 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Neural Networks Are Not Invariant to Translation, but They Can Learn to Be
Paper and Code
Oct 12, 2021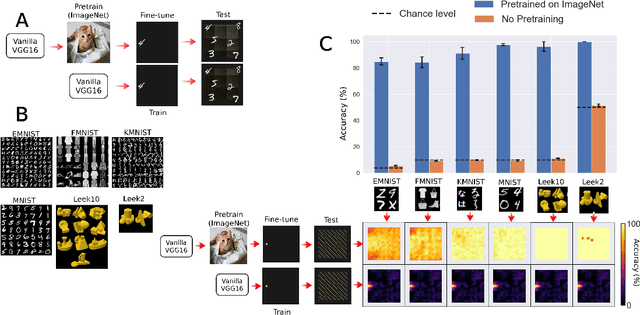
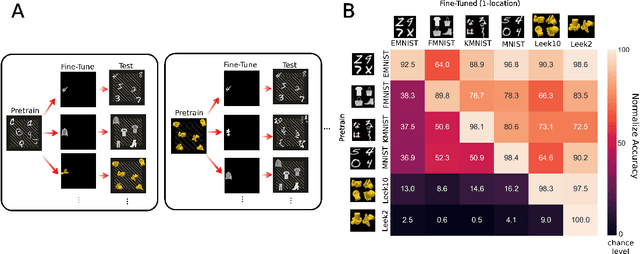

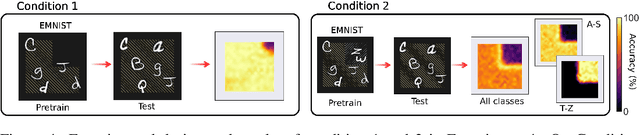
When seeing a new object, humans can immediately recognize it across different retinal locations: the internal object representation is invariant to translation. It is commonly believed that Convolutional Neural Networks (CNNs) are architecturally invariant to translation thanks to the convolution and/or pooling operations they are endowed with. In fact, several studies have found that these networks systematically fail to recognise new objects on untrained locations. In this work, we test a wide variety of CNNs architectures showing how, apart from DenseNet-121, none of the models tested was architecturally invariant to translation. Nevertheless, all of them could learn to be invariant to translation. We show how this can be achieved by pretraining on ImageNet, and it is sometimes possible with much simpler data sets when all the items are fully translated across the input canvas. At the same time, this invariance can be disrupted by further training due to catastrophic forgetting/interference. These experiments show how pretraining a network on an environment with the right `latent' characteristics (a more naturalistic environment) can result in the network learning deep perceptual rules which would dramatically improve subsequent generalization.