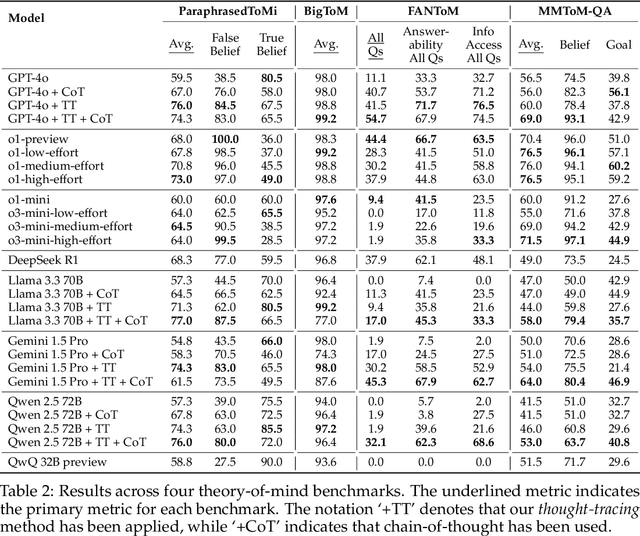
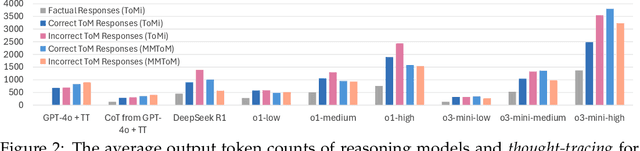
Existing LLM reasoning methods have shown impressive capabilities across various tasks, such as solving math and coding problems. However, applying these methods to scenarios without ground-truth answers or rule-based verification methods - such as tracking the mental states of an agent - remains challenging. Inspired by the sequential Monte Carlo algorithm, we introduce thought-tracing, an inference-time reasoning algorithm designed to trace the mental states of specific agents by generating hypotheses and weighting them based on observations without relying on ground-truth solutions to questions in datasets. Our algorithm is modeled after the Bayesian theory-of-mind framework, using LLMs to approximate probabilistic inference over agents' evolving mental states based on their perceptions and actions. We evaluate thought-tracing on diverse theory-of-mind benchmarks, demonstrating significant performance improvements compared to baseline LLMs. Our experiments also reveal interesting behaviors of the recent reasoning models - e.g., o1 and R1 - on theory-of-mind, highlighting the difference of social reasoning compared to other domains.
SIFToM: Robust Spoken Instruction Following through Theory of Mind
Sep 17, 2024



Spoken language instructions are ubiquitous in agent collaboration. However, in human-robot collaboration, recognition accuracy for human speech is often influenced by various speech and environmental factors, such as background noise, the speaker's accents, and mispronunciation. When faced with noisy or unfamiliar auditory inputs, humans use context and prior knowledge to disambiguate the stimulus and take pragmatic actions, a process referred to as top-down processing in cognitive science. We present a cognitively inspired model, Speech Instruction Following through Theory of Mind (SIFToM), to enable robots to pragmatically follow human instructions under diverse speech conditions by inferring the human's goal and joint plan as prior for speech perception and understanding. We test SIFToM in simulated home experiments (VirtualHome 2). Results show that the SIFToM model outperforms state-of-the-art speech and language models, approaching human-level accuracy on challenging speech instruction following tasks. We then demonstrate its ability at the task planning level on a mobile manipulator for breakfast preparation tasks.
Understanding Epistemic Language with a Bayesian Theory of Mind
Aug 21, 2024


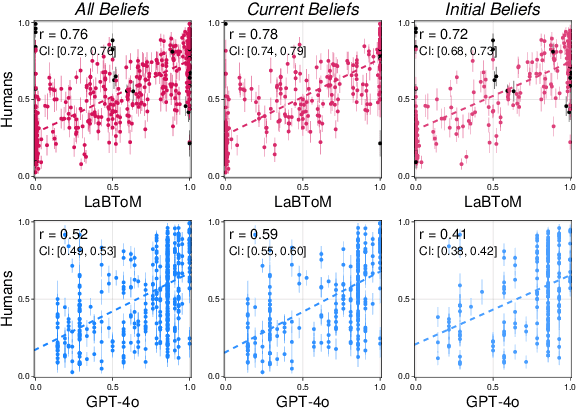
How do people understand and evaluate claims about others' beliefs, even though these beliefs cannot be directly observed? In this paper, we introduce a cognitive model of epistemic language interpretation, grounded in Bayesian inferences about other agents' goals, beliefs, and intentions: a language-augmented Bayesian theory-of-mind (LaBToM). By translating natural language into an epistemic ``language-of-thought'', then evaluating these translations against the inferences produced by inverting a probabilistic generative model of rational action and perception, LaBToM captures graded plausibility judgments about epistemic claims. We validate our model in an experiment where participants watch an agent navigate a maze to find keys hidden in boxes needed to reach their goal, then rate sentences about the agent's beliefs. In contrast with multimodal LLMs (GPT-4o, Gemini Pro) and ablated models, our model correlates highly with human judgments for a wide range of expressions, including modal language, uncertainty expressions, knowledge claims, likelihood comparisons, and attributions of false belief.
GOMA: Proactive Embodied Cooperative Communication via Goal-Oriented Mental Alignment
Mar 17, 2024



Verbal communication plays a crucial role in human cooperation, particularly when the partners only have incomplete information about the task, environment, and each other's mental state. In this paper, we propose a novel cooperative communication framework, Goal-Oriented Mental Alignment (GOMA). GOMA formulates verbal communication as a planning problem that minimizes the misalignment between the parts of agents' mental states that are relevant to the goals. This approach enables an embodied assistant to reason about when and how to proactively initialize communication with humans verbally using natural language to help achieve better cooperation. We evaluate our approach against strong baselines in two challenging environments, Overcooked (a multiplayer game) and VirtualHome (a household simulator). Our experimental results demonstrate that large language models struggle with generating meaningful communication that is grounded in the social and physical context. In contrast, our approach can successfully generate concise verbal communication for the embodied assistant to effectively boost the performance of the cooperation as well as human users' perception of the assistant.
Pragmatic Instruction Following and Goal Assistance via Cooperative Language-Guided Inverse Planning
Feb 27, 2024People often give instructions whose meaning is ambiguous without further context, expecting that their actions or goals will disambiguate their intentions. How can we build assistive agents that follow such instructions in a flexible, context-sensitive manner? This paper introduces cooperative language-guided inverse plan search (CLIPS), a Bayesian agent architecture for pragmatic instruction following and goal assistance. Our agent assists a human by modeling them as a cooperative planner who communicates joint plans to the assistant, then performs multimodal Bayesian inference over the human's goal from actions and language, using large language models (LLMs) to evaluate the likelihood of an instruction given a hypothesized plan. Given this posterior, our assistant acts to minimize expected goal achievement cost, enabling it to pragmatically follow ambiguous instructions and provide effective assistance even when uncertain about the goal. We evaluate these capabilities in two cooperative planning domains (Doors, Keys & Gems and VirtualHome), finding that CLIPS significantly outperforms GPT-4V, LLM-based literal instruction following and unimodal inverse planning in both accuracy and helpfulness, while closely matching the inferences and assistive judgments provided by human raters.
Grounding Language about Belief in a Bayesian Theory-of-Mind
Feb 16, 2024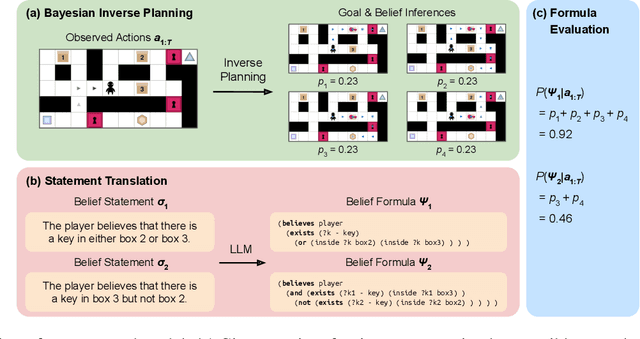


Despite the fact that beliefs are mental states that cannot be directly observed, humans talk about each others' beliefs on a regular basis, often using rich compositional language to describe what others think and know. What explains this capacity to interpret the hidden epistemic content of other minds? In this paper, we take a step towards an answer by grounding the semantics of belief statements in a Bayesian theory-of-mind: By modeling how humans jointly infer coherent sets of goals, beliefs, and plans that explain an agent's actions, then evaluating statements about the agent's beliefs against these inferences via epistemic logic, our framework provides a conceptual role semantics for belief, explaining the gradedness and compositionality of human belief attributions, as well as their intimate connection with goals and plans. We evaluate this framework by studying how humans attribute goals and beliefs while watching an agent solve a doors-and-keys gridworld puzzle that requires instrumental reasoning about hidden objects. In contrast to pure logical deduction, non-mentalizing baselines, and mentalizing that ignores the role of instrumental plans, our model provides a much better fit to human goal and belief attributions, demonstrating the importance of theory-of-mind for a semantics of belief.