 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ACM Multimedia 2022 Computational Paralinguistics Challenge: Vocalisations, Stuttering, Activity, & Mosquitoes
May 13, 2022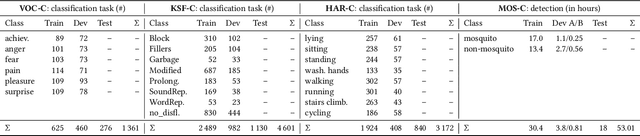
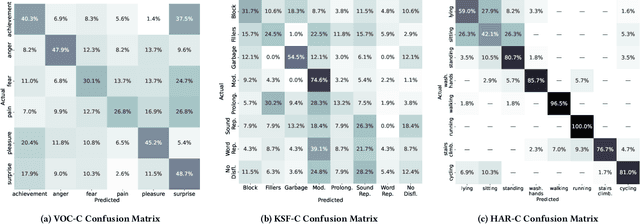

The ACM Multimedia 2022 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the Vocalisations and Stuttering Sub-Challenges, a classification on human non-verbal vocalisations and speech has to be made; the Activity Sub-Challenge aims at beyond-audio human activity recognition from smartwatch sensor data; and in the Mosquitoes Sub-Challenge, mosquitoes need to be detected. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the usual ComPaRE and BoAW features, the auDeep toolkit, and deep feature extraction from pre-trained CNNs using the DeepSpectRum toolkit; in addition, we add end-to-end sequential modelling, and a log-mel-128-BNN.
Exploring emotional prototypes in a high dimensional TTS latent space
May 05, 2021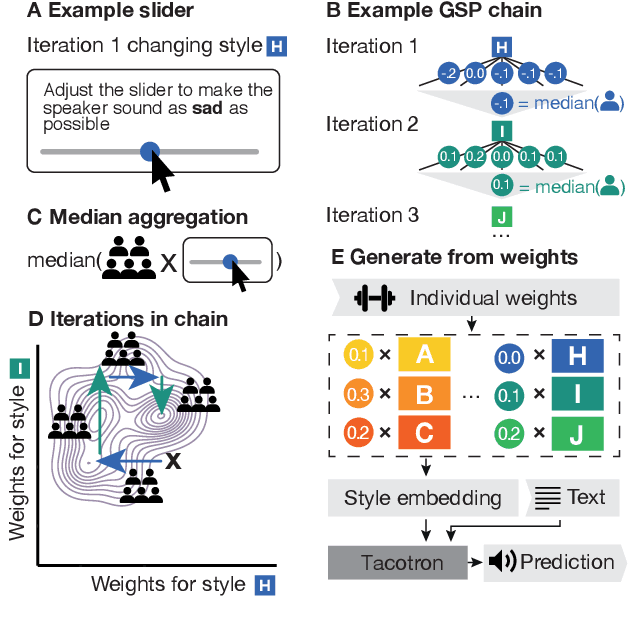
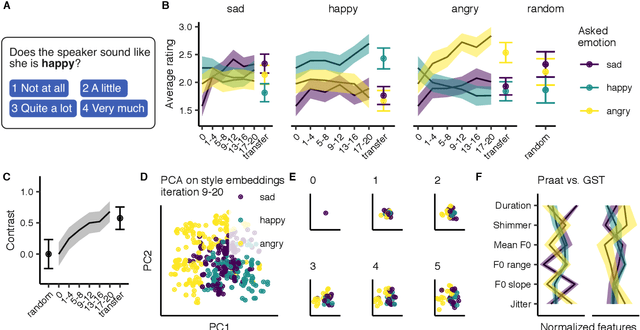
Recent TTS systems are able to generate prosodically varied and realistic speech. However, it is unclear how this prosodic variation contributes to the perception of speakers' emotional states. Here we use the recent psychological paradigm 'Gibbs Sampling with People' to search the prosodic latent space in a trained GST Tacotron model to explore prototypes of emotional prosody. Participants are recruited online and collectively manipulate the latent space of the generative speech model in a sequentially adaptive way so that the stimulus presented to one group of participants is determined by the response of the previous groups. We demonstrate that (1) particular regions of the model's latent space are reliably associated with particular emotions, (2) the resulting emotional prototypes are well-recognized by a separate group of human raters, and (3) these emotional prototypes can be effectively transferred to new sentences. Collectively, these experiments demonstrate a novel approach to the understanding of emotional speech by providing a tool to explore the relation between the latent space of generative models and human semantics.
Gibbs Sampling with People
Aug 06, 2020
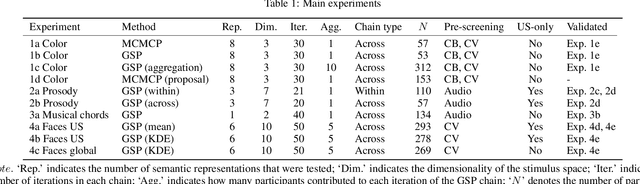
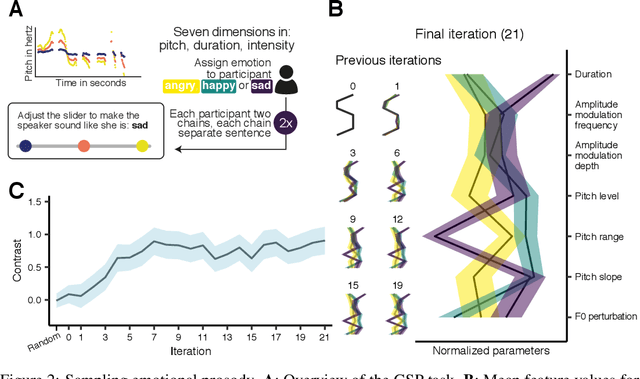
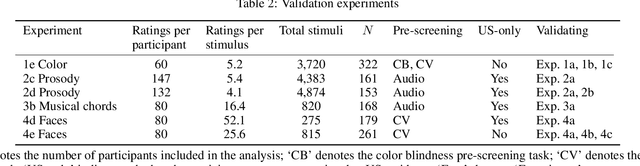
A core problem in cognitive science and machine learning is to understand how humans derive semantic representations from perceptual objects, such as color from an apple, pleasantness from a musical chord, or trustworthiness from a face. Markov Chain Monte Carlo with People (MCMCP) is a prominent method for studying such representations, in which participants are presented with binary choice trials constructed such that the decisions follow a Markov Chain Monte Carlo acceptance rule. However, MCMCP's binary choice paradigm generates relatively little information per trial, and its local proposal function makes it slow to explore the parameter space and find the modes of the distribution. Here we therefore generalize MCMCP to a continuous-sampling paradigm, where in each iteration the participant uses a slider to continuously manipulate a single stimulus dimension to optimize a given criterion such as 'pleasantness'. We formulate both methods from a utility-theory perspective, and show that the new method can be interpreted as 'Gibbs Sampling with People' (GSP). Further, we introduce an aggregation parameter to the transition step, and show that this parameter can be manipulated to flexibly shift between Gibbs sampling and deterministic optimization. In an initial study, we show GSP clearly outperforming MCMCP; we then show that GSP provides novel and interpretable results in three other domains, namely musical chords, vocal emotions, and faces. We validate these results through large-scale perceptual rating experiments. The final experiments combine GSP with a state-of-the-art image synthesis network (StyleGAN) and a recent network interpretability technique (GANSpace), enabling GSP to efficiently explore high-dimensional perceptual spaces, and demonstrating how GSP can be a powerful tool for jointly characterizing semantic representations in humans and machines.