 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo DNNs trained on Natural Images organize visual features into Gestalts?
Paper and Code
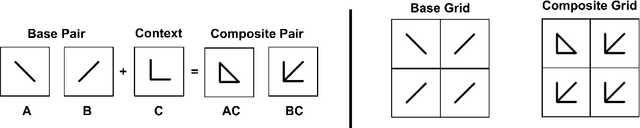
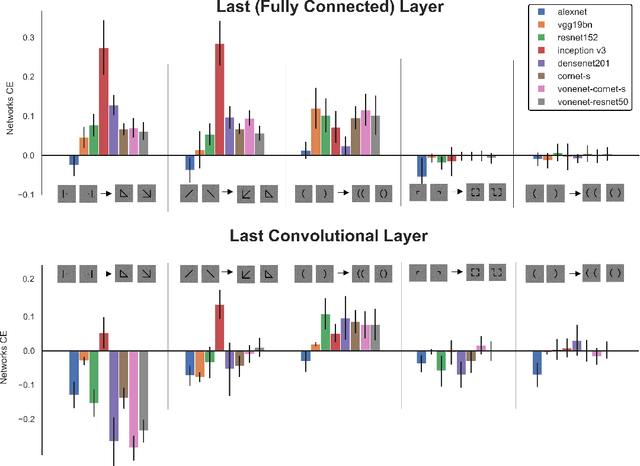
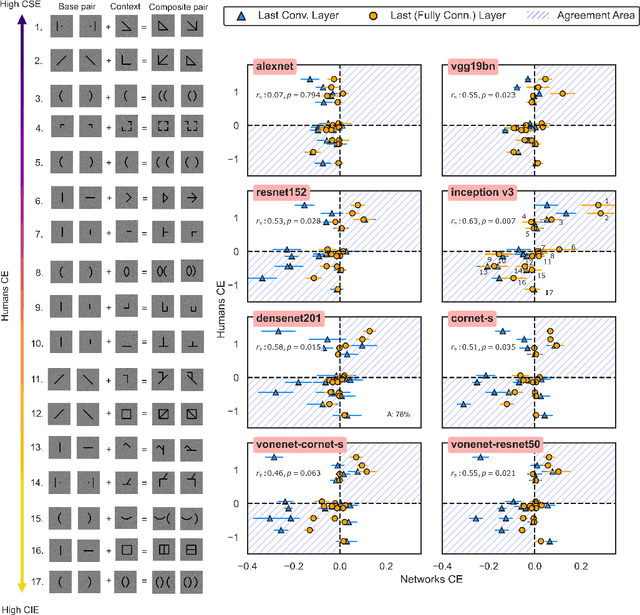
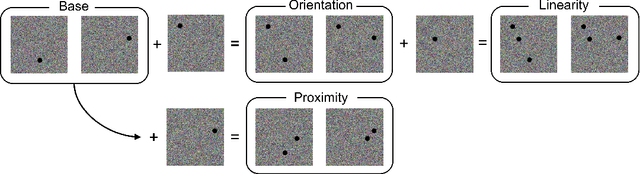
Gestalt psychologists have identified a range of conditions in which humans organize elements of a scene into a group or whole, and these perceptual grouping principles play an important role in scene perception and object identification. More recently, Deep Neural Networks (DNNs) trained on natural images have been proposed as compelling models of human vision based on reports that they perform well on various brain and behavioral benchmarks. Here we compared human and DNNs responses in discrimination judgments that assess a range of Gestalt organization principles. We found that most networks exhibited a moderate degree of Gestalt grouping for some complex stimuli at the last fully connected layer. However, in contrast with human neural data, this sensitivity vanishes at earlier visual processing layers. In a second experiment, by using simple dots configuration patterns, we found that all networks were only weakly sensitive to the grouping properties of proximity, and completely insensitive to orientation and linearity, three principles that have been shown to have a strong and robust effect on humans. Even top-performing models on the behavioral and brain benchmark Brain-Score miss these fundamental properties of human vision. Our overall conclusion is that, even when exhibiting Gestalt grouping, networks trained on 2D images use perceptual principles fundamentally different than humans.