 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Human Guidance Matters in Collaborative Vibe Coding
Feb 11, 2026Writing code has been one of the most transformative ways for human societies to translate abstract ideas into tangible technologies. Modern AI is transforming this process by enabling experts and non-experts alike to generate code without actually writing code, but instead, through natural language instructions, or "vibe coding". While increasingly popular, the cumulative impact of vibe coding on productivity and collaboration, as well as the role of humans in this process, remains unclear. Here, we introduce a controlled experimental framework for studying collaborative vibe coding and use it to compare human-led, AI-led, and hybrid groups. Across 16 experiments involving 604 human participants, we show that people provide uniquely effective high-level instructions for vibe coding across iterations, whereas AI-provided instructions often result in performance collapse. We further demonstrate that hybrid systems perform best when humans retain directional control (providing the instructions), while evaluation is delegated to AI.
GlobalMood: A cross-cultural benchmark for music emotion recognition
May 14, 2025


Human annotations of mood in music are essential for music generation and recommender systems. However, existing datasets predominantly focus on Western songs with mood terms derived from English, which may limit generalizability across diverse linguistic and cultural backgrounds. To address this, we introduce `GlobalMood', a novel cross-cultural benchmark dataset comprising 1,180 songs sampled from 59 countries, with large-scale annotations collected from 2,519 individuals across five culturally and linguistically distinct locations: U.S., France, Mexico, S. Korea, and Egypt. Rather than imposing predefined mood categories, we implement a bottom-up, participant-driven approach to organically elicit culturally specific music-related mood terms. We then recruit another pool of human participants to collect 988,925 ratings for these culture-specific descriptors. Our analysis confirms the presence of a valence-arousal structure shared across cultures, yet also reveals significant divergences in how certain mood terms, despite being dictionary equivalents, are perceived cross-culturally. State-of-the-art multimodal models benefit substantially from fine-tuning on our cross-culturally balanced dataset, as evidenced by improved alignment with human evaluations - particularly in non-English contexts. More broadly, our findings inform the ongoing debate on the universality versus cultural specificity of emotional descriptors, and our methodology can contribute to other multimodal and cross-lingual research.
Are Expressions for Music Emotions the Same Across Cultures?
Feb 12, 2025Music evokes profound emotions, yet the universality of emotional descriptors across languages remains debated. A key challenge in cross-cultural research on music emotion is biased stimulus selection and manual curation of taxonomies, predominantly relying on Western music and languages. To address this, we propose a balanced experimental design with nine online experiments in Brazil, the US, and South Korea, involving N=672 participants. First, we sample a balanced set of popular music from these countries. Using an open-ended tagging pipeline, we then gather emotion terms to create culture-specific taxonomies. Finally, using these bottom-up taxonomies, participants rate emotions of each song. This allows us to map emotional similarities within and across cultures. Results show consistency in high arousal, high valence emotions but greater variability in others. Notably, machine translations were often inadequate to capture music-specific meanings. These findings together highlight the need for a domain-sensitive, open-ended, bottom-up emotion elicitation approach to reduce cultural biases in emotion research.
Representational Alignment Supports Effective Machine Teaching
Jun 06, 2024



A good teacher should not only be knowledgeable; but should be able to communicate in a way that the student understands -- to share the student's representation of the world. In this work, we integrate insights from machine teaching and pragmatic communication with the burgeoning literature on representational alignment to characterize a utility curve defining a relationship between representational alignment and teacher capability for promoting student learning. To explore the characteristics of this utility curve, we design a supervised learning environment that disentangles representational alignment from teacher accuracy. We conduct extensive computational experiments with machines teaching machines, complemented by a series of experiments in which machines teach humans. Drawing on our findings that improved representational alignment with a student improves student learning outcomes (i.e., task accuracy), we design a classroom matching procedure that assigns students to teachers based on the utility curve. If we are to design effective machine teachers, it is not enough to build teachers that are accurate -- we want teachers that can align, representationally, to their students too.
Characterizing Similarities and Divergences in Conversational Tones in Humans and LLMs by Sampling with People
Jun 06, 2024Conversational tones -- the manners and attitudes in which speakers communicate -- are essential to effective communication. Amidst the increasing popularization of Large Language Models (LLMs) over recent years, it becomes necessary to characterize the divergences in their conversational tones relative to humans. However, existing investigations of conversational modalities rely on pre-existing taxonomies or text corpora, which suffer from experimenter bias and may not be representative of real-world distributions for the studies' psycholinguistic domains. Inspired by methods from cognitive science, we propose an iterative method for simultaneously eliciting conversational tones and sentences, where participants alternate between two tasks: (1) one participant identifies the tone of a given sentence and (2) a different participant generates a sentence based on that tone. We run 100 iterations of this process with human participants and GPT-4, then obtain a dataset of sentences and frequent conversational tones. In an additional experiment, humans and GPT-4 annotated all sentences with all tones. With data from 1,339 human participants, 33,370 human judgments, and 29,900 GPT-4 queries, we show how our approach can be used to create an interpretable geometric representation of relations between conversational tones in humans and GPT-4. This work demonstrates how combining ideas from machine learning and cognitive science can address challenges in human-computer interactions.
A Rational Analysis of the Speech-to-Song Illusion
Feb 10, 2024


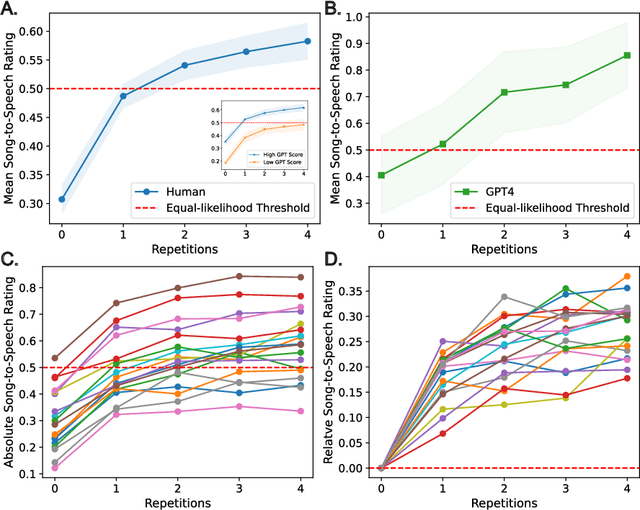
The speech-to-song illusion is a robust psychological phenomenon whereby a spoken sentence sounds increasingly more musical as it is repeated. Despite decades of research, a complete formal account of this transformation is still lacking, and some of its nuanced characteristics, namely, that certain phrases appear to transform while others do not, is not well understood. Here we provide a formal account of this phenomenon, by recasting it as a statistical inference whereby a rational agent attempts to decide whether a sequence of utterances is more likely to have been produced in a song or speech. Using this approach and analyzing song and speech corpora, we further introduce a novel prose-to-lyrics illusion that is purely text-based. In this illusion, simply duplicating written sentences makes them appear more like song lyrics. We provide robust evidence for this new illusion in both human participants and large language models.
Giving Robots a Voice: Human-in-the-Loop Voice Creation and open-ended Labeling
Feb 07, 2024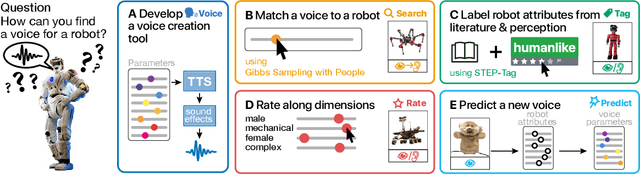
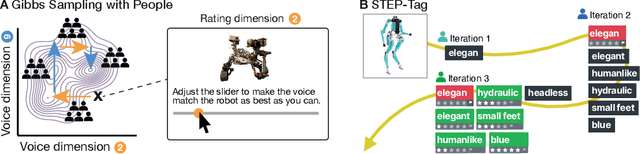
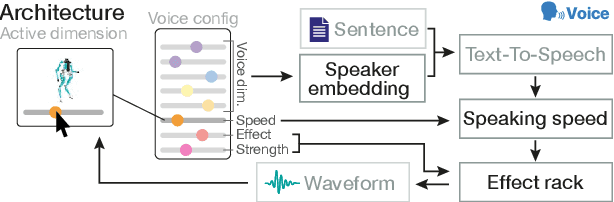
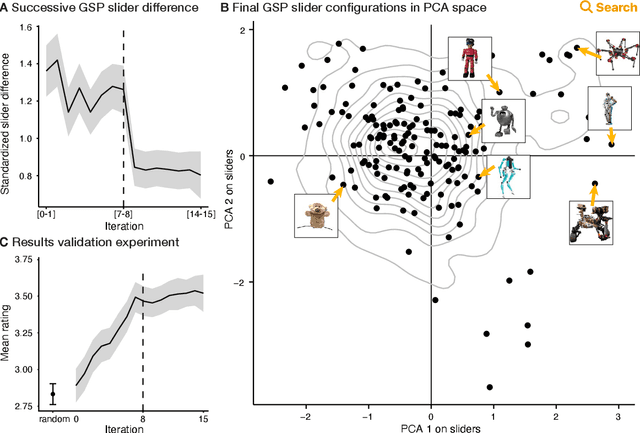
Speech is a natural interface for humans to interact with robots. Yet, aligning a robot's voice to its appearance is challenging due to the rich vocabulary of both modalities. Previous research has explored a few labels to describe robots and tested them on a limited number of robots and existing voices. Here, we develop a robot-voice creation tool followed by large-scale behavioral human experiments (N=2,505). First, participants collectively tune robotic voices to match 175 robot images using an adaptive human-in-the-loop pipeline. Then, participants describe their impression of the robot or their matched voice using another human-in-the-loop paradigm for open-ended labeling. The elicited taxonomy is then used to rate robot attributes and to predict the best voice for an unseen robot. We offer a web interface to aid engineers in customizing robot voices, demonstrating the synergy between cognitive science and machine learning for engineering tools.
Getting aligned on representational alignment
Nov 02, 2023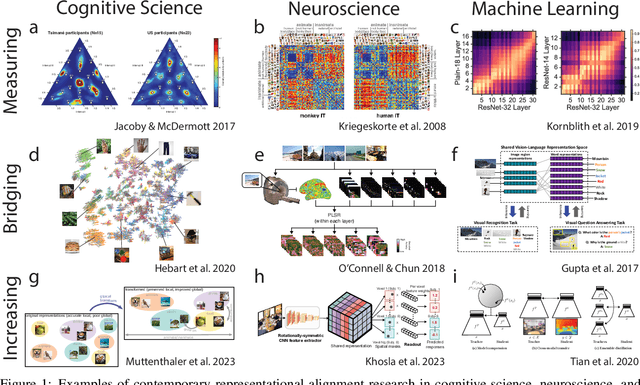
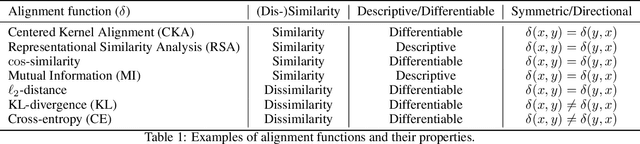
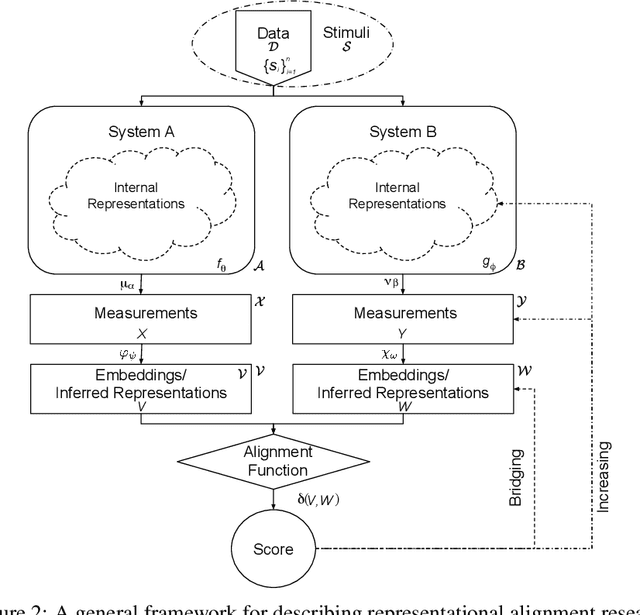
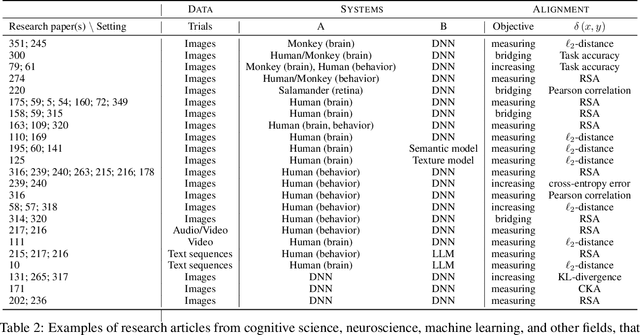
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
The Universal Law of Generalization Holds for Naturalistic Stimuli
Jun 14, 2023



Shepard's universal law of generalization is a remarkable hypothesis about how intelligent organisms should perceive similarity. In its broadest form, the universal law states that the level of perceived similarity between a pair of stimuli should decay as a concave function of their distance when embedded in an appropriate psychological space. While extensively studied, evidence in support of the universal law has relied on low-dimensional stimuli and small stimulus sets that are very different from their real-world counterparts. This is largely because pairwise comparisons -- as required for similarity judgments -- scale quadratically in the number of stimuli. We provide direct evidence for the universal law in a naturalistic high-dimensional regime by analyzing an existing dataset of 214,200 human similarity judgments and a newly collected dataset of 390,819 human generalization judgments (N=2406 US participants) across three sets of natural images.
Around the world in 60 words: A generative vocabulary test for online research
Feb 03, 2023Conducting experiments with diverse participants in their native languages can uncover insights into culture, cognition, and language that may not be revealed otherwise. However, conducting these experiments online makes it difficult to validate self-reported language proficiency. Furthermore, existing proficiency tests are small and cover only a few languages. We present an automated pipeline to generate vocabulary tests using text from Wikipedia. Our pipeline samples rare nouns and creates pseudowords with the same low-level statistics. Six behavioral experiments (N=236) in six countries and eight languages show that (a) our test can distinguish between native speakers of closely related languages, (b) the test is reliable ($r=0.82$), and (c) performance strongly correlates with existing tests (LexTale) and self-reports. We further show that test accuracy is negatively correlated with the linguistic distance between the tested and the native language. Our test, available in eight languages, can easily be extended to other languages.