 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISCOVER: A Data-driven Interactive System for Comprehensive Observation, Visualization, and ExploRation of Human Behaviour
Jul 18, 2024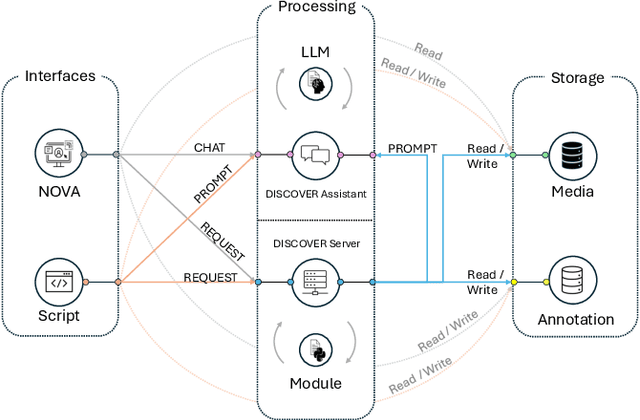
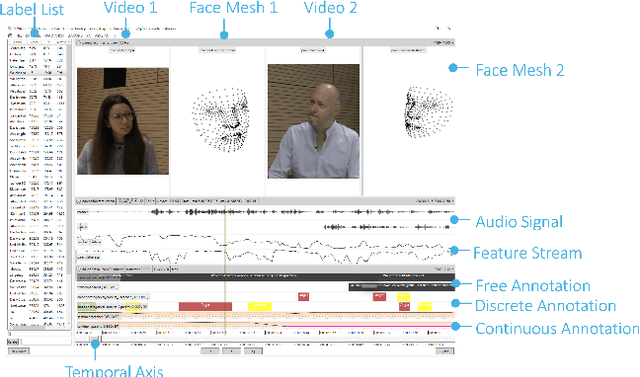
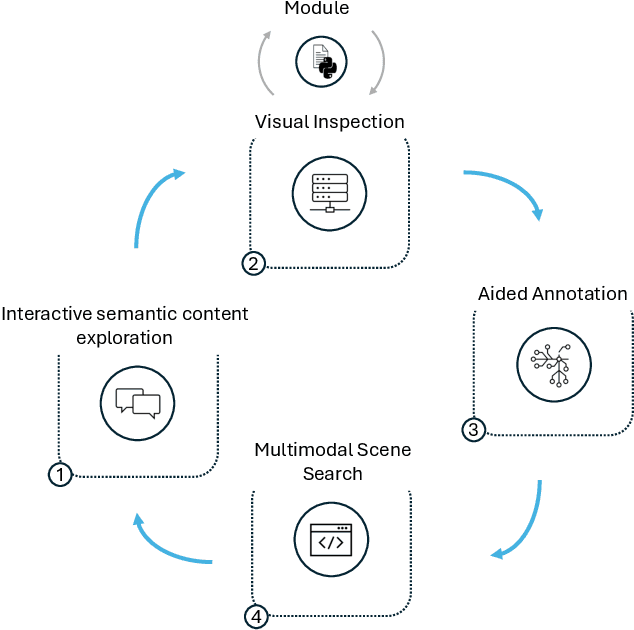
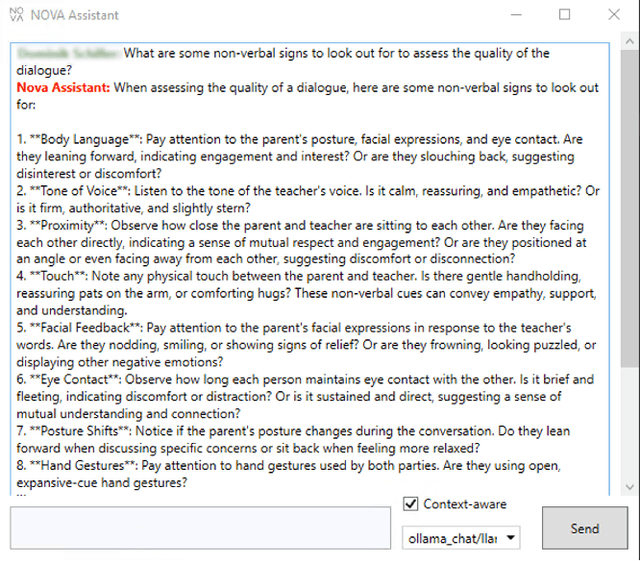
Understanding human behavior is a fundamental goal of social sciences, yet its analysis presents significant challenges. Conventional methodologies employed for the study of behavior, characterized by labor-intensive data collection processes and intricate analyses, frequently hinder comprehensive exploration due to their time and resource demands. In response to these challenges, computational models have proven to be promising tools that help researchers analyze large amounts of data by automatically identifying important behavioral indicators, such as social signals. However, the widespread adoption of such state-of-the-art computational models is impeded by their inherent complexity and the substantial computational resources necessary to run them, thereby constraining accessibility for researchers without technical expertise and adequate equipment. To address these barriers, we introduce DISCOVER -- a modular and flexible, yet user-friendly software framework specifically developed to streamline computational-driven data exploration for human behavior analysis. Our primary objective is to democratize access to advanced computational methodologies, thereby enabling researchers across disciplines to engage in detailed behavioral analysis without the need for extensive technical proficiency. In this paper, we demonstrate the capabilities of DISCOVER using four exemplary data exploration workflows that build on each other: Interactive Semantic Content Exploration, Visual Inspection, Aided Annotation, and Multimodal Scene Search. By illustrating these workflows, we aim to emphasize the versatility and accessibility of DISCOVER as a comprehensive framework and propose a set of blueprints that can serve as a general starting point for exploratory data analysis.
Faces of Experimental Pain: Transferability of Deep Learned Heat Pain Features to Electrical Pain
Jun 17, 2024



The limited size of pain datasets are a challenge in developing robust deep learning models for pain recognition. Transfer learning approaches are often employed in these scenarios. In this study, we investigate whether deep learned feature representation for one type of experimentally induced pain can be transferred to another. Participating in the AI4Pain challenge, our goal is to classify three levels of pain (No-Pain, Low-Pain, High-Pain). The challenge dataset contains data collected from 65 participants undergoing varying intensities of electrical pain. We utilize the video recording from the dataset to investigate the transferability of deep learned heat pain model to electrical pain. In our proposed approach, we leverage an existing heat pain convolutional neural network (CNN) - trained on BioVid dataset - as a feature extractor. The images from the challenge dataset are inputted to the pre-trained heat pain CNN to obtain feature vectors. These feature vectors are used to train two machine learning models: a simple feed-forward neural network and a long short-term memory (LSTM) network. Our approach was tested using the dataset's predefined training, validation, and testing splits. Our models outperformed the baseline of the challenge on both the validation and tests sets, highlighting the potential of models trained on other pain datasets for reliable feature extraction.
The AffectToolbox: Affect Analysis for Everyone
Feb 23, 2024



In the field of affective computing, where research continually advances at a rapid pace, the demand for user-friendly tools has become increasingly apparent. In this paper, we present the AffectToolbox, a novel software system that aims to support researchers in developing affect-sensitive studies and prototypes. The proposed system addresses the challenges posed by existing frameworks, which often require profound programming knowledge and cater primarily to power-users or skilled developers. Aiming to facilitate ease of use, the AffectToolbox requires no programming knowledge and offers its functionality to reliably analyze the affective state of users through an accessible graphical user interface. The architecture encompasses a variety of models for emotion recognition on multiple affective channels and modalities, as well as an elaborate fusion system to merge multi-modal assessments into a unified result. The entire system is open-sourced and will be publicly available to ensure easy integration into more complex applications through a well-structured, Python-based code base - therefore marking a substantial contribution toward advancing affective computing research and fostering a more collaborative and inclusive environment within this interdisciplinary field.
MultiMediate'23: Engagement Estimation and Bodily Behaviour Recognition in Social Interactions
Aug 16, 2023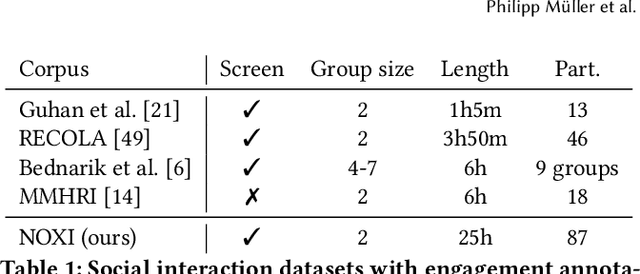
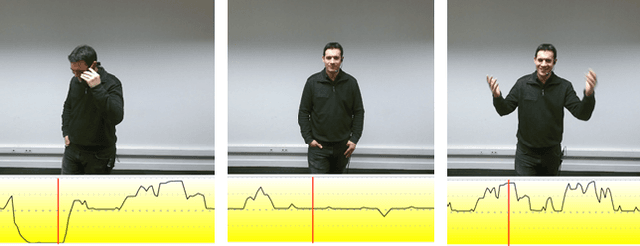

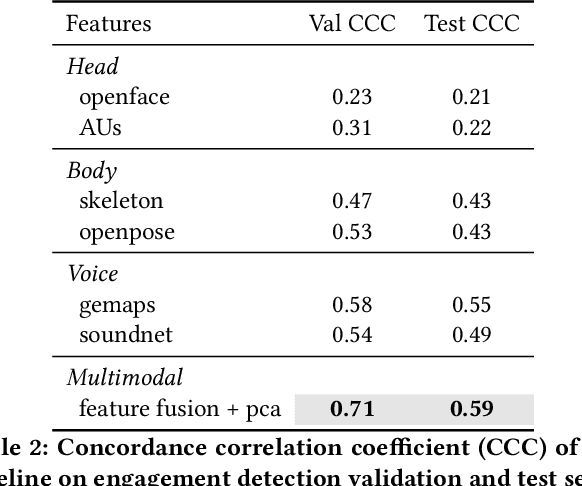
Automatic analysis of human behaviour is a fundamental prerequisite for the creation of machines that can effectively interact with- and support humans in social interactions. In MultiMediate'23, we address two key human social behaviour analysis tasks for the first time in a controlled challenge: engagement estimation and bodily behaviour recognition in social interactions. This paper describes the MultiMediate'23 challenge and presents novel sets of annotations for both tasks. For engagement estimation we collected novel annotations on the NOvice eXpert Interaction (NOXI) database. For bodily behaviour recognition, we annotated test recordings of the MPIIGroupInteraction corpus with the BBSI annotation scheme. In addition, we present baseline results for both challenge tasks.
An Efficient Multitask Learning Architecture for Affective Vocal Burst Analysis
Sep 28, 2022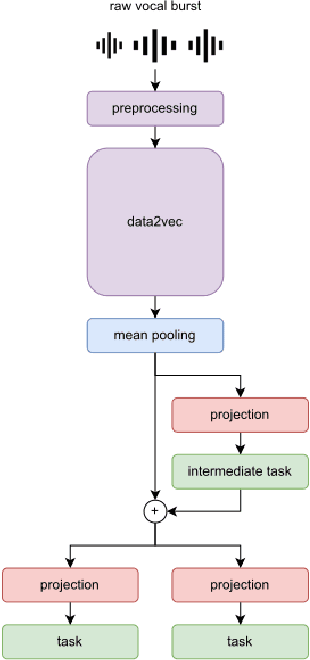
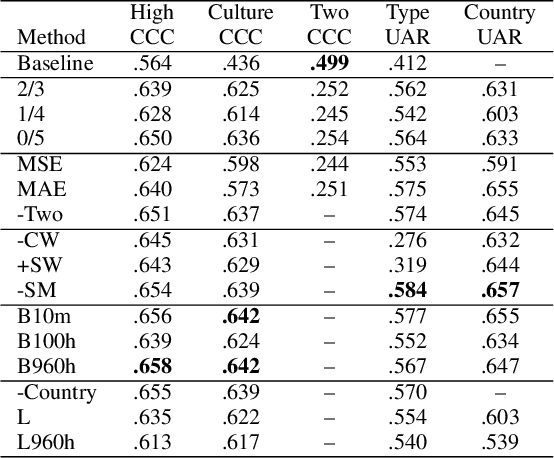
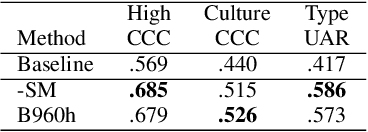
Affective speech analysis is an ongoing topic of research. A relatively new problem in this field is the analysis of vocal bursts, which are nonverbal vocalisations such as laughs or sighs. Current state-of-the-art approaches to address affective vocal burst analysis are mostly based on wav2vec2 or HuBERT features. In this paper, we investigate the use of the wav2vec successor data2vec in combination with a multitask learning pipeline to tackle different analysis problems at once. To assess the performance of our efficient multitask learning architecture, we participate in the 2022 ACII Affective Vocal Burst Challenge, showing that our approach substantially outperforms the baseline established there in three different subtasks.
Intercategorical Label Interpolation for Emotional Face Generation with Conditional Generative Adversarial Networks
Apr 26, 2022



Generative adversarial networks offer the possibility to generate deceptively real images that are almost indistinguishable from actual photographs. Such systems however rely on the presence of large datasets to realistically replicate the corresponding domain. This is especially a problem if not only random new images are to be generated, but specific (continuous) features are to be co-modeled. A particularly important use case in \emph{Human-Computer Interaction} (HCI) research is the generation of emotional images of human faces, which can be used for various use cases, such as the automatic generation of avatars. The problem hereby lies in the availability of training data. Most suitable datasets for this task rely on categorical emotion models and therefore feature only discrete annotation labels. This greatly hinders the learning and modeling of smooth transitions between displayed affective states. To overcome this challenge, we explore the potential of label interpolation to enhance networks trained on categorical datasets with the ability to generate images conditioned on continuous features.
VoiceMe: Personalized voice generation in TTS
Mar 29, 2022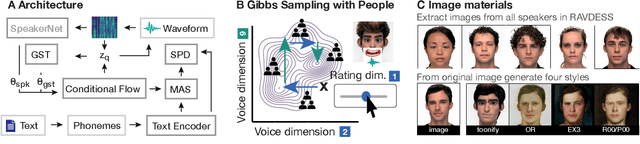


Novel text-to-speech systems can generate entirely new voices that were not seen during training. However, it remains a difficult task to efficiently create personalized voices from a high dimensional speaker space. In this work, we use speaker embeddings from a state-of-the-art speaker verification model (SpeakerNet) trained on thousands of speakers to condition a TTS model. We employ a human sampling paradigm to explore this speaker latent space. We show that users can create voices that fit well to photos of faces, art portraits, and cartoons. We recruit online participants to collectively manipulate the voice of a speaking face. We show that (1) a separate group of human raters confirms that the created voices match the faces, (2) speaker gender apparent from the face is well-recovered in the voice, and (3) people are consistently moving towards the real voice prototype for the given face. Our results demonstrate that this technology can be applied in a wide number of applications including character voice development in audiobooks and games, personalized speech assistants, and individual voices for people with speech impairment.
Exploring emotional prototypes in a high dimensional TTS latent space
May 05, 2021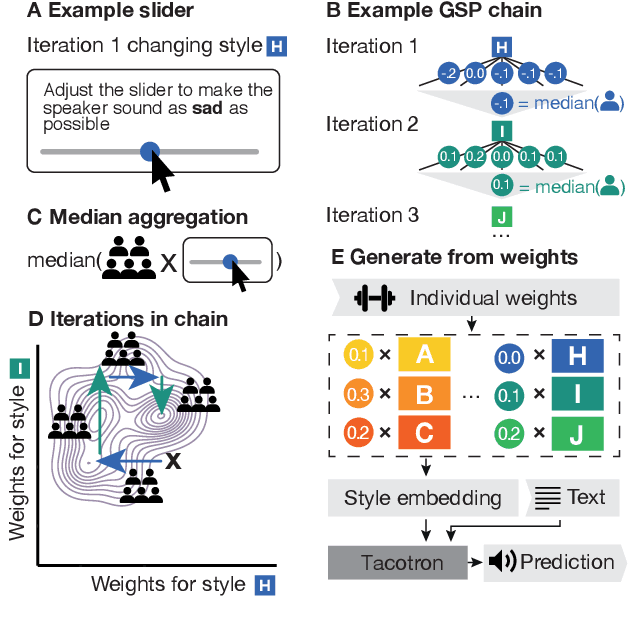
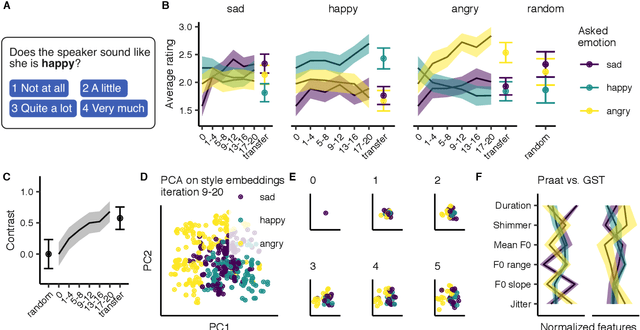
Recent TTS systems are able to generate prosodically varied and realistic speech. However, it is unclear how this prosodic variation contributes to the perception of speakers' emotional states. Here we use the recent psychological paradigm 'Gibbs Sampling with People' to search the prosodic latent space in a trained GST Tacotron model to explore prototypes of emotional prosody. Participants are recruited online and collectively manipulate the latent space of the generative speech model in a sequentially adaptive way so that the stimulus presented to one group of participants is determined by the response of the previous groups. We demonstrate that (1) particular regions of the model's latent space are reliably associated with particular emotions, (2) the resulting emotional prototypes are well-recognized by a separate group of human raters, and (3) these emotional prototypes can be effectively transferred to new sentences. Collectively, these experiments demonstrate a novel approach to the understanding of emotional speech by providing a tool to explore the relation between the latent space of generative models and human semantics.
Do Deep Neural Networks Forget Facial Action Units? -- Exploring the Effects of Transfer Learning in Health Related Facial Expression Recognition
Apr 15, 2021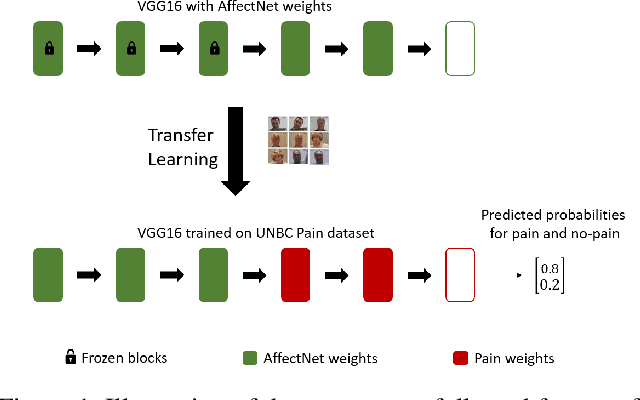

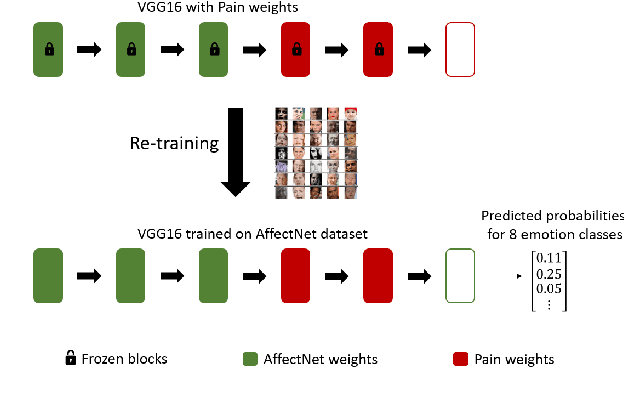

In this paper, we present a process to investigate the effects of transfer learning for automatic facial expression recognition from emotions to pain. To this end, we first train a VGG16 convolutional neural network to automatically discern between eight categorical emotions. We then fine-tune successively larger parts of this network to learn suitable representations for the task of automatic pain recognition. Subsequently, we apply those fine-tuned representations again to the original task of emotion recognition to further investigate the differences in performance between the models. In the second step, we use Layer-wise Relevance Propagation to analyze predictions of the model that have been predicted correctly previously but are now wrongly classified. Based on this analysis, we rely on the visual inspection of a human observer to generate hypotheses about what has been forgotten by the model. Finally, we test those hypotheses quantitatively utilizing concept embedding analysis methods. Our results show that the network, which was fully fine-tuned for pain recognition, indeed payed less attention to two action units that are relevant for expression recognition but not for pain recognition.
Embedded Emotions -- A Data Driven Approach to Learn Transferable Feature Representations from Raw Speech Input for Emotion Recognition
Sep 30, 2020
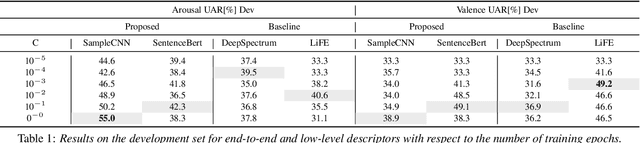


Traditional approaches to automatic emotion recognition are relying on the application of handcrafted features. More recently however the advent of deep learning enabled algorithms to learn meaningful representations of input data automatically. In this paper, we investigate the applicability of transferring knowledge learned from large text and audio corpora to the task of automatic emotion recognition. To evaluate the practicability of our approach, we are taking part in this year's Interspeech ComParE Elderly Emotion Sub-Challenge, where the goal is to classify spoken narratives of elderly people with respect to the emotion of the speaker. Our results show that the learned feature representations can be effectively applied for classifying emotions from spoken language. We found the performance of the features extracted from the audio signal to be not as consistent as those that have been extracted from the transcripts. While the acoustic features achieved best in class results on the development set, when compared to the baseline systems, their performance dropped considerably on the test set of the challenge. The features extracted from the text form, however, are showing promising results on both sets and are outperforming the official baseline by 5.7 percentage points unweighted average recall.