 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Enigma of Artificial Reason: Investigating the Production-Evaluation Gap in Large Reasoning Models
May 31, 2026Studies of human reasoning have shown that people are typically stronger at evaluating reasoning than producing it from scratch. In contrast, large reasoning models (LRMs) are trained to excel at producing long chains of reasoning to solve complex problems. How then do LRMs perform at evaluating reasons? We investigate this with the Valid-Answer-Invalid-Reasoning (VAIR) dataset: math problems and solutions with trivial reasoning flaws but valid answers, designed to isolate reasoning evaluation from the confound of reasoning production. Unlike humans, who we find are only 6% worse at grading than solving such problems, we find a substantial production-evaluation gap in LRMs: frontier models score as low as 48% when evaluating VAIR solutions, despite near-perfect solution production. Why this enigma? Through chain-of-thought (CoT) analysis, we find evidence of an answer confirmation bias: LRMs often produce then check for the correct answer instead of carefully verifying each step, fabricating rationalizations even when noticing anomalous reasoning. Linear probes corroborate this, showing that while LRM activations encode some representation of valid reasoning, they fail to robustly represent VAIR solutions as invalid. Causal patching of the final answer's representations causes LRM verdicts and activations to flip, demonstrating that answer validity is responsible for models' confirmation biases. These findings indicate an outstanding limitation in dominant approaches to reasoning training, which incentivize LRMs to produce and confirm reasoning towards correct answers, but not to robustly evaluate the underlying reasons.
Belief Attribution as Mental Explanation: The Role of Accuracy, Informativity, and Causality
May 26, 2025A key feature of human theory-of-mind is the ability to attribute beliefs to other agents as mentalistic explanations for their behavior. But given the wide variety of beliefs that agents may hold about the world and the rich language we can use to express them, which specific beliefs are people inclined to attribute to others? In this paper, we investigate the hypothesis that people prefer to attribute beliefs that are good explanations for the behavior they observe. We develop a computational model that quantifies the explanatory strength of a (natural language) statement about an agent's beliefs via three factors: accuracy, informativity, and causal relevance to actions, each of which can be computed from a probabilistic generative model of belief-driven behavior. Using this model, we study the role of each factor in how people selectively attribute beliefs to other agents. We investigate this via an experiment where participants watch an agent collect keys hidden in boxes in order to reach a goal, then rank a set of statements describing the agent's beliefs about the boxes' contents. We find that accuracy and informativity perform reasonably well at predicting these rankings when combined, but that causal relevance is the single factor that best explains participants' responses.
Hypothesis-Driven Theory-of-Mind Reasoning for Large Language Models
Feb 17, 2025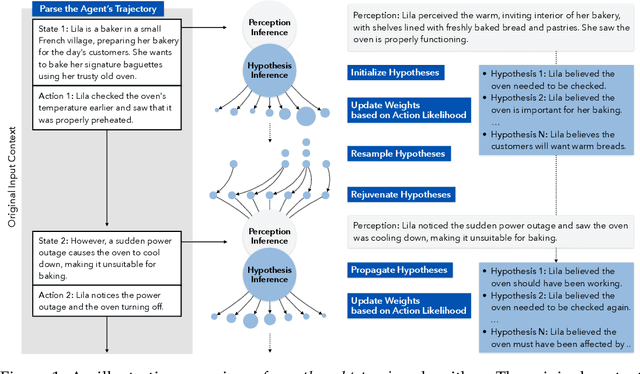

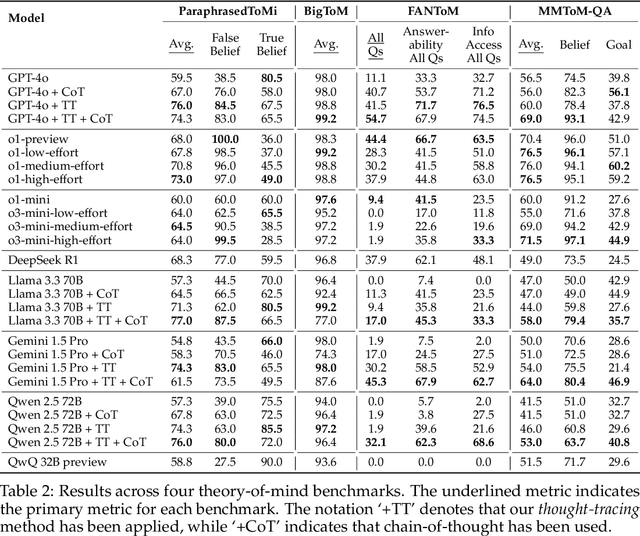
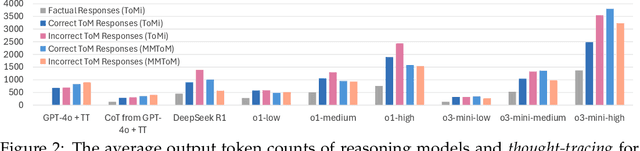
Existing LLM reasoning methods have shown impressive capabilities across various tasks, such as solving math and coding problems. However, applying these methods to scenarios without ground-truth answers or rule-based verification methods - such as tracking the mental states of an agent - remains challenging. Inspired by the sequential Monte Carlo algorithm, we introduce thought-tracing, an inference-time reasoning algorithm designed to trace the mental states of specific agents by generating hypotheses and weighting them based on observations without relying on ground-truth solutions to questions in datasets. Our algorithm is modeled after the Bayesian theory-of-mind framework, using LLMs to approximate probabilistic inference over agents' evolving mental states based on their perceptions and actions. We evaluate thought-tracing on diverse theory-of-mind benchmarks, demonstrating significant performance improvements compared to baseline LLMs. Our experiments also reveal interesting behaviors of the recent reasoning models - e.g., o1 and R1 - on theory-of-mind, highlighting the difference of social reasoning compared to other domains.
Beyond Preferences in AI Alignment
Aug 30, 2024



The dominant practice of AI alignment assumes (1) that preferences are an adequate representation of human values, (2) that human rationality can be understood in terms of maximizing the satisfaction of preferences, and (3) that AI systems should be aligned with the preferences of one or more humans to ensure that they behave safely and in accordance with our values. Whether implicitly followed or explicitly endorsed, these commitments constitute what we term a preferentist approach to AI alignment. In this paper, we characterize and challenge the preferentist approach, describing conceptual and technical alternatives that are ripe for further research. We first survey the limits of rational choice theory as a descriptive model, explaining how preferences fail to capture the thick semantic content of human values, and how utility representations neglect the possible incommensurability of those values. We then critique the normativity of expected utility theory (EUT) for humans and AI, drawing upon arguments showing how rational agents need not comply with EUT, while highlighting how EUT is silent on which preferences are normatively acceptable. Finally, we argue that these limitations motivate a reframing of the targets of AI alignment: Instead of alignment with the preferences of a human user, developer, or humanity-writ-large, AI systems should be aligned with normative standards appropriate to their social roles, such as the role of a general-purpose assistant. Furthermore, these standards should be negotiated and agreed upon by all relevant stakeholders. On this alternative conception of alignment, a multiplicity of AI systems will be able to serve diverse ends, aligned with normative standards that promote mutual benefit and limit harm despite our plural and divergent values.
Understanding Epistemic Language with a Bayesian Theory of Mind
Aug 21, 2024


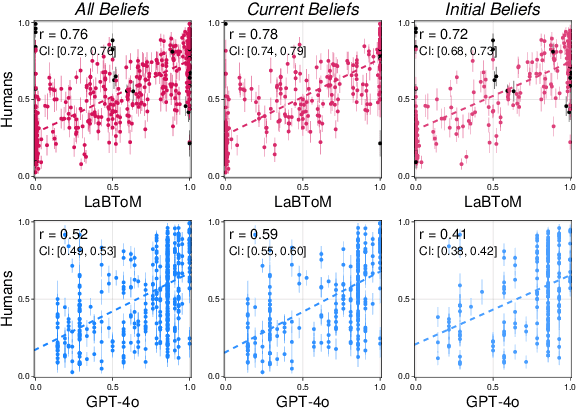
How do people understand and evaluate claims about others' beliefs, even though these beliefs cannot be directly observed? In this paper, we introduce a cognitive model of epistemic language interpretation, grounded in Bayesian inferences about other agents' goals, beliefs, and intentions: a language-augmented Bayesian theory-of-mind (LaBToM). By translating natural language into an epistemic ``language-of-thought'', then evaluating these translations against the inferences produced by inverting a probabilistic generative model of rational action and perception, LaBToM captures graded plausibility judgments about epistemic claims. We validate our model in an experiment where participants watch an agent navigate a maze to find keys hidden in boxes needed to reach their goal, then rate sentences about the agent's beliefs. In contrast with multimodal LLMs (GPT-4o, Gemini Pro) and ablated models, our model correlates highly with human judgments for a wide range of expressions, including modal language, uncertainty expressions, knowledge claims, likelihood comparisons, and attributions of false belief.
Infinite Ends from Finite Samples: Open-Ended Goal Inference as Top-Down Bayesian Filtering of Bottom-Up Proposals
Jul 23, 2024The space of human goals is tremendously vast; and yet, from just a few moments of watching a scene or reading a story, we seem to spontaneously infer a range of plausible motivations for the people and characters involved. What explains this remarkable capacity for intuiting other agents' goals, despite the infinitude of ends they might pursue? And how does this cohere with our understanding of other people as approximately rational agents? In this paper, we introduce a sequential Monte Carlo model of open-ended goal inference, which combines top-down Bayesian inverse planning with bottom-up sampling based on the statistics of co-occurring subgoals. By proposing goal hypotheses related to the subgoals achieved by an agent, our model rapidly generates plausible goals without exhaustive search, then filters out goals that would be irrational given the actions taken so far. We validate this model in a goal inference task called Block Words, where participants try to guess the word that someone is stacking out of lettered blocks. In comparison to both heuristic bottom-up guessing and exact Bayesian inference over hundreds of goals, our model better predicts the mean, variance, efficiency, and resource rationality of human goal inferences, achieving similar accuracy to the exact model at a fraction of the cognitive cost, while also explaining garden-path effects that arise from misleading bottom-up cues. Our experiments thus highlight the importance of uniting top-down and bottom-up models for explaining the speed, accuracy, and generality of human theory-of-mind.
Building Machines that Learn and Think with People
Jul 22, 2024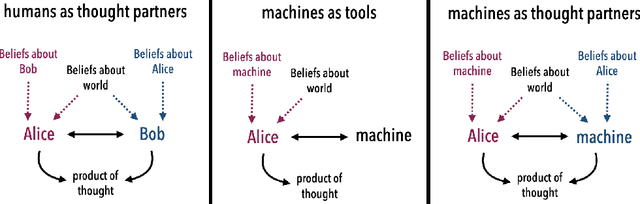
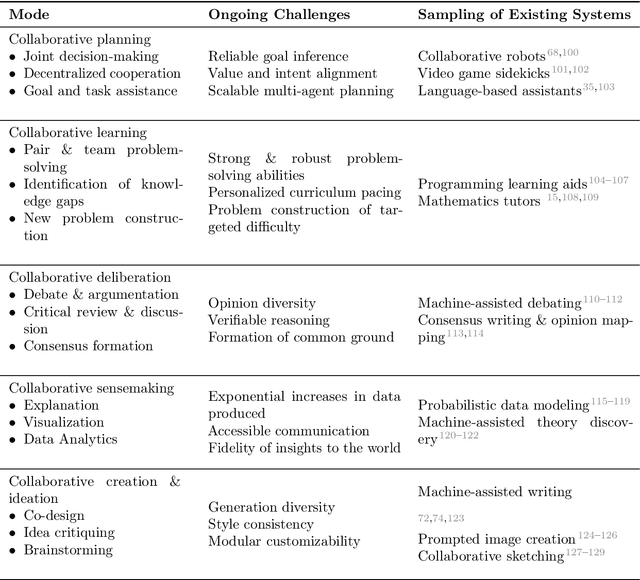
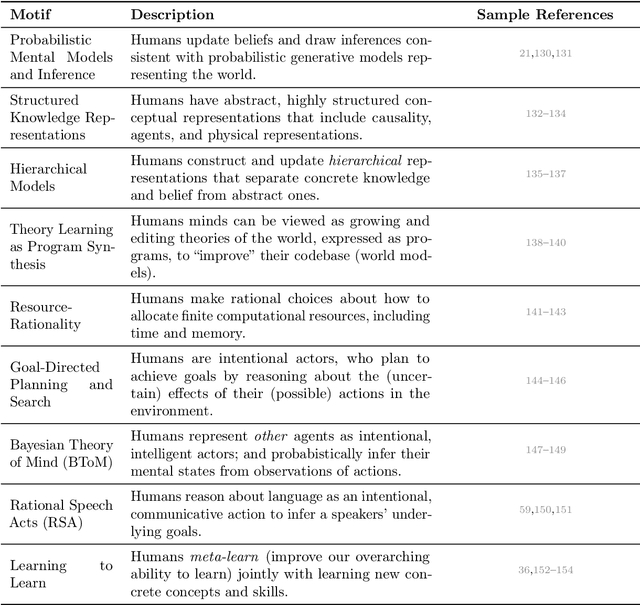
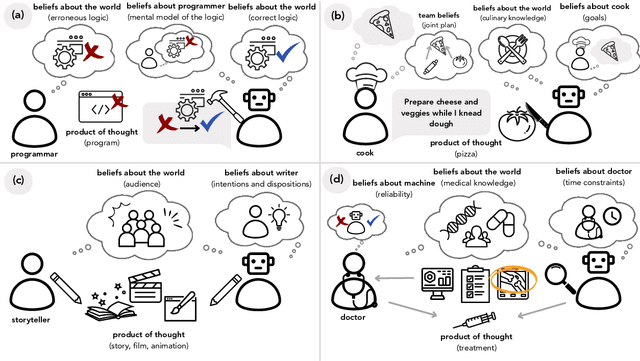
What do we want from machine intelligence? We envision machines that are not just tools for thought, but partners in thought: reasonable, insightful, knowledgeable, reliable, and trustworthy systems that think with us. Current artificial intelligence (AI) systems satisfy some of these criteria, some of the time. In this Perspective, we show how the science of collaborative cognition can be put to work to engineer systems that really can be called ``thought partners,'' systems built to meet our expectations and complement our limitations. We lay out several modes of collaborative thought in which humans and AI thought partners can engage and propose desiderata for human-compatible thought partnerships. Drawing on motifs from computational cognitive science, we motivate an alternative scaling path for the design of thought partners and ecosystems around their use through a Bayesian lens, whereby the partners we construct actively build and reason over models of the human and world.
Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
May 10, 2024



Ensuring that AI systems reliably and robustly avoid harmful or dangerous behaviours is a crucial challenge, especially for AI systems with a high degree of autonomy and general intelligence, or systems used in safety-critical contexts. In this paper, we will introduce and define a family of approaches to AI safety, which we will refer to as guaranteed safe (GS) AI. The core feature of these approaches is that they aim to produce AI systems which are equipped with high-assurance quantitative safety guarantees. This is achieved by the interplay of three core components: a world model (which provides a mathematical description of how the AI system affects the outside world), a safety specification (which is a mathematical description of what effects are acceptable), and a verifier (which provides an auditable proof certificate that the AI satisfies the safety specification relative to the world model). We outline a number of approaches for creating each of these three core components, describe the main technical challenges, and suggest a number of potential solutions to them. We also argue for the necessity of this approach to AI safety, and for the inadequacy of the main alternative approaches.
Pragmatic Instruction Following and Goal Assistance via Cooperative Language-Guided Inverse Planning
Feb 27, 2024People often give instructions whose meaning is ambiguous without further context, expecting that their actions or goals will disambiguate their intentions. How can we build assistive agents that follow such instructions in a flexible, context-sensitive manner? This paper introduces cooperative language-guided inverse plan search (CLIPS), a Bayesian agent architecture for pragmatic instruction following and goal assistance. Our agent assists a human by modeling them as a cooperative planner who communicates joint plans to the assistant, then performs multimodal Bayesian inference over the human's goal from actions and language, using large language models (LLMs) to evaluate the likelihood of an instruction given a hypothesized plan. Given this posterior, our assistant acts to minimize expected goal achievement cost, enabling it to pragmatically follow ambiguous instructions and provide effective assistance even when uncertain about the goal. We evaluate these capabilities in two cooperative planning domains (Doors, Keys & Gems and VirtualHome), finding that CLIPS significantly outperforms GPT-4V, LLM-based literal instruction following and unimodal inverse planning in both accuracy and helpfulness, while closely matching the inferences and assistive judgments provided by human raters.
Learning and Sustaining Shared Normative Systems via Bayesian Rule Induction in Markov Games
Feb 22, 2024



A universal feature of human societies is the adoption of systems of rules and norms in the service of cooperative ends. How can we build learning agents that do the same, so that they may flexibly cooperate with the human institutions they are embedded in? We hypothesize that agents can achieve this by assuming there exists a shared set of norms that most others comply with while pursuing their individual desires, even if they do not know the exact content of those norms. By assuming shared norms, a newly introduced agent can infer the norms of an existing population from observations of compliance and violation. Furthermore, groups of agents can converge to a shared set of norms, even if they initially diverge in their beliefs about what the norms are. This in turn enables the stability of the normative system: since agents can bootstrap common knowledge of the norms, this leads the norms to be widely adhered to, enabling new entrants to rapidly learn those norms. We formalize this framework in the context of Markov games and demonstrate its operation in a multi-agent environment via approximately Bayesian rule induction of obligative and prohibitive norms. Using our approach, agents are able to rapidly learn and sustain a variety of cooperative institutions, including resource management norms and compensation for pro-social labor, promoting collective welfare while still allowing agents to act in their own interests.