 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNAC: Multi-Scale Neural Audio Codec
Oct 18, 2024



Neural audio codecs have recently gained popularity because they can represent audio signals with high fidelity at very low bitrates, making it feasible to use language modeling approaches for audio generation and understanding. Residual Vector Quantization (RVQ) has become the standard technique for neural audio compression using a cascade of VQ codebooks. This paper proposes the Multi-Scale Neural Audio Codec, a simple extension of RVQ where the quantizers can operate at different temporal resolutions. By applying a hierarchy of quantizers at variable frame rates, the codec adapts to the audio structure across multiple timescales. This leads to more efficient compression, as demonstrated by extensive objective and subjective evaluations. The code and model weights are open-sourced at https://github.com/hubertsiuzdak/snac.
Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis
Jun 01, 2023



Recent advancements in neural vocoding are predominantly driven by Generative Adversarial Networks (GANs) operating in the time-domain. While effective, this approach neglects the inductive bias offered by time-frequency representations, resulting in reduntant and computionally-intensive upsampling operations. Fourier-based time-frequency representation is an appealing alternative, aligning more accurately with human auditory perception, and benefitting from well-established fast algorithms for its computation. Nevertheless, direct reconstruction of complex-valued spectrograms has been historically problematic, primarily due to phase recovery issues. This study seeks to close this gap by presenting Vocos, a new model that addresses the key challenges of modeling spectral coefficients. Vocos demonstrates improved computational efficiency, achieving an order of magnitude increase in speed compared to prevailing time-domain neural vocoding approaches. As shown by objective evaluation, Vocos not only matches state-of-the-art audio quality, but thanks to frequency-aware generator, also effectively mitigates the periodicity issues frequently associated with time-domain GANs. The source code and model weights have been open-sourced at https://github.com/charactr-platform/vocos.
WavThruVec: Latent speech representation as intermediate features for neural speech synthesis
Mar 31, 2022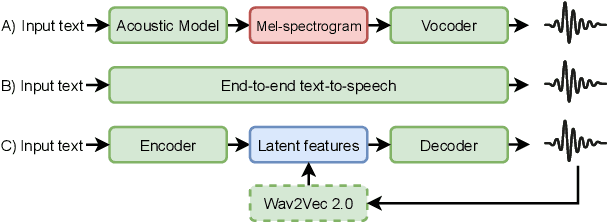

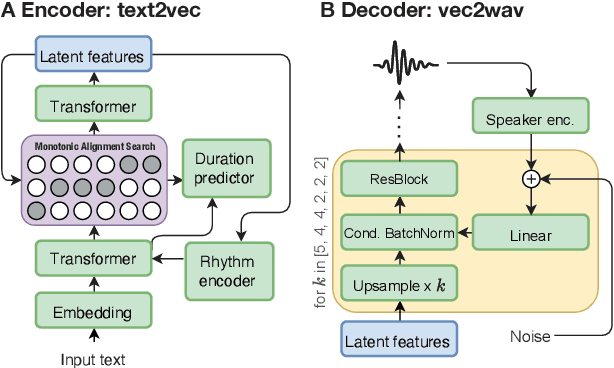
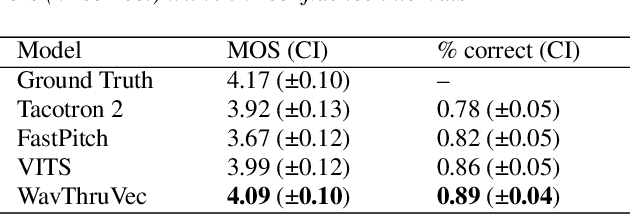
Recent advances in neural text-to-speech research have been dominated by two-stage pipelines utilizing low-level intermediate speech representation such as mel-spectrograms. However, such predetermined features are fundamentally limited, because they do not allow to exploit the full potential of a data-driven approach through learning hidden representations. For this reason, several end-to-end methods have been proposed. However, such models are harder to train and require a large number of high-quality recordings with transcriptions. Here, we propose WavThruVec - a two-stage architecture that resolves the bottleneck by using high-dimensional Wav2Vec 2.0 embeddings as intermediate speech representation. Since these hidden activations provide high-level linguistic features, they are more robust to noise. That allows us to utilize annotated speech datasets of a lower quality to train the first-stage module. At the same time, the second-stage component can be trained on large-scale untranscribed audio corpora, as Wav2Vec 2.0 embeddings are time-aligned and speaker-independent. This results in an increased generalization capability to out-of-vocabulary words, as well as to a better generalization to unseen speakers. We show that the proposed model not only matches the quality of state-of-the-art neural models, but also presents useful properties enabling tasks like voice conversion or zero-shot synthesis.
VoiceMe: Personalized voice generation in TTS
Mar 29, 2022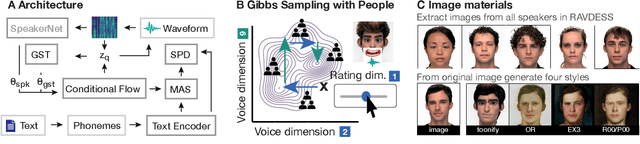


Novel text-to-speech systems can generate entirely new voices that were not seen during training. However, it remains a difficult task to efficiently create personalized voices from a high dimensional speaker space. In this work, we use speaker embeddings from a state-of-the-art speaker verification model (SpeakerNet) trained on thousands of speakers to condition a TTS model. We employ a human sampling paradigm to explore this speaker latent space. We show that users can create voices that fit well to photos of faces, art portraits, and cartoons. We recruit online participants to collectively manipulate the voice of a speaking face. We show that (1) a separate group of human raters confirms that the created voices match the faces, (2) speaker gender apparent from the face is well-recovered in the voice, and (3) people are consistently moving towards the real voice prototype for the given face. Our results demonstrate that this technology can be applied in a wide number of applications including character voice development in audiobooks and games, personalized speech assistants, and individual voices for people with speech impairment.