 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindSet: Vision. A toolbox for testing DNNs on key psychological experiments
Apr 08, 2024



Multiple benchmarks have been developed to assess the alignment between deep neural networks (DNNs) and human vision. In almost all cases these benchmarks are observational in the sense they are composed of behavioural and brain responses to naturalistic images that have not been manipulated to test hypotheses regarding how DNNs or humans perceive and identify objects. Here we introduce the toolbox MindSet: Vision, consisting of a collection of image datasets and related scripts designed to test DNNs on 30 psychological findings. In all experimental conditions, the stimuli are systematically manipulated to test specific hypotheses regarding human visual perception and object recognition. In addition to providing pre-generated datasets of images, we provide code to regenerate these datasets, offering many configurable parameters which greatly extend the dataset versatility for different research contexts, and code to facilitate the testing of DNNs on these image datasets using three different methods (similarity judgments, out-of-distribution classification, and decoder method), accessible at https://github.com/MindSetVision/mindset-vision. We test ResNet-152 on each of these methods as an example of how the toolbox can be used.
Convolutional Neural Networks Trained to Identify Words Provide a Good Account of Visual Form Priming Effects
Mar 02, 2023A wide variety of orthographic coding schemes and models of visual word identification have been developed to account for masked priming data that provide a measure of orthographic similarity between letter strings. These models tend to include hand-coded orthographic representations with single unit coding for specific forms of knowledge (e.g., units coding for a letter in a given position). Here we assess how well a range of these coding schemes and models account for the pattern of form priming effects taken from the Form Priming Project and compare these findings to results observed with 11 standard deep neural network models (DNNs) developed in computer science. We find that deep convolutional networks (CNNs) perform as well or better than the coding schemes and word recognition models, whereas transformer networks did less well. The success of CNNs is remarkable as their architectures were not developed to support word recognition (they were designed to perform well on object recognition), they classify pixel images of words (rather than artificial encodings of letter strings), and their training was highly simplified (not respecting many key aspects of human experience). In addition to these form priming effects, we find that the DNNs can account for visual similarity effects on priming that are beyond all current psychological models of priming. The findings add to the recent work of (Hannagan et al., 2021) and suggest that CNNs should be given more attention in psychology as models of human visual word recognition.
Do DNNs trained on Natural Images organize visual features into Gestalts?
Apr 06, 2022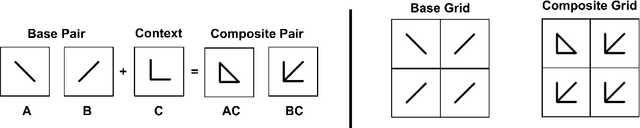
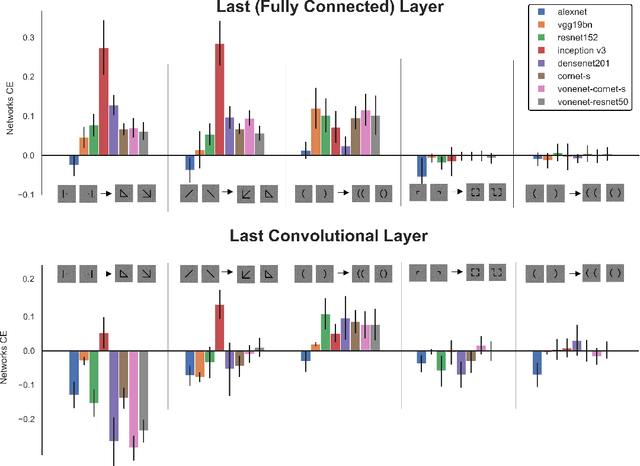
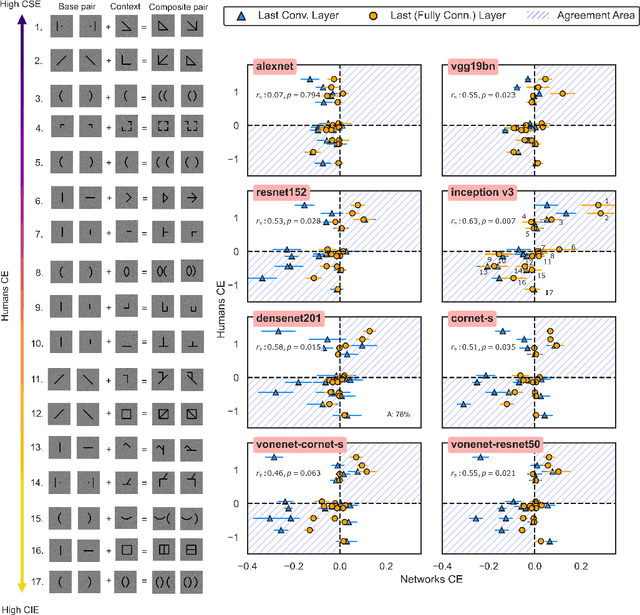
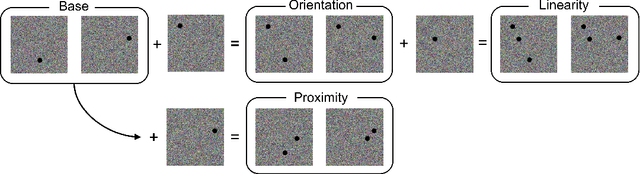
Gestalt psychologists have identified a range of conditions in which humans organize elements of a scene into a group or whole, and these perceptual grouping principles play an important role in scene perception and object identification. More recently, Deep Neural Networks (DNNs) trained on natural images have been proposed as compelling models of human vision based on reports that they perform well on various brain and behavioral benchmarks. Here we compared human and DNNs responses in discrimination judgments that assess a range of Gestalt organization principles. We found that most networks exhibited a moderate degree of Gestalt grouping for some complex stimuli at the last fully connected layer. However, in contrast with human neural data, this sensitivity vanishes at earlier visual processing layers. In a second experiment, by using simple dots configuration patterns, we found that all networks were only weakly sensitive to the grouping properties of proximity, and completely insensitive to orientation and linearity, three principles that have been shown to have a strong and robust effect on humans. Even top-performing models on the behavioral and brain benchmark Brain-Score miss these fundamental properties of human vision. Our overall conclusion is that, even when exhibiting Gestalt grouping, networks trained on 2D images use perceptual principles fundamentally different than humans.
Convolutional Neural Networks Are Not Invariant to Translation, but They Can Learn to Be
Oct 12, 2021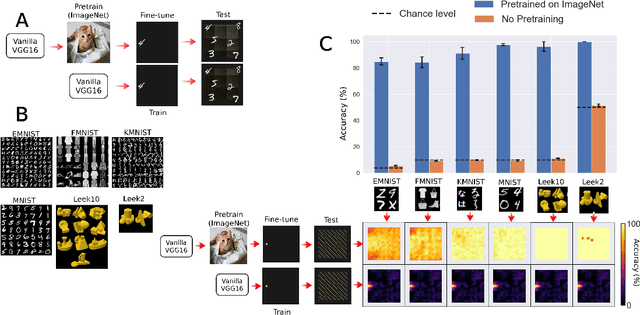
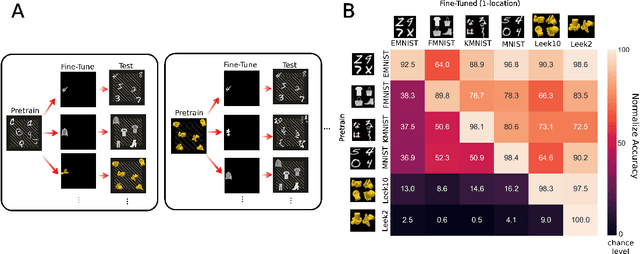

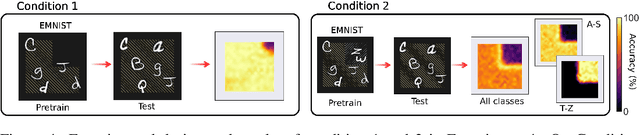
When seeing a new object, humans can immediately recognize it across different retinal locations: the internal object representation is invariant to translation. It is commonly believed that Convolutional Neural Networks (CNNs) are architecturally invariant to translation thanks to the convolution and/or pooling operations they are endowed with. In fact, several studies have found that these networks systematically fail to recognise new objects on untrained locations. In this work, we test a wide variety of CNNs architectures showing how, apart from DenseNet-121, none of the models tested was architecturally invariant to translation. Nevertheless, all of them could learn to be invariant to translation. We show how this can be achieved by pretraining on ImageNet, and it is sometimes possible with much simpler data sets when all the items are fully translated across the input canvas. At the same time, this invariance can be disrupted by further training due to catastrophic forgetting/interference. These experiments show how pretraining a network on an environment with the right `latent' characteristics (a more naturalistic environment) can result in the network learning deep perceptual rules which would dramatically improve subsequent generalization.
Learning Online Visual Invariances for Novel Objects via Supervised and Self-Supervised Training
Oct 07, 2021
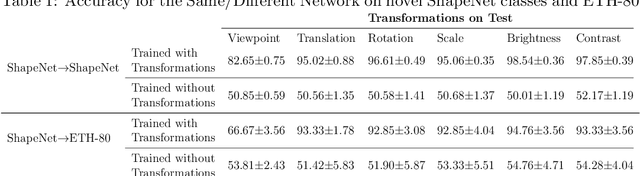
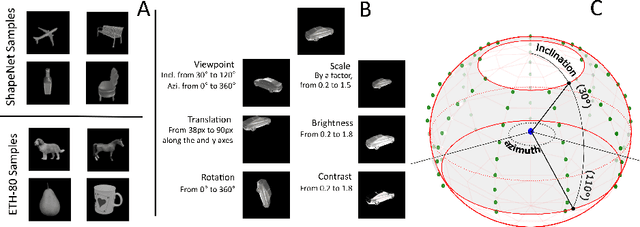
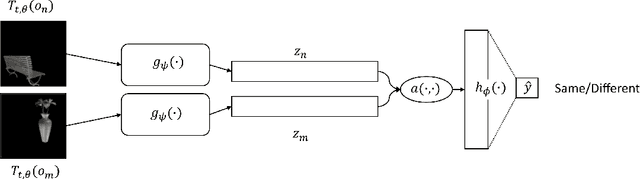
Humans can identify objects following various spatial transformations such as scale and viewpoint. This extends to novel objects, after a single presentation at a single pose, sometimes referred to as online invariance. CNNs have been proposed as a compelling model of human vision, but their ability to identify objects across transformations is typically tested on held-out samples of trained categories after extensive data augmentation. This paper assesses whether standard CNNs can support human-like online invariance by training models to recognize images of synthetic 3D objects that undergo several transformations: rotation, scaling, translation, brightness, contrast, and viewpoint. Through the analysis of models' internal representations, we show that standard supervised CNNs trained on transformed objects can acquire strong invariances on novel classes even when trained with as few as 50 objects taken from 10 classes. This extended to a different dataset of photographs of real objects. We also show that these invariances can be acquired in a self-supervised way, through solving the same/different task. We suggest that this latter approach may be similar to how humans acquire invariances.