 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Machines that Learn and Think with People
Jul 22, 2024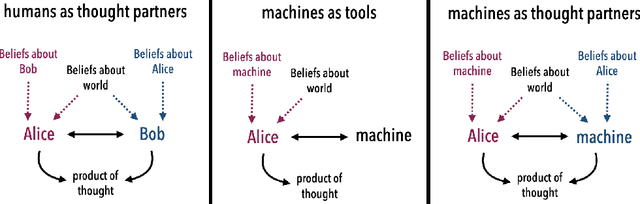
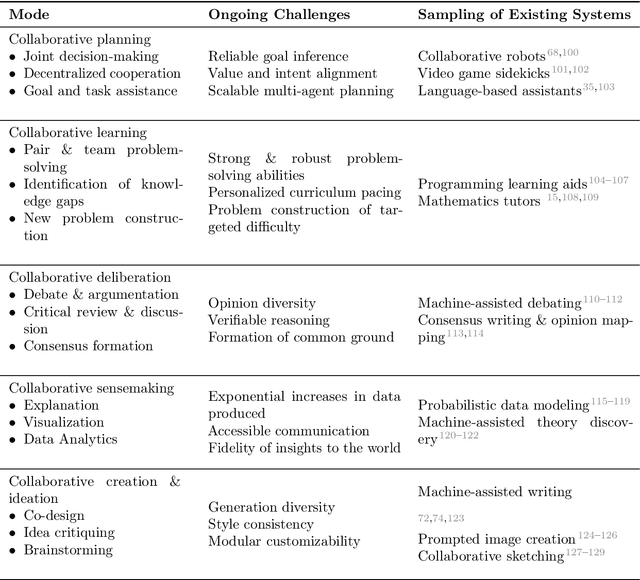
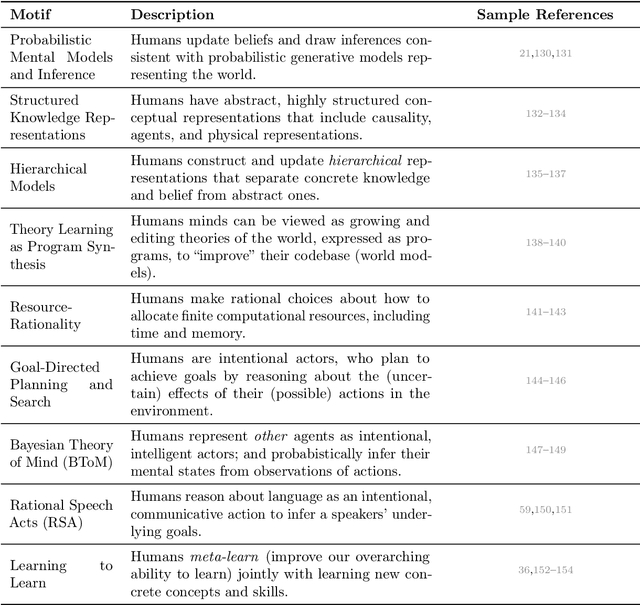
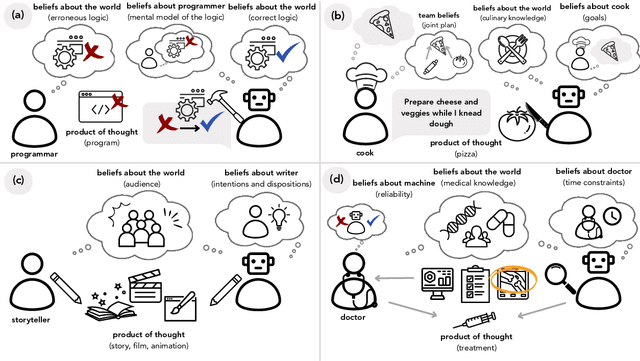
What do we want from machine intelligence? We envision machines that are not just tools for thought, but partners in thought: reasonable, insightful, knowledgeable, reliable, and trustworthy systems that think with us. Current artificial intelligence (AI) systems satisfy some of these criteria, some of the time. In this Perspective, we show how the science of collaborative cognition can be put to work to engineer systems that really can be called ``thought partners,'' systems built to meet our expectations and complement our limitations. We lay out several modes of collaborative thought in which humans and AI thought partners can engage and propose desiderata for human-compatible thought partnerships. Drawing on motifs from computational cognitive science, we motivate an alternative scaling path for the design of thought partners and ecosystems around their use through a Bayesian lens, whereby the partners we construct actively build and reason over models of the human and world.
Representational Alignment Supports Effective Machine Teaching
Jun 06, 2024A good teacher should not only be knowledgeable; but should be able to communicate in a way that the student understands -- to share the student's representation of the world. In this work, we integrate insights from machine teaching and pragmatic communication with the burgeoning literature on representational alignment to characterize a utility curve defining a relationship between representational alignment and teacher capability for promoting student learning. To explore the characteristics of this utility curve, we design a supervised learning environment that disentangles representational alignment from teacher accuracy. We conduct extensive computational experiments with machines teaching machines, complemented by a series of experiments in which machines teach humans. Drawing on our findings that improved representational alignment with a student improves student learning outcomes (i.e., task accuracy), we design a classroom matching procedure that assigns students to teachers based on the utility curve. If we are to design effective machine teachers, it is not enough to build teachers that are accurate -- we want teachers that can align, representationally, to their students too.
Concept Alignment as a Prerequisite for Value Alignment
Oct 30, 2023



Value alignment is essential for building AI systems that can safely and reliably interact with people. However, what a person values -- and is even capable of valuing -- depends on the concepts that they are currently using to understand and evaluate what happens in the world. The dependence of values on concepts means that concept alignment is a prerequisite for value alignment -- agents need to align their representation of a situation with that of humans in order to successfully align their values. Here, we formally analyze the concept alignment problem in the inverse reinforcement learning setting, show how neglecting concept alignment can lead to systematic value mis-alignment, and describe an approach that helps minimize such failure modes by jointly reasoning about a person's concepts and values. Additionally, we report experimental results with human participants showing that humans reason about the concepts used by an agent when acting intentionally, in line with our joint reasoning model.
Diagnosis, Feedback, Adaptation: A Human-in-the-Loop Framework for Test-Time Policy Adaptation
Jul 13, 2023Policies often fail due to distribution shift -- changes in the state and reward that occur when a policy is deployed in new environments. Data augmentation can increase robustness by making the model invariant to task-irrelevant changes in the agent's observation. However, designers don't know which concepts are irrelevant a priori, especially when different end users have different preferences about how the task is performed. We propose an interactive framework to leverage feedback directly from the user to identify personalized task-irrelevant concepts. Our key idea is to generate counterfactual demonstrations that allow users to quickly identify possible task-relevant and irrelevant concepts. The knowledge of task-irrelevant concepts is then used to perform data augmentation and thus obtain a policy adapted to personalized user objectives. We present experiments validating our framework on discrete and continuous control tasks with real human users. Our method (1) enables users to better understand agent failure, (2) reduces the number of demonstrations required for fine-tuning, and (3) aligns the agent to individual user task preferences.