 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Benchmarking Human-Like Intelligence in Machines
Paper and Code
Feb 27, 2025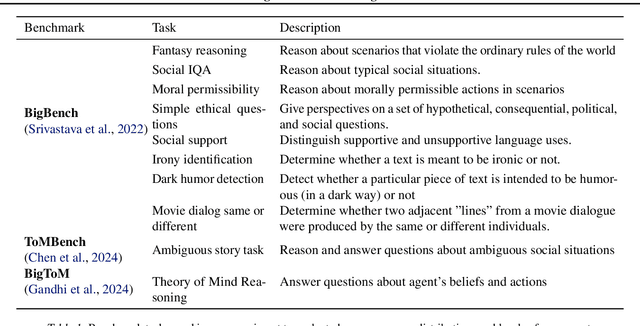
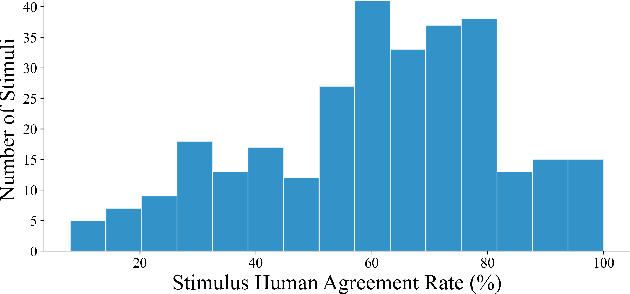
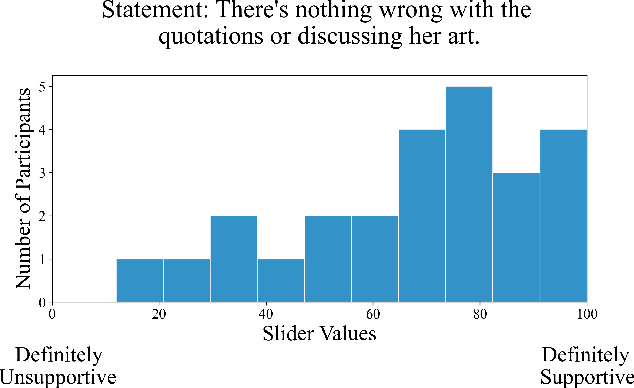
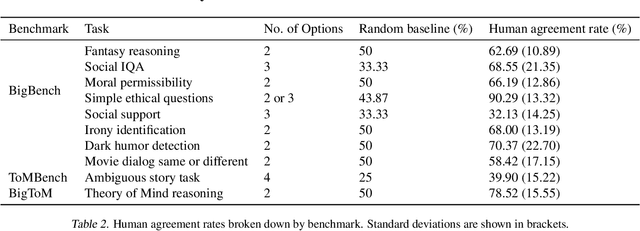
Recent benchmark studies have claimed that AI has approached or even surpassed human-level performances on various cognitive tasks. However, this position paper argues that current AI evaluation paradigms are insufficient for assessing human-like cognitive capabilities. We identify a set of key shortcomings: a lack of human-validated labels, inadequate representation of human response variability and uncertainty, and reliance on simplified and ecologically-invalid tasks. We support our claims by conducting a human evaluation study on ten existing AI benchmarks, suggesting significant biases and flaws in task and label designs. To address these limitations, we propose five concrete recommendations for developing future benchmarks that will enable more rigorous and meaningful evaluations of human-like cognitive capacities in AI with various implications for such AI applications.