 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobalMood: A cross-cultural benchmark for music emotion recognition
May 14, 2025


Human annotations of mood in music are essential for music generation and recommender systems. However, existing datasets predominantly focus on Western songs with mood terms derived from English, which may limit generalizability across diverse linguistic and cultural backgrounds. To address this, we introduce `GlobalMood', a novel cross-cultural benchmark dataset comprising 1,180 songs sampled from 59 countries, with large-scale annotations collected from 2,519 individuals across five culturally and linguistically distinct locations: U.S., France, Mexico, S. Korea, and Egypt. Rather than imposing predefined mood categories, we implement a bottom-up, participant-driven approach to organically elicit culturally specific music-related mood terms. We then recruit another pool of human participants to collect 988,925 ratings for these culture-specific descriptors. Our analysis confirms the presence of a valence-arousal structure shared across cultures, yet also reveals significant divergences in how certain mood terms, despite being dictionary equivalents, are perceived cross-culturally. State-of-the-art multimodal models benefit substantially from fine-tuning on our cross-culturally balanced dataset, as evidenced by improved alignment with human evaluations - particularly in non-English contexts. More broadly, our findings inform the ongoing debate on the universality versus cultural specificity of emotional descriptors, and our methodology can contribute to other multimodal and cross-lingual research.
Are Expressions for Music Emotions the Same Across Cultures?
Feb 12, 2025Music evokes profound emotions, yet the universality of emotional descriptors across languages remains debated. A key challenge in cross-cultural research on music emotion is biased stimulus selection and manual curation of taxonomies, predominantly relying on Western music and languages. To address this, we propose a balanced experimental design with nine online experiments in Brazil, the US, and South Korea, involving N=672 participants. First, we sample a balanced set of popular music from these countries. Using an open-ended tagging pipeline, we then gather emotion terms to create culture-specific taxonomies. Finally, using these bottom-up taxonomies, participants rate emotions of each song. This allows us to map emotional similarities within and across cultures. Results show consistency in high arousal, high valence emotions but greater variability in others. Notably, machine translations were often inadequate to capture music-specific meanings. These findings together highlight the need for a domain-sensitive, open-ended, bottom-up emotion elicitation approach to reduce cultural biases in emotion research.
A Rational Analysis of the Speech-to-Song Illusion
Feb 10, 2024


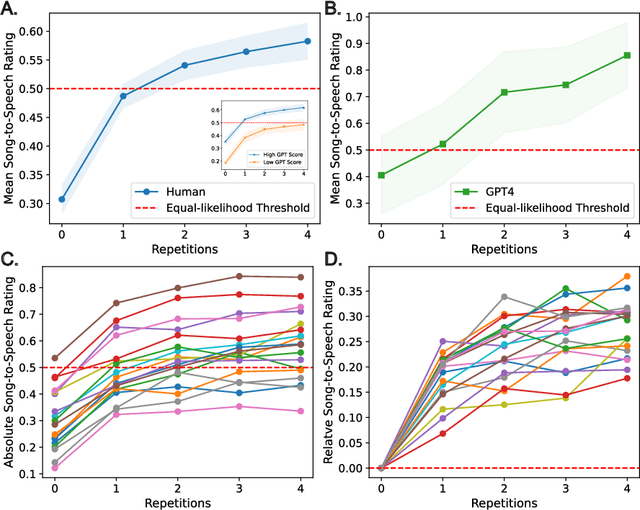
The speech-to-song illusion is a robust psychological phenomenon whereby a spoken sentence sounds increasingly more musical as it is repeated. Despite decades of research, a complete formal account of this transformation is still lacking, and some of its nuanced characteristics, namely, that certain phrases appear to transform while others do not, is not well understood. Here we provide a formal account of this phenomenon, by recasting it as a statistical inference whereby a rational agent attempts to decide whether a sequence of utterances is more likely to have been produced in a song or speech. Using this approach and analyzing song and speech corpora, we further introduce a novel prose-to-lyrics illusion that is purely text-based. In this illusion, simply duplicating written sentences makes them appear more like song lyrics. We provide robust evidence for this new illusion in both human participants and large language models.
Giving Robots a Voice: Human-in-the-Loop Voice Creation and open-ended Labeling
Feb 07, 2024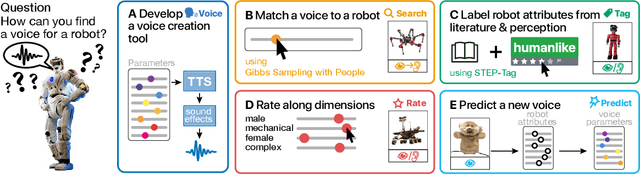
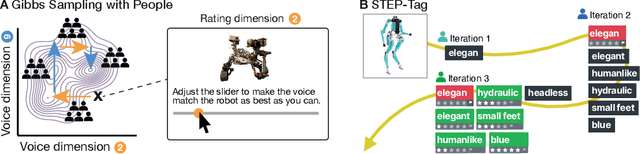
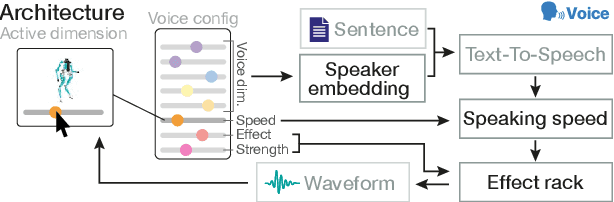
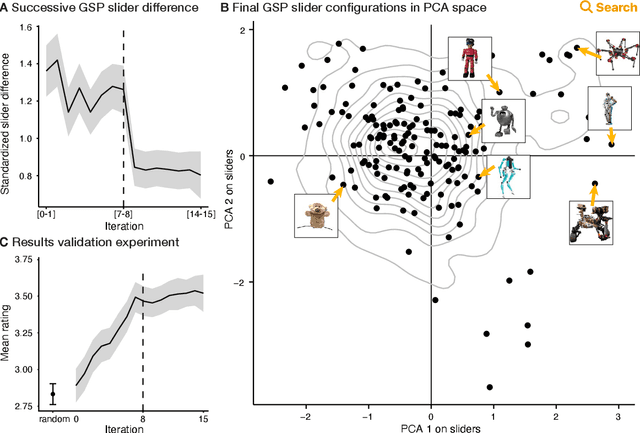
Speech is a natural interface for humans to interact with robots. Yet, aligning a robot's voice to its appearance is challenging due to the rich vocabulary of both modalities. Previous research has explored a few labels to describe robots and tested them on a limited number of robots and existing voices. Here, we develop a robot-voice creation tool followed by large-scale behavioral human experiments (N=2,505). First, participants collectively tune robotic voices to match 175 robot images using an adaptive human-in-the-loop pipeline. Then, participants describe their impression of the robot or their matched voice using another human-in-the-loop paradigm for open-ended labeling. The elicited taxonomy is then used to rate robot attributes and to predict the best voice for an unseen robot. We offer a web interface to aid engineers in customizing robot voices, demonstrating the synergy between cognitive science and machine learning for engineering tools.
Around the world in 60 words: A generative vocabulary test for online research
Feb 03, 2023Conducting experiments with diverse participants in their native languages can uncover insights into culture, cognition, and language that may not be revealed otherwise. However, conducting these experiments online makes it difficult to validate self-reported language proficiency. Furthermore, existing proficiency tests are small and cover only a few languages. We present an automated pipeline to generate vocabulary tests using text from Wikipedia. Our pipeline samples rare nouns and creates pseudowords with the same low-level statistics. Six behavioral experiments (N=236) in six countries and eight languages show that (a) our test can distinguish between native speakers of closely related languages, (b) the test is reliable ($r=0.82$), and (c) performance strongly correlates with existing tests (LexTale) and self-reports. We further show that test accuracy is negatively correlated with the linguistic distance between the tested and the native language. Our test, available in eight languages, can easily be extended to other languages.
What Language Reveals about Perception: Distilling Psychophysical Knowledge from Large Language Models
Feb 02, 2023Understanding the extent to which the perceptual world can be recovered from language is a fundamental problem in cognitive science. We reformulate this problem as that of distilling psychophysical information from text and show how this can be done by combining large language models (LLMs) with a classic psychophysical method based on similarity judgments. Specifically, we use the prompt auto-completion functionality of GPT3, a state-of-the-art LLM, to elicit similarity scores between stimuli and then apply multidimensional scaling to uncover their underlying psychological space. We test our approach on six perceptual domains and show that the elicited judgments strongly correlate with human data and successfully recover well-known psychophysical structures such as the color wheel and pitch spiral. We also explore meaningful divergences between LLM and human representations. Our work showcases how combining state-of-the-art machine models with well-known cognitive paradigms can shed new light on fundamental questions in perception and language research.
Words are all you need? Capturing human sensory similarity with textual descriptors
Jun 15, 2022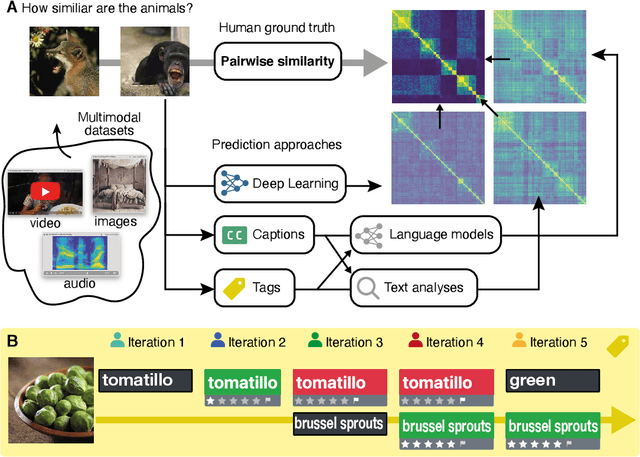
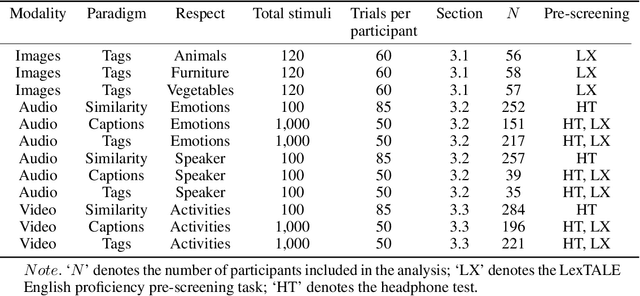

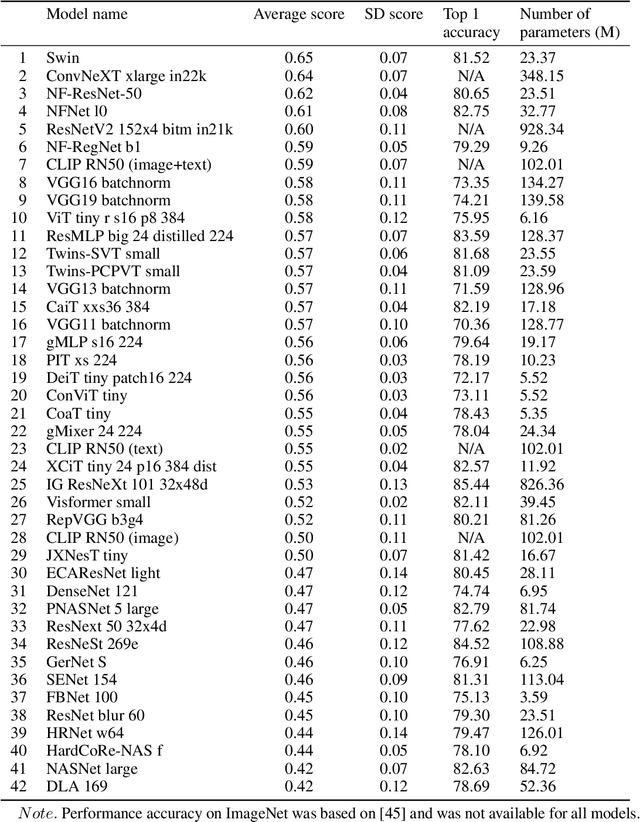
Recent advances in multimodal training use textual descriptions to significantly enhance machine understanding of images and videos. Yet, it remains unclear to what extent language can fully capture sensory experiences across different modalities. A well-established approach for characterizing sensory experiences relies on similarity judgments, namely, the degree to which people perceive two distinct stimuli as similar. We explore the relation between human similarity judgments and language in a series of large-scale behavioral studies ($N=1,823$ participants) across three modalities (images, audio, and video) and two types of text descriptors: simple word tags and free-text captions. In doing so, we introduce a novel adaptive pipeline for tag mining that is both efficient and domain-general. We show that our prediction pipeline based on text descriptors exhibits excellent performance, and we compare it against a comprehensive array of 611 baseline models based on vision-, audio-, and video-processing architectures. We further show that the degree to which textual descriptors and models predict human similarity varies across and within modalities. Taken together, these studies illustrate the value of integrating machine learning and cognitive science approaches to better understand the similarities and differences between human and machine representations. We present an interactive visualization at https://words-are-all-you-need.s3.amazonaws.com/index.html for exploring the similarity between stimuli as experienced by humans and different methods reported in the paper.
Bridging the prosody GAP: Genetic Algorithm with People to efficiently sample emotional prosody
May 10, 2022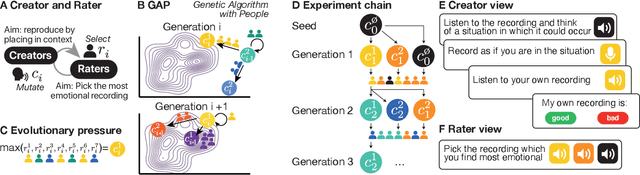

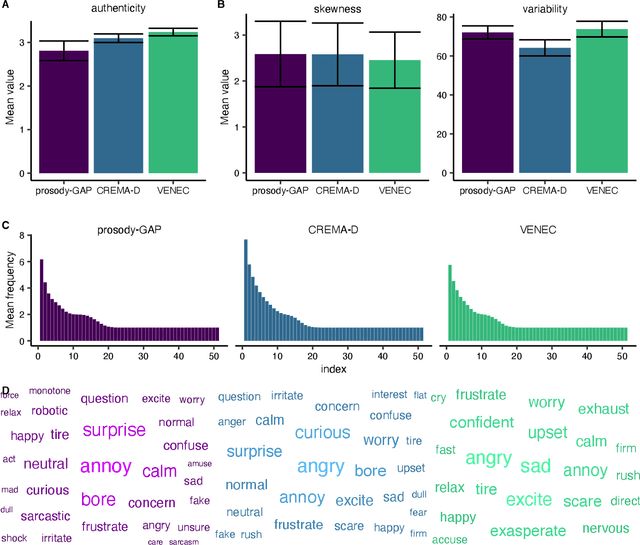
The human voice effectively communicates a range of emotions with nuanced variations in acoustics. Existing emotional speech corpora are limited in that they are either (a) highly curated to induce specific emotions with predefined categories that may not capture the full extent of emotional experiences, or (b) entangled in their semantic and prosodic cues, limiting the ability to study these cues separately. To overcome this challenge, we propose a new approach called 'Genetic Algorithm with People' (GAP), which integrates human decision and production into a genetic algorithm. In our design, we allow creators and raters to jointly optimize the emotional prosody over generations. We demonstrate that GAP can efficiently sample from the emotional speech space and capture a broad range of emotions, and show comparable results to state-of-the-art emotional speech corpora. GAP is language-independent and supports large crowd-sourcing, thus can support future large-scale cross-cultural research.
WavThruVec: Latent speech representation as intermediate features for neural speech synthesis
Mar 31, 2022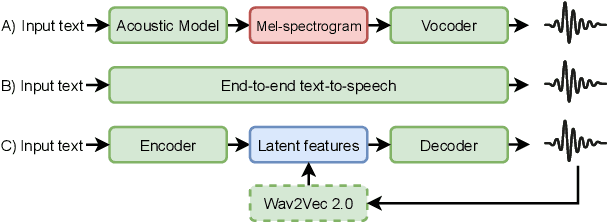

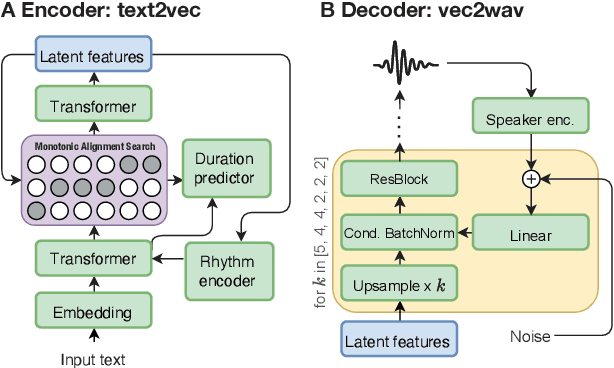
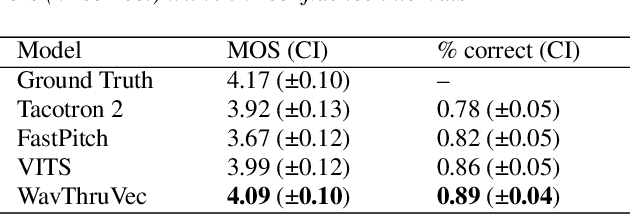
Recent advances in neural text-to-speech research have been dominated by two-stage pipelines utilizing low-level intermediate speech representation such as mel-spectrograms. However, such predetermined features are fundamentally limited, because they do not allow to exploit the full potential of a data-driven approach through learning hidden representations. For this reason, several end-to-end methods have been proposed. However, such models are harder to train and require a large number of high-quality recordings with transcriptions. Here, we propose WavThruVec - a two-stage architecture that resolves the bottleneck by using high-dimensional Wav2Vec 2.0 embeddings as intermediate speech representation. Since these hidden activations provide high-level linguistic features, they are more robust to noise. That allows us to utilize annotated speech datasets of a lower quality to train the first-stage module. At the same time, the second-stage component can be trained on large-scale untranscribed audio corpora, as Wav2Vec 2.0 embeddings are time-aligned and speaker-independent. This results in an increased generalization capability to out-of-vocabulary words, as well as to a better generalization to unseen speakers. We show that the proposed model not only matches the quality of state-of-the-art neural models, but also presents useful properties enabling tasks like voice conversion or zero-shot synthesis.
VoiceMe: Personalized voice generation in TTS
Mar 29, 2022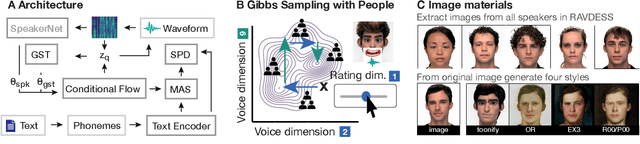


Novel text-to-speech systems can generate entirely new voices that were not seen during training. However, it remains a difficult task to efficiently create personalized voices from a high dimensional speaker space. In this work, we use speaker embeddings from a state-of-the-art speaker verification model (SpeakerNet) trained on thousands of speakers to condition a TTS model. We employ a human sampling paradigm to explore this speaker latent space. We show that users can create voices that fit well to photos of faces, art portraits, and cartoons. We recruit online participants to collectively manipulate the voice of a speaking face. We show that (1) a separate group of human raters confirms that the created voices match the faces, (2) speaker gender apparent from the face is well-recovered in the voice, and (3) people are consistently moving towards the real voice prototype for the given face. Our results demonstrate that this technology can be applied in a wide number of applications including character voice development in audiobooks and games, personalized speech assistants, and individual voices for people with speech impairment.