 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceMe: Personalized voice generation in TTS
Paper and Code
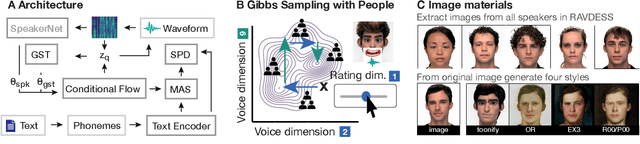


Novel text-to-speech systems can generate entirely new voices that were not seen during training. However, it remains a difficult task to efficiently create personalized voices from a high dimensional speaker space. In this work, we use speaker embeddings from a state-of-the-art speaker verification model (SpeakerNet) trained on thousands of speakers to condition a TTS model. We employ a human sampling paradigm to explore this speaker latent space. We show that users can create voices that fit well to photos of faces, art portraits, and cartoons. We recruit online participants to collectively manipulate the voice of a speaking face. We show that (1) a separate group of human raters confirms that the created voices match the faces, (2) speaker gender apparent from the face is well-recovered in the voice, and (3) people are consistently moving towards the real voice prototype for the given face. Our results demonstrate that this technology can be applied in a wide number of applications including character voice development in audiobooks and games, personalized speech assistants, and individual voices for people with speech impairment.