 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Computational Complexity of Circuit Discovery for Inner Interpretability
Oct 10, 2024



Many proposed applications of neural networks in machine learning, cognitive/brain science, and society hinge on the feasibility of inner interpretability via circuit discovery. This calls for empirical and theoretical explorations of viable algorithmic options. Despite advances in the design and testing of heuristics, there are concerns about their scalability and faithfulness at a time when we lack understanding of the complexity properties of the problems they are deployed to solve. To address this, we study circuit discovery with classical and parameterized computational complexity theory: (1) we describe a conceptual scaffolding to reason about circuit finding queries in terms of affordances for description, explanation, prediction and control; (2) we formalize a comprehensive set of queries that capture mechanistic explanation, and propose a formal framework for their analysis; (3) we use it to settle the complexity of many query variants and relaxations of practical interest on multi-layer perceptrons (part of, e.g., transformers). Our findings reveal a challenging complexity landscape. Many queries are intractable (NP-hard, $\Sigma^p_2$-hard), remain fixed-parameter intractable (W[1]-hard) when constraining model/circuit features (e.g., depth), and are inapproximable under additive, multiplicative, and probabilistic approximation schemes. To navigate this landscape, we prove there exist transformations to tackle some of these hard problems (NP- vs. $\Sigma^p_2$-complete) with better-understood heuristics, and prove the tractability (PTIME) or fixed-parameter tractability (FPT) of more modest queries which retain useful affordances. This framework allows us to understand the scope and limits of interpretability queries, explore viable options, and compare their resource demands among existing and future architectures.
Position Paper: An Inner Interpretability Framework for AI Inspired by Lessons from Cognitive Neuroscience
Jun 03, 2024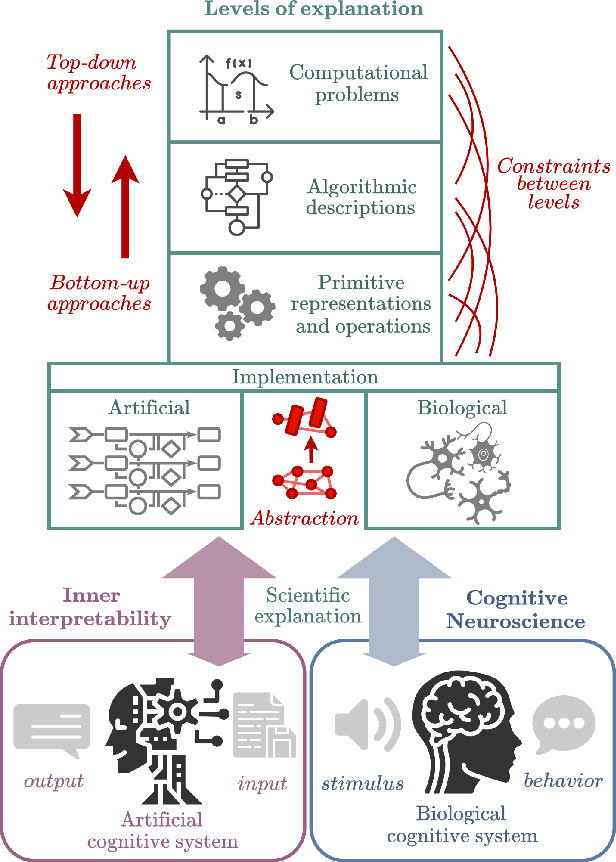
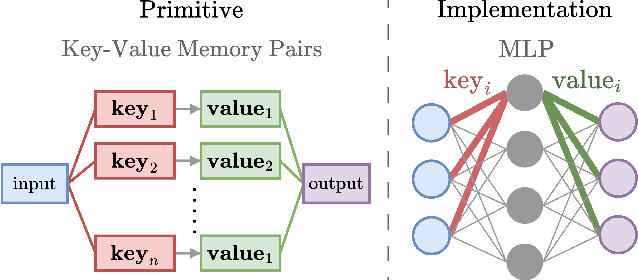
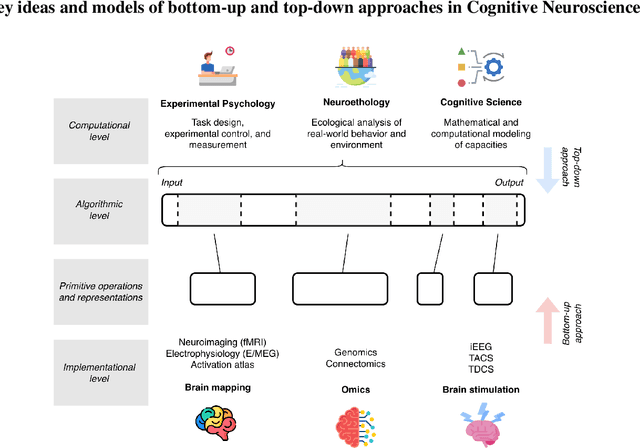
Inner Interpretability is a promising emerging field tasked with uncovering the inner mechanisms of AI systems, though how to develop these mechanistic theories is still much debated. Moreover, recent critiques raise issues that question its usefulness to advance the broader goals of AI. However, it has been overlooked that these issues resemble those that have been grappled with in another field: Cognitive Neuroscience. Here we draw the relevant connections and highlight lessons that can be transferred productively between fields. Based on these, we propose a general conceptual framework and give concrete methodological strategies for building mechanistic explanations in AI inner interpretability research. With this conceptual framework, Inner Interpretability can fend off critiques and position itself on a productive path to explain AI systems.
MindSet: Vision. A toolbox for testing DNNs on key psychological experiments
Apr 08, 2024



Multiple benchmarks have been developed to assess the alignment between deep neural networks (DNNs) and human vision. In almost all cases these benchmarks are observational in the sense they are composed of behavioural and brain responses to naturalistic images that have not been manipulated to test hypotheses regarding how DNNs or humans perceive and identify objects. Here we introduce the toolbox MindSet: Vision, consisting of a collection of image datasets and related scripts designed to test DNNs on 30 psychological findings. In all experimental conditions, the stimuli are systematically manipulated to test specific hypotheses regarding human visual perception and object recognition. In addition to providing pre-generated datasets of images, we provide code to regenerate these datasets, offering many configurable parameters which greatly extend the dataset versatility for different research contexts, and code to facilitate the testing of DNNs on these image datasets using three different methods (similarity judgments, out-of-distribution classification, and decoder method), accessible at https://github.com/MindSetVision/mindset-vision. We test ResNet-152 on each of these methods as an example of how the toolbox can be used.
Successes and critical failures of neural networks in capturing human-like speech recognition
Apr 06, 2022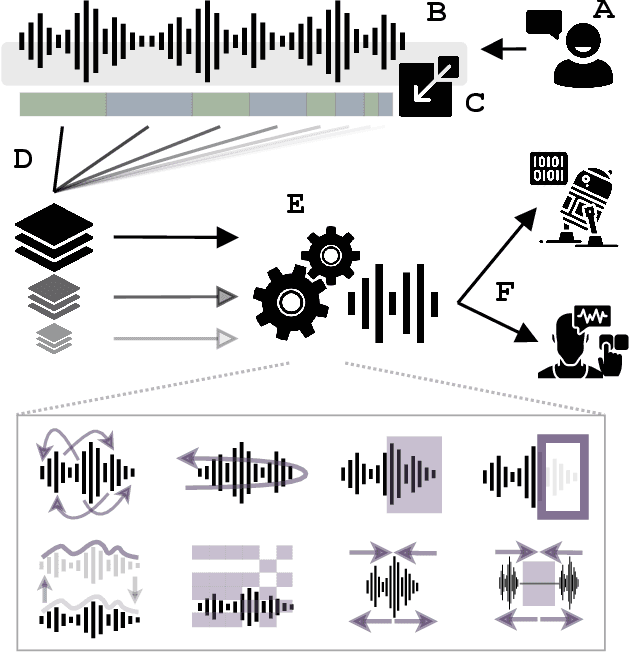
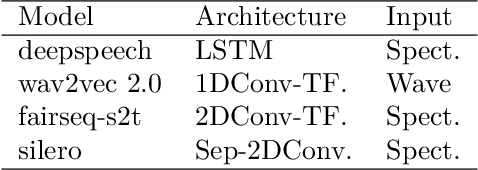
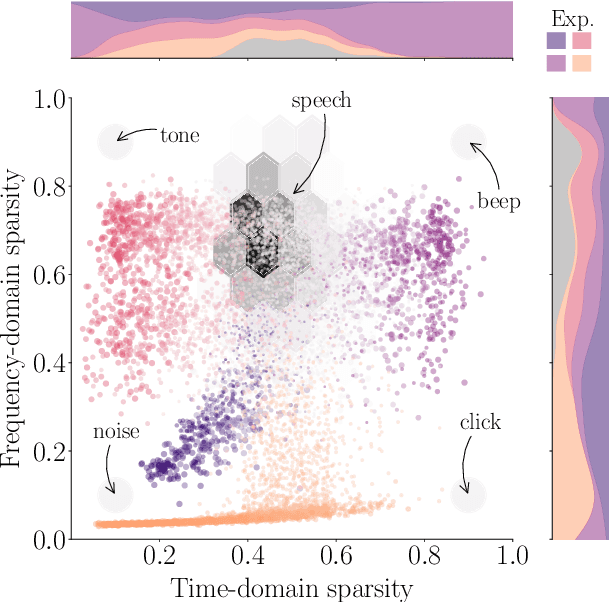
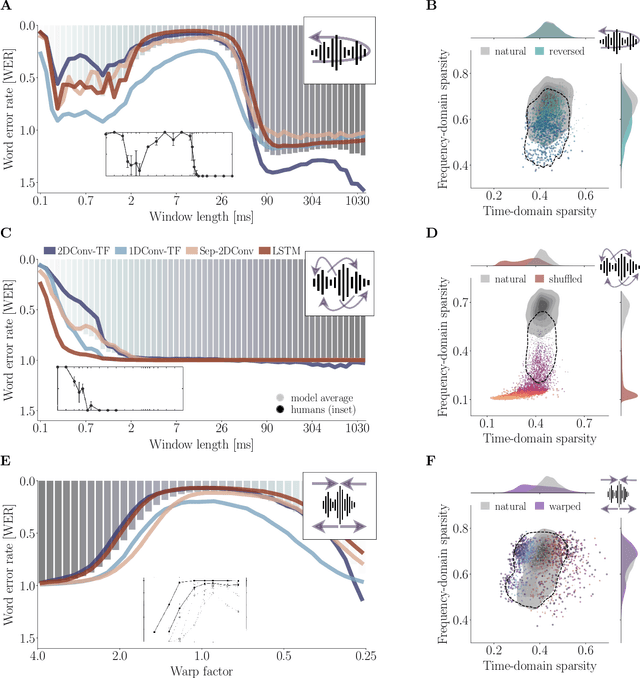
Natural and artificial audition can in principle evolve different solutions to a given problem. The constraints of the task, however, can nudge the cognitive science and engineering of audition to qualitatively converge, suggesting that a closer mutual examination would improve artificial hearing systems and process models of the mind and brain. Speech recognition - an area ripe for such exploration - is inherently robust in humans to a number transformations at various spectrotemporal granularities. To what extent are these robustness profiles accounted for by high-performing neural network systems? We bring together experiments in speech recognition under a single synthesis framework to evaluate state-of-the-art neural networks as stimulus-computable, optimized observers. In a series of experiments, we (1) clarify how influential speech manipulations in the literature relate to each other and to natural speech, (2) show the granularities at which machines exhibit out-of-distribution robustness, reproducing classical perceptual phenomena in humans, (3) identify the specific conditions where model predictions of human performance differ, and (4) demonstrate a crucial failure of all artificial systems to perceptually recover where humans do, suggesting a key specification for theory and model building. These findings encourage a tighter synergy between the cognitive science and engineering of audition.
Computational Complexity of Segmentation
Feb 06, 2022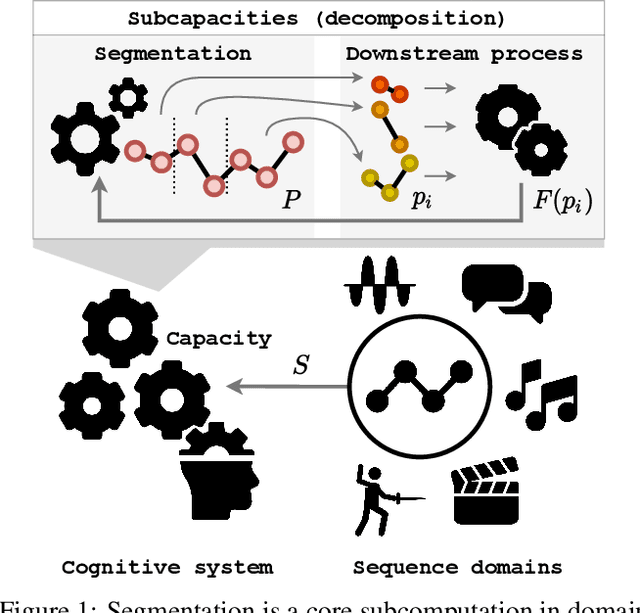
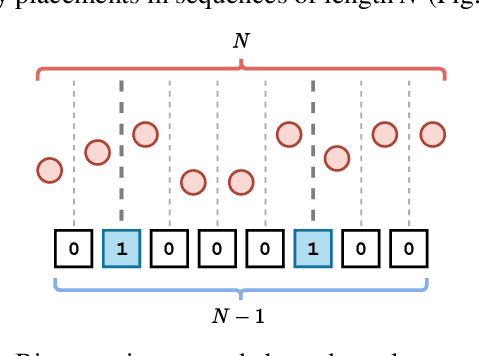
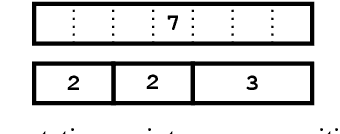
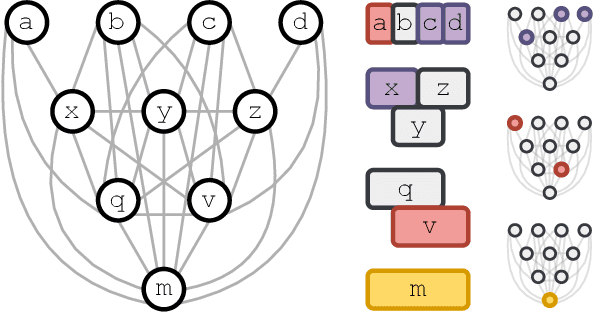
Computational feasibility is a widespread concern that guides the framing and modeling of biological and artificial intelligence. The specification of cognitive system capacities is often shaped by unexamined intuitive assumptions about the search space and complexity of a subcomputation. However, a mistaken intuition might make such initial conceptualizations misleading for what empirical questions appear relevant later on. We undertake here computational-level modeling and complexity analyses of segmentation - a widely hypothesized subcomputation that plays a requisite role in explanations of capacities across domains - as a case study to show how crucial it is to formally assess these assumptions. We mathematically prove two sets of results regarding hardness and search space size that may run counter to intuition, and position their implications with respect to existing views on the subcapacity.
Gibbs Sampling with People
Aug 06, 2020
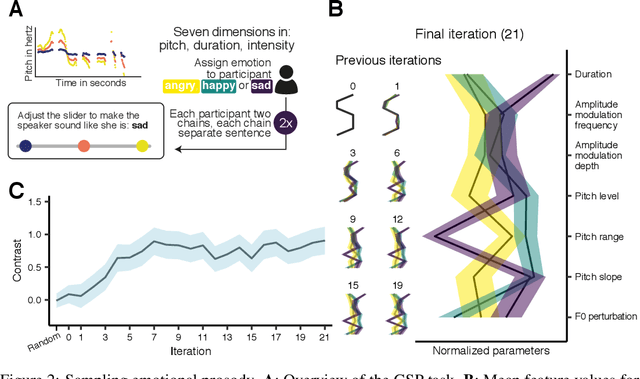
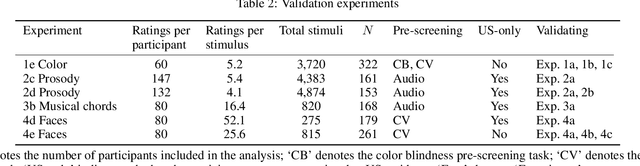
A core problem in cognitive science and machine learning is to understand how humans derive semantic representations from perceptual objects, such as color from an apple, pleasantness from a musical chord, or trustworthiness from a face. Markov Chain Monte Carlo with People (MCMCP) is a prominent method for studying such representations, in which participants are presented with binary choice trials constructed such that the decisions follow a Markov Chain Monte Carlo acceptance rule. However, MCMCP's binary choice paradigm generates relatively little information per trial, and its local proposal function makes it slow to explore the parameter space and find the modes of the distribution. Here we therefore generalize MCMCP to a continuous-sampling paradigm, where in each iteration the participant uses a slider to continuously manipulate a single stimulus dimension to optimize a given criterion such as 'pleasantness'. We formulate both methods from a utility-theory perspective, and show that the new method can be interpreted as 'Gibbs Sampling with People' (GSP). Further, we introduce an aggregation parameter to the transition step, and show that this parameter can be manipulated to flexibly shift between Gibbs sampling and deterministic optimization. In an initial study, we show GSP clearly outperforming MCMCP; we then show that GSP provides novel and interpretable results in three other domains, namely musical chords, vocal emotions, and faces. We validate these results through large-scale perceptual rating experiments. The final experiments combine GSP with a state-of-the-art image synthesis network (StyleGAN) and a recent network interpretability technique (GANSpace), enabling GSP to efficiently explore high-dimensional perceptual spaces, and demonstrating how GSP can be a powerful tool for jointly characterizing semantic representations in humans and machines.