 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Online Visual Invariances for Novel Objects via Supervised and Self-Supervised Training
Paper and Code
Oct 07, 2021
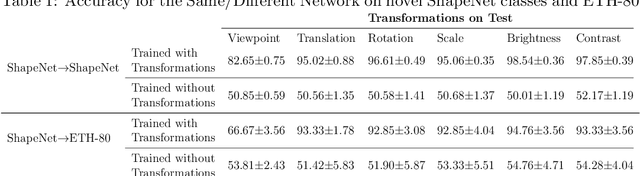
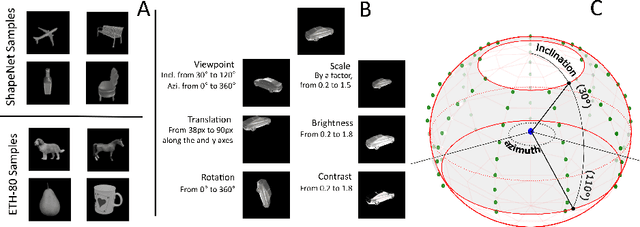
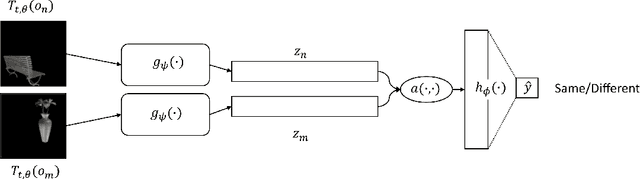
Humans can identify objects following various spatial transformations such as scale and viewpoint. This extends to novel objects, after a single presentation at a single pose, sometimes referred to as online invariance. CNNs have been proposed as a compelling model of human vision, but their ability to identify objects across transformations is typically tested on held-out samples of trained categories after extensive data augmentation. This paper assesses whether standard CNNs can support human-like online invariance by training models to recognize images of synthetic 3D objects that undergo several transformations: rotation, scaling, translation, brightness, contrast, and viewpoint. Through the analysis of models' internal representations, we show that standard supervised CNNs trained on transformed objects can acquire strong invariances on novel classes even when trained with as few as 50 objects taken from 10 classes. This extended to a different dataset of photographs of real objects. We also show that these invariances can be acquired in a self-supervised way, through solving the same/different task. We suggest that this latter approach may be similar to how humans acquire invariances.