 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Attribution to Action: A Human-Centered Application of Activation Steering
Apr 13, 2026Explainable AI (XAI) methods reveal which features influence model predictions, yet provide limited means for practitioners to act on these explanations. Activation steering of components identified via XAI offers a path toward actionable explanations, although its practical utility remains understudied. We introduce an interactive workflow combining SAE-based attribution with activation steering for instance-level analysis of concept usage in vision models, implemented as a web-based tool. Based on this workflow, we conduct semi-structured expert interviews (N=8) with debugging tasks on CLIP to investigate how practitioners reason about, trust, and apply activation steering. We find that steering enables a shift from inspection to intervention-based hypothesis testing (8/8 participants), with most grounding trust in observed model responses rather than explanation plausibility alone (6/8). Participants adopted systematic debugging strategies dominated by component suppression (7/8) and highlighted risks including ripple effects and limited generalization of instance-level corrections. Overall, activation steering renders interpretability more actionable while raising important considerations for safe and effective use.
Communicating Through Avatars in Industry 5.0: A Focus Group Study on Human-Robot Collaboration
Jun 10, 2025The integration of collaborative robots (cobots) in industrial settings raises concerns about worker well-being, particularly due to reduced social interactions. Avatars - designed to facilitate worker interactions and engagement - are promising solutions to enhance the human-robot collaboration (HRC) experience. However, real-world perspectives on avatar-supported HRC remain unexplored. To address this gap, we conducted a focus group study with employees from a German manufacturing company that uses cobots. Before the discussion, participants engaged with a scripted, industry-like HRC demo in a lab setting. This qualitative approach provided valuable insights into the avatar's potential roles, improvements to its behavior, and practical considerations for deploying them in industrial workcells. Our findings also emphasize the importance of personalized communication and task assistance. Although our study's limitations restrict its generalizability, it serves as an initial step in recognizing the potential of adaptive, context-aware avatar interactions in real-world industrial environments.
Relevant Irrelevance: Generating Alterfactual Explanations for Image Classifiers
May 08, 2024
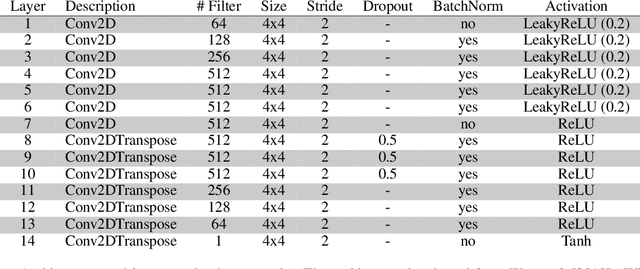

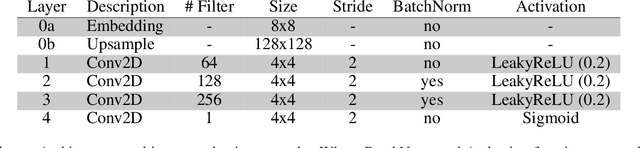
In this paper, we demonstrate the feasibility of alterfactual explanations for black box image classifiers. Traditional explanation mechanisms from the field of Counterfactual Thinking are a widely-used paradigm for Explainable Artificial Intelligence (XAI), as they follow a natural way of reasoning that humans are familiar with. However, most common approaches from this field are based on communicating information about features or characteristics that are especially important for an AI's decision. However, to fully understand a decision, not only knowledge about relevant features is needed, but the awareness of irrelevant information also highly contributes to the creation of a user's mental model of an AI system. To this end, a novel approach for explaining AI systems called alterfactual explanations was recently proposed on a conceptual level. It is based on showing an alternative reality where irrelevant features of an AI's input are altered. By doing so, the user directly sees which input data characteristics can change arbitrarily without influencing the AI's decision. In this paper, we show for the first time that it is possible to apply this idea to black box models based on neural networks. To this end, we present a GAN-based approach to generate these alterfactual explanations for binary image classifiers. Further, we present a user study that gives interesting insights on how alterfactual explanations can complement counterfactual explanations.
Giving Robots a Voice: Human-in-the-Loop Voice Creation and open-ended Labeling
Feb 07, 2024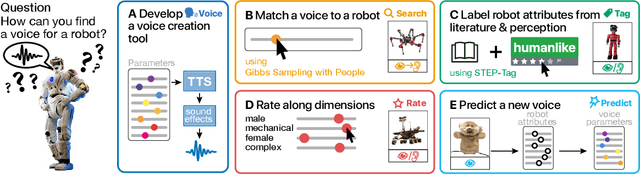
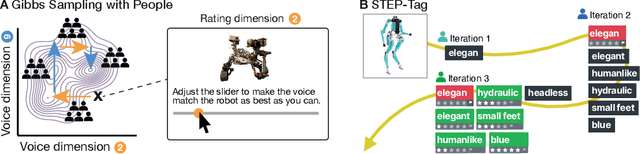
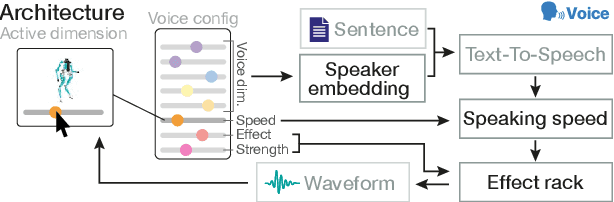
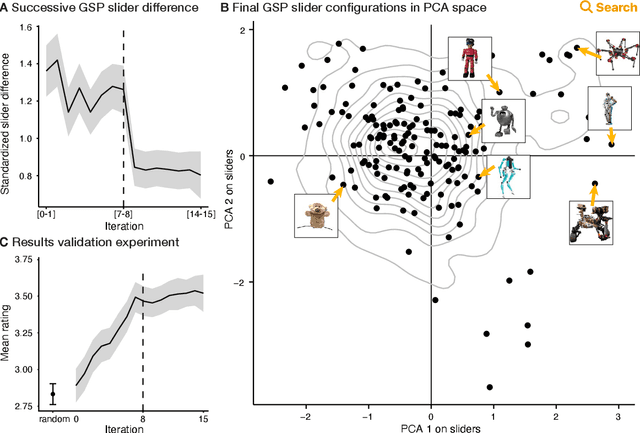
Speech is a natural interface for humans to interact with robots. Yet, aligning a robot's voice to its appearance is challenging due to the rich vocabulary of both modalities. Previous research has explored a few labels to describe robots and tested them on a limited number of robots and existing voices. Here, we develop a robot-voice creation tool followed by large-scale behavioral human experiments (N=2,505). First, participants collectively tune robotic voices to match 175 robot images using an adaptive human-in-the-loop pipeline. Then, participants describe their impression of the robot or their matched voice using another human-in-the-loop paradigm for open-ended labeling. The elicited taxonomy is then used to rate robot attributes and to predict the best voice for an unseen robot. We offer a web interface to aid engineers in customizing robot voices, demonstrating the synergy between cognitive science and machine learning for engineering tools.
What Do End-Users Really Want? Investigation of Human-Centered XAI for Mobile Health Apps
Oct 07, 2022

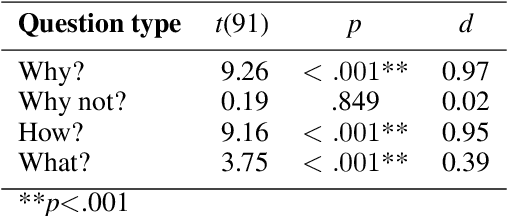
In healthcare, AI systems support clinicians and patients in diagnosis, treatment, and monitoring, but many systems' poor explainability remains challenging for practical application. Overcoming this barrier is the goal of explainable AI (XAI). However, an explanation can be perceived differently and, thus, not solve the black-box problem for everyone. The domain of Human-Centered AI deals with this problem by adapting AI to users. We present a user-centered persona concept to evaluate XAI and use it to investigate end-users preferences for various explanation styles and contents in a mobile health stress monitoring application. The results of our online survey show that users' demographics and personality, as well as the type of explanation, impact explanation preferences, indicating that these are essential features for XAI design. We subsumed the results in three prototypical user personas: power-, casual-, and privacy-oriented users. Our insights bring an interactive, human-centered XAI closer to practical application.
Do We Need Explainable AI in Companies? Investigation of Challenges, Expectations, and Chances from Employees' Perspective
Oct 07, 2022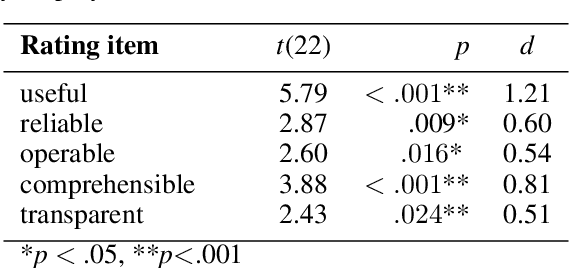
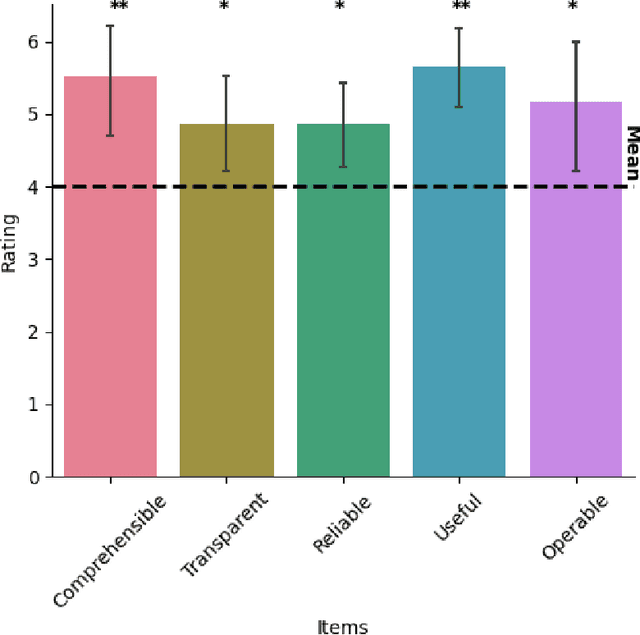
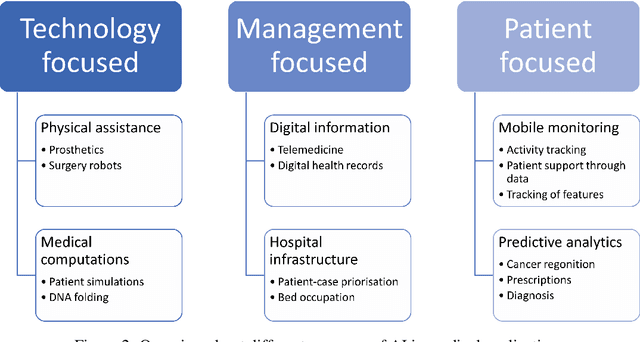
By using AI, companies want to improve their business success and innovation chances. However, in doing so, they (companies and their employees) are faced with new requirements. In particular, legal regulations call for transparency and comprehensibility of AI systems. The field of XAI deals with these issues. Currently, the results are mostly obtained in lab studies, while the transfer to real-world applications is lacking. This includes considering employees' needs and attributes, which may differ from end-users in the lab. Therefore, this project report paper provides initial insights into employees' specific needs and attitudes towards (X)AI. For this, the results of a project's online survey are reported that investigate two employees' perspectives (i.e., company level and employee level) on (X)AI to create a holistic view of challenges, risks, and needs of employees. Our findings suggest that AI and XAI are well-known terms perceived as important for employees. This is a first step for XAI to be a potential driver to foster the successful usage of AI by providing transparent and comprehensible insights into AI technologies. To benefit from (X)AI technologies, supportive employees on the management level are valuable catalysts. This work contributes to the ongoing demand for XAI research to develop human-centered and domain-specific XAI designs.
Alterfactual Explanations -- The Relevance of Irrelevance for Explaining AI Systems
Jul 19, 2022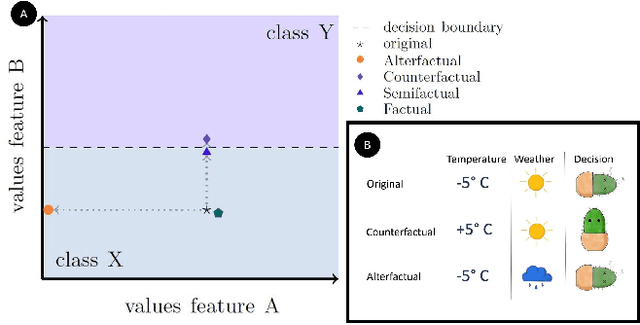
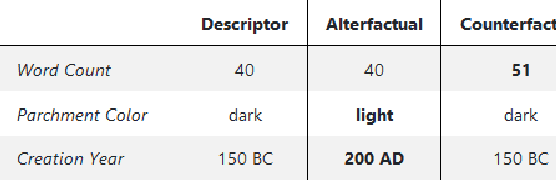
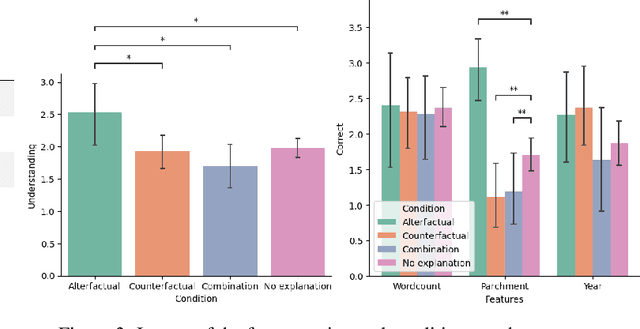
Explanation mechanisms from the field of Counterfactual Thinking are a widely-used paradigm for Explainable Artificial Intelligence (XAI), as they follow a natural way of reasoning that humans are familiar with. However, all common approaches from this field are based on communicating information about features or characteristics that are especially important for an AI's decision. We argue that in order to fully understand a decision, not only knowledge about relevant features is needed, but that the awareness of irrelevant information also highly contributes to the creation of a user's mental model of an AI system. Therefore, we introduce a new way of explaining AI systems. Our approach, which we call Alterfactual Explanations, is based on showing an alternative reality where irrelevant features of an AI's input are altered. By doing so, the user directly sees which characteristics of the input data can change arbitrarily without influencing the AI's decision. We evaluate our approach in an extensive user study, revealing that it is able to significantly contribute to the participants' understanding of an AI. We show that alterfactual explanations are suited to convey an understanding of different aspects of the AI's reasoning than established counterfactual explanation methods.
This is not the Texture you are looking for! Introducing Novel Counterfactual Explanations for Non-Experts using Generative Adversarial Learning
Dec 22, 2020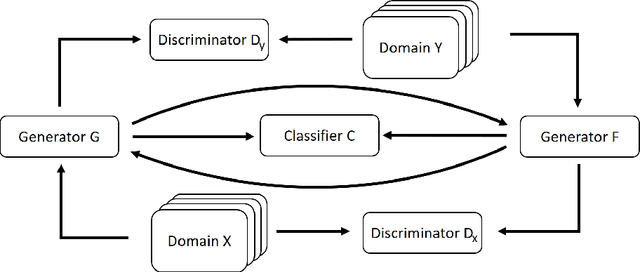
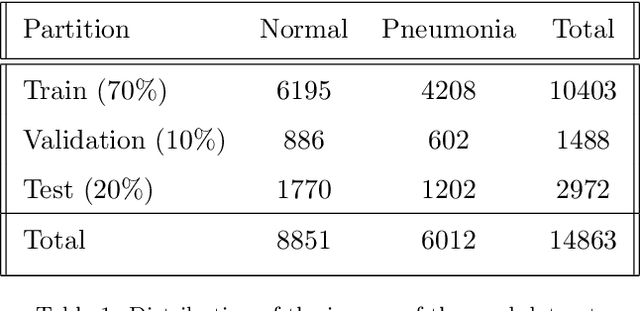
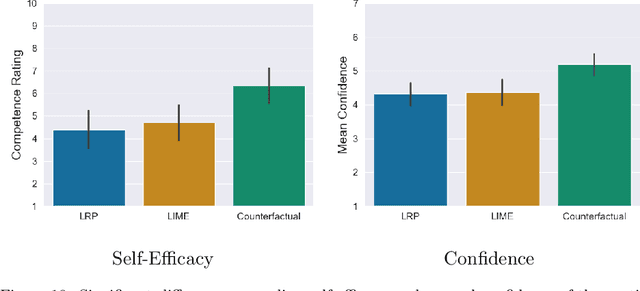
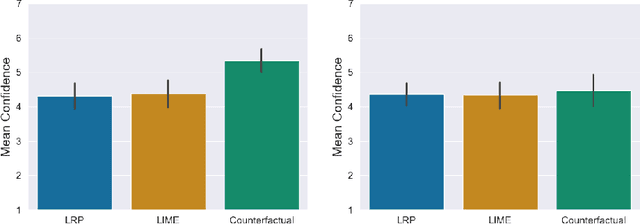
With the ongoing rise of machine learning, the need for methods for explaining decisions made by artificial intelligence systems is becoming a more and more important topic. Especially for image classification tasks, many state-of-the-art tools to explain such classifiers rely on visual highlighting of important areas of the input data. Contrary, counterfactual explanation systems try to enable a counterfactual reasoning by modifying the input image in a way such that the classifier would have made a different prediction. By doing so, the users of counterfactual explanation systems are equipped with a completely different kind of explanatory information. However, methods for generating realistic counterfactual explanations for image classifiers are still rare. In this work, we present a novel approach to generate such counterfactual image explanations based on adversarial image-to-image translation techniques. Additionally, we conduct a user study to evaluate our approach in a use case which was inspired by a healthcare scenario. Our results show that our approach leads to significantly better results regarding mental models, explanation satisfaction, trust, emotions, and self-efficacy than two state-of-the art systems that work with saliency maps, namely LIME and LRP.
Local and Global Explanations of Agent Behavior: Integrating Strategy Summaries with Saliency Maps
May 29, 2020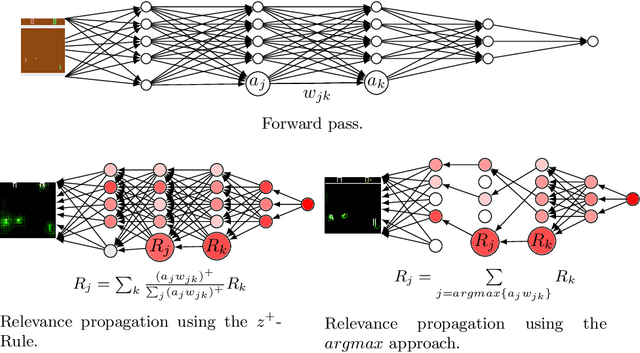

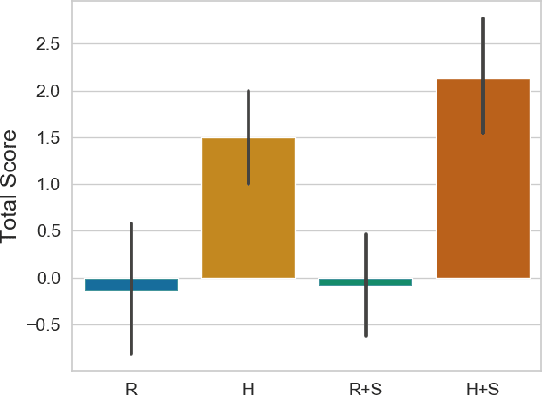
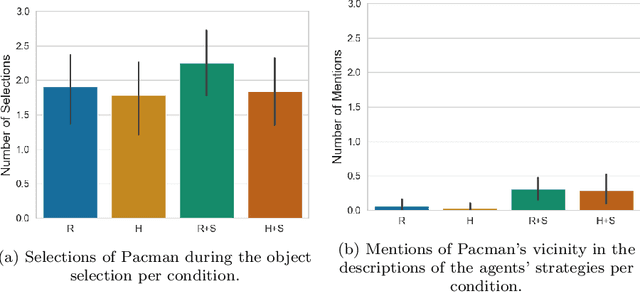
With advances in reinforcement learning (RL), agents are now being developed in high-stakes application domains such as healthcare and transportation. Explaining the behavior of these agents is challenging, as the environments in which they act have large state spaces, and their decision-making can be affected by delayed rewards, making it difficult to analyze their behavior. To address this problem, several approaches have been developed. Some approaches attempt to convey the $\textit{global}$ behavior of the agent, describing the actions it takes in different states. Other approaches devised $\textit{local}$ explanations which provide information regarding the agent's decision-making in a particular state. In this paper, we combine global and local explanation methods, and evaluate their joint and separate contributions, providing (to the best of our knowledge) the first user study of combined local and global explanations for RL agents. Specifically, we augment strategy summaries that extract important trajectories of states from simulations of the agent with saliency maps which show what information the agent attends to. Our results show that the choice of what states to include in the summary (global information) strongly affects people's understanding of agents: participants shown summaries that included important states significantly outperformed participants who were presented with agent behavior in a randomly set of chosen world-states. We find mixed results with respect to augmenting demonstrations with saliency maps (local information), as the addition of saliency maps did not significantly improve performance in most cases. However, we do find some evidence that saliency maps can help users better understand what information the agent relies on in its decision making, suggesting avenues for future work that can further improve explanations of RL agents.