 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectrotemporal Modulation: Efficient and Interpretable Feature Representation for Classifying Speech, Music, and Environmental Sounds
May 29, 2025Audio DNNs have demonstrated impressive performance on various machine listening tasks; however, most of their representations are computationally costly and uninterpretable, leaving room for optimization. Here, we propose a novel approach centered on spectrotemporal modulation (STM) features, a signal processing method that mimics the neurophysiological representation in the human auditory cortex. The classification performance of our STM-based model, without any pretraining, is comparable to that of pretrained audio DNNs across diverse naturalistic speech, music, and environmental sounds, which are essential categories for both human cognition and machine perception. These results show that STM is an efficient and interpretable feature representation for audio classification, advancing the development of machine listening and unlocking exciting new possibilities for basic understanding of speech and auditory sciences, as well as developing audio BCI and cognitive computing.
Multimodal Machine Learning Can Predict Videoconference Fluidity and Enjoyment
Jan 07, 2025Videoconferencing is now a frequent mode of communication in both professional and informal settings, yet it often lacks the fluidity and enjoyment of in-person conversation. This study leverages multimodal machine learning to predict moments of negative experience in videoconferencing. We sampled thousands of short clips from the RoomReader corpus, extracting audio embeddings, facial actions, and body motion features to train models for identifying low conversational fluidity, low enjoyment, and classifying conversational events (backchanneling, interruption, or gap). Our best models achieved an ROC-AUC of up to 0.87 on hold-out videoconference sessions, with domain-general audio features proving most critical. This work demonstrates that multimodal audio-video signals can effectively predict high-level subjective conversational outcomes. In addition, this is a contribution to research on videoconferencing user experience by showing that multimodal machine learning can be used to identify rare moments of negative user experience for further study or mitigation.
Position Paper: An Inner Interpretability Framework for AI Inspired by Lessons from Cognitive Neuroscience
Jun 03, 2024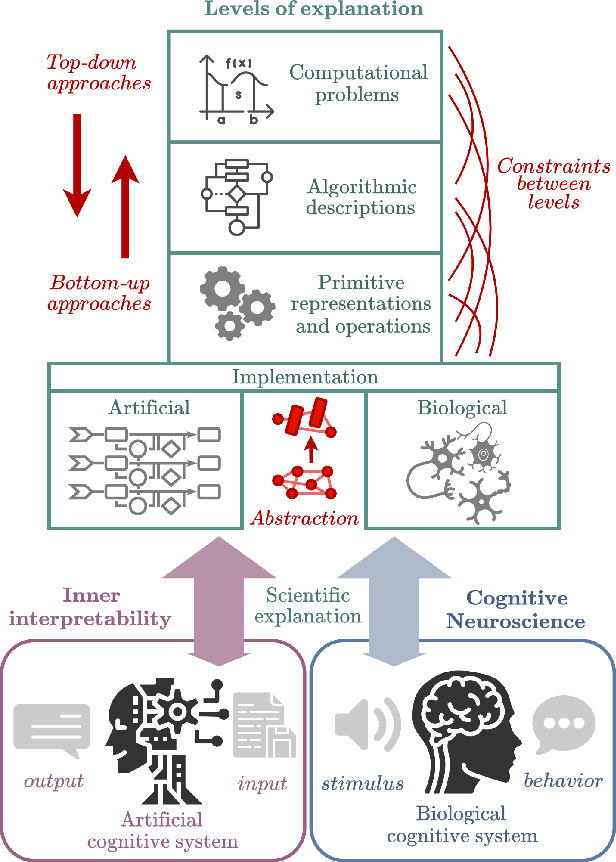
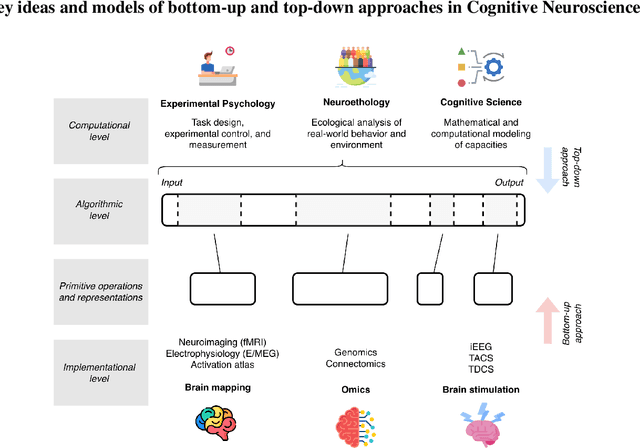
Inner Interpretability is a promising emerging field tasked with uncovering the inner mechanisms of AI systems, though how to develop these mechanistic theories is still much debated. Moreover, recent critiques raise issues that question its usefulness to advance the broader goals of AI. However, it has been overlooked that these issues resemble those that have been grappled with in another field: Cognitive Neuroscience. Here we draw the relevant connections and highlight lessons that can be transferred productively between fields. Based on these, we propose a general conceptual framework and give concrete methodological strategies for building mechanistic explanations in AI inner interpretability research. With this conceptual framework, Inner Interpretability can fend off critiques and position itself on a productive path to explain AI systems.
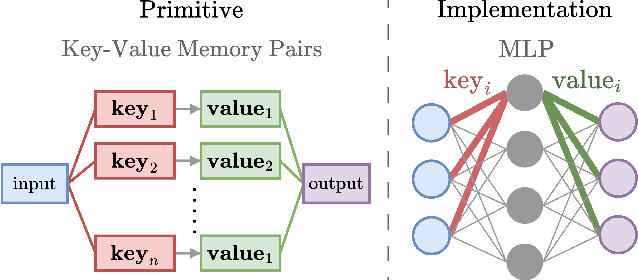
Memory in humans and deep language models: Linking hypotheses for model augmentation
Oct 07, 2022


The computational complexity of the self-attention mechanism in Transformer models significantly limits their ability to generalize over long temporal durations. Memory-augmentation, or the explicit storing of past information in external memory for subsequent predictions, has become a constructive avenue for mitigating this limitation. We argue that memory-augmented Transformers can benefit substantially from considering insights from the memory literature in humans. We detail an approach to integrating evidence from the human memory system through the specification of cross-domain linking hypotheses. We then provide an empirical demonstration to evaluate the use of surprisal as a linking hypothesis, and further identify the limitations of this approach to inform future research.
Successes and critical failures of neural networks in capturing human-like speech recognition
Apr 06, 2022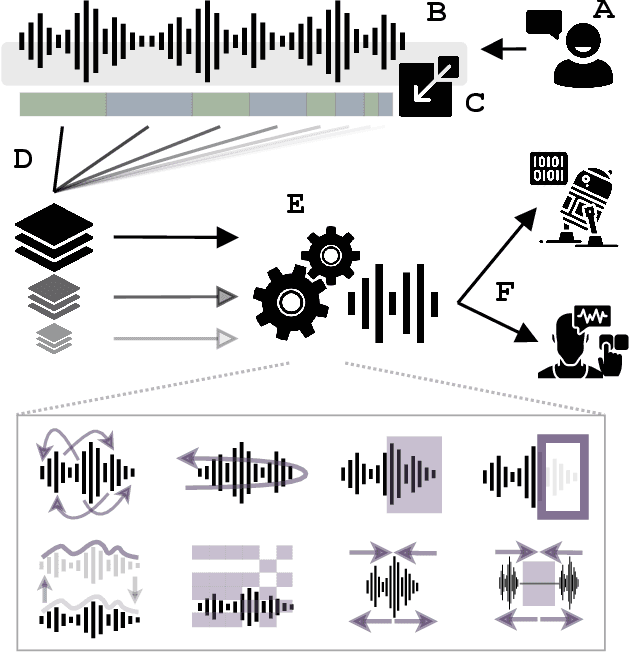
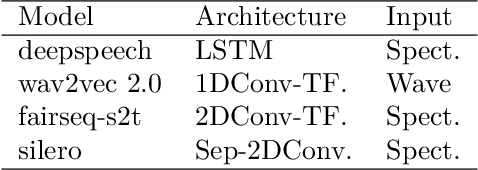
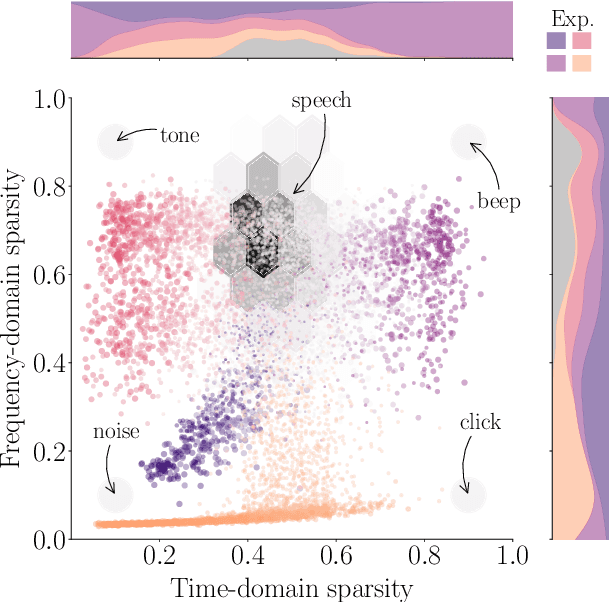
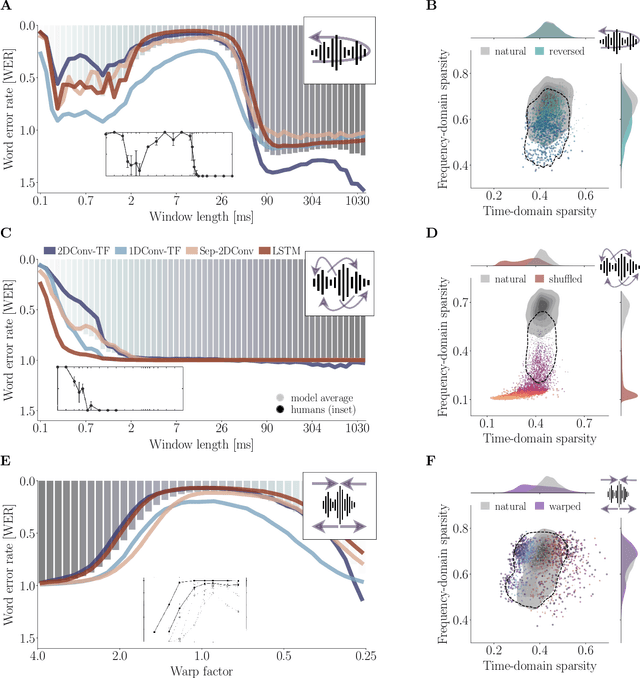
Natural and artificial audition can in principle evolve different solutions to a given problem. The constraints of the task, however, can nudge the cognitive science and engineering of audition to qualitatively converge, suggesting that a closer mutual examination would improve artificial hearing systems and process models of the mind and brain. Speech recognition - an area ripe for such exploration - is inherently robust in humans to a number transformations at various spectrotemporal granularities. To what extent are these robustness profiles accounted for by high-performing neural network systems? We bring together experiments in speech recognition under a single synthesis framework to evaluate state-of-the-art neural networks as stimulus-computable, optimized observers. In a series of experiments, we (1) clarify how influential speech manipulations in the literature relate to each other and to natural speech, (2) show the granularities at which machines exhibit out-of-distribution robustness, reproducing classical perceptual phenomena in humans, (3) identify the specific conditions where model predictions of human performance differ, and (4) demonstrate a crucial failure of all artificial systems to perceptually recover where humans do, suggesting a key specification for theory and model building. These findings encourage a tighter synergy between the cognitive science and engineering of audition.
Phonological (un)certainty weights lexical activation
Nov 17, 2017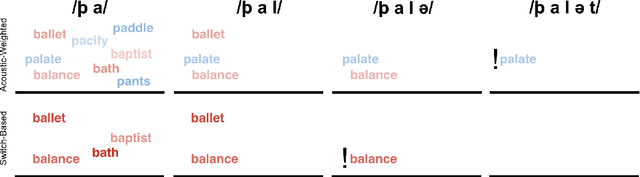
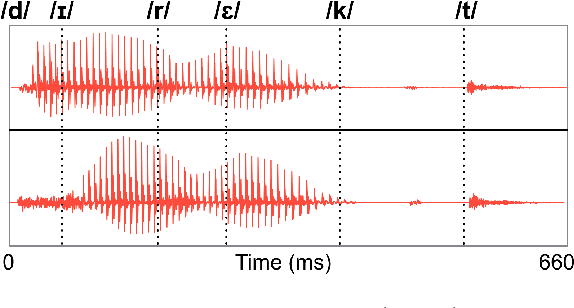
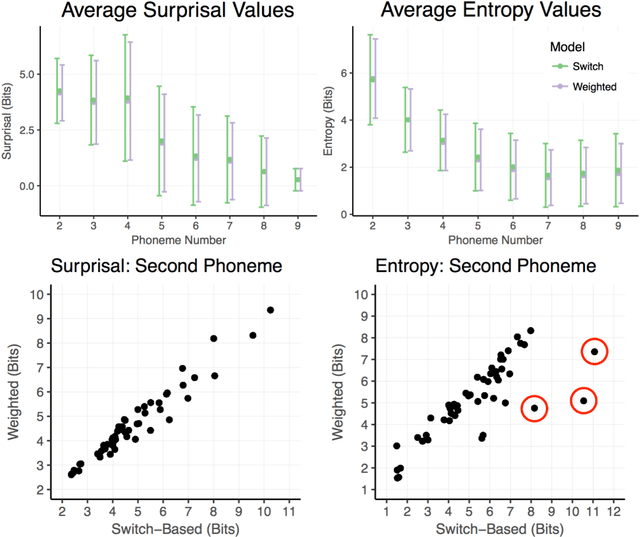
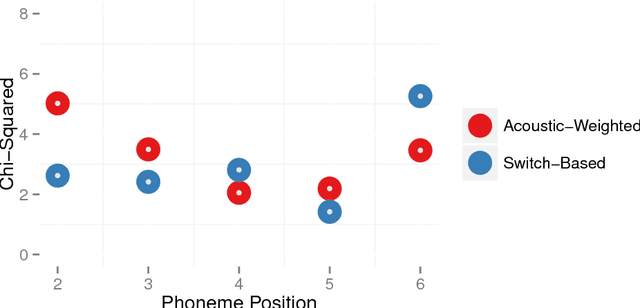
Spoken word recognition involves at least two basic computations. First is matching acoustic input to phonological categories (e.g. /b/, /p/, /d/). Second is activating words consistent with those phonological categories. Here we test the hypothesis that the listener's probability distribution over lexical items is weighted by the outcome of both computations: uncertainty about phonological discretisation and the frequency of the selected word(s). To test this, we record neural responses in auditory cortex using magnetoencephalography, and model this activity as a function of the size and relative activation of lexical candidates. Our findings indicate that towards the beginning of a word, the processing system indeed weights lexical candidates by both phonological certainty and lexical frequency; however, later into the word, activation is weighted by frequency alone.