 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconstructing Jazz Piano Style Using Machine Learning
Apr 07, 2025Artistic style has been studied for centuries, and recent advances in machine learning create new possibilities for understanding it computationally. However, ensuring that machine-learning models produce insights aligned with the interests of practitioners and critics remains a significant challenge. Here, we focus on musical style, which benefits from a rich theoretical and mathematical analysis tradition. We train a variety of supervised-learning models to identify 20 iconic jazz musicians across a carefully curated dataset of 84 hours of recordings, and interpret their decision-making processes. Our models include a novel multi-input architecture that enables four musical domains (melody, harmony, rhythm, and dynamics) to be analysed separately. These models enable us to address fundamental questions in music theory and also advance the state-of-the-art in music performer identification (94% accuracy across 20 classes). We release open-source implementations of our models and an accompanying web application for exploring musical styles.
VoiceMe: Personalized voice generation in TTS
Mar 29, 2022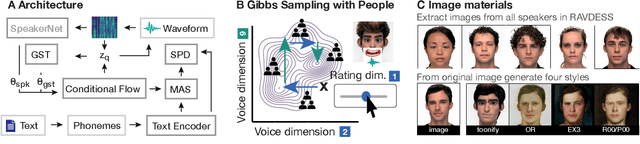


Novel text-to-speech systems can generate entirely new voices that were not seen during training. However, it remains a difficult task to efficiently create personalized voices from a high dimensional speaker space. In this work, we use speaker embeddings from a state-of-the-art speaker verification model (SpeakerNet) trained on thousands of speakers to condition a TTS model. We employ a human sampling paradigm to explore this speaker latent space. We show that users can create voices that fit well to photos of faces, art portraits, and cartoons. We recruit online participants to collectively manipulate the voice of a speaking face. We show that (1) a separate group of human raters confirms that the created voices match the faces, (2) speaker gender apparent from the face is well-recovered in the voice, and (3) people are consistently moving towards the real voice prototype for the given face. Our results demonstrate that this technology can be applied in a wide number of applications including character voice development in audiobooks and games, personalized speech assistants, and individual voices for people with speech impairment.
Exploring emotional prototypes in a high dimensional TTS latent space
May 05, 2021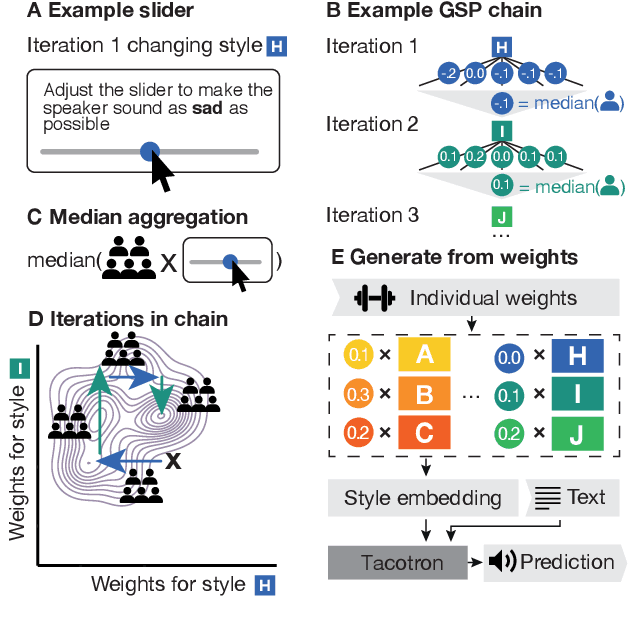
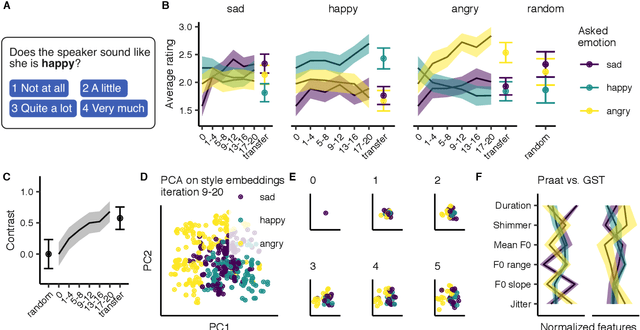
Recent TTS systems are able to generate prosodically varied and realistic speech. However, it is unclear how this prosodic variation contributes to the perception of speakers' emotional states. Here we use the recent psychological paradigm 'Gibbs Sampling with People' to search the prosodic latent space in a trained GST Tacotron model to explore prototypes of emotional prosody. Participants are recruited online and collectively manipulate the latent space of the generative speech model in a sequentially adaptive way so that the stimulus presented to one group of participants is determined by the response of the previous groups. We demonstrate that (1) particular regions of the model's latent space are reliably associated with particular emotions, (2) the resulting emotional prototypes are well-recognized by a separate group of human raters, and (3) these emotional prototypes can be effectively transferred to new sentences. Collectively, these experiments demonstrate a novel approach to the understanding of emotional speech by providing a tool to explore the relation between the latent space of generative models and human semantics.
Gibbs Sampling with People
Aug 06, 2020
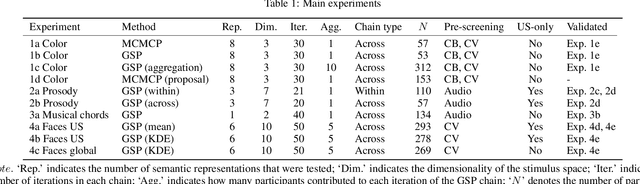
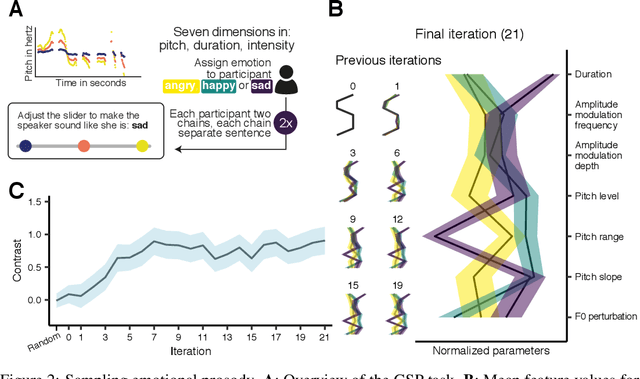
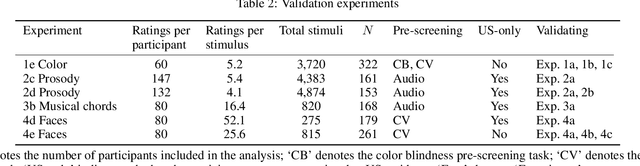
A core problem in cognitive science and machine learning is to understand how humans derive semantic representations from perceptual objects, such as color from an apple, pleasantness from a musical chord, or trustworthiness from a face. Markov Chain Monte Carlo with People (MCMCP) is a prominent method for studying such representations, in which participants are presented with binary choice trials constructed such that the decisions follow a Markov Chain Monte Carlo acceptance rule. However, MCMCP's binary choice paradigm generates relatively little information per trial, and its local proposal function makes it slow to explore the parameter space and find the modes of the distribution. Here we therefore generalize MCMCP to a continuous-sampling paradigm, where in each iteration the participant uses a slider to continuously manipulate a single stimulus dimension to optimize a given criterion such as 'pleasantness'. We formulate both methods from a utility-theory perspective, and show that the new method can be interpreted as 'Gibbs Sampling with People' (GSP). Further, we introduce an aggregation parameter to the transition step, and show that this parameter can be manipulated to flexibly shift between Gibbs sampling and deterministic optimization. In an initial study, we show GSP clearly outperforming MCMCP; we then show that GSP provides novel and interpretable results in three other domains, namely musical chords, vocal emotions, and faces. We validate these results through large-scale perceptual rating experiments. The final experiments combine GSP with a state-of-the-art image synthesis network (StyleGAN) and a recent network interpretability technique (GANSpace), enabling GSP to efficiently explore high-dimensional perceptual spaces, and demonstrating how GSP can be a powerful tool for jointly characterizing semantic representations in humans and machines.