 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Avoiding Linear Algebraic Kernel K-Means on GPUs
Jan 23, 2026Clustering is an important tool in data analysis, with K-means being popular for its simplicity and versatility. However, it cannot handle non-linearly separable clusters. Kernel K-means addresses this limitation but requires a large kernel matrix, making it computationally and memory intensive. Prior work has accelerated Kernel K-means by formulating it using sparse linear algebra primitives and implementing it on a single GPU. However, that approach cannot run on datasets with more than approximately 80,000 samples due to limited GPU memory. In this work, we address this issue by presenting a suite of distributed-memory parallel algorithms for large-scale Kernel K-means clustering on multi-GPU systems. Our approach maps the most computationally expensive components of Kernel K-means onto communication-efficient distributed linear algebra primitives uniquely tailored for Kernel K-means, enabling highly scalable implementations that efficiently cluster million-scale datasets. Central to our work is the design of partitioning schemes that enable communication-efficient composition of the linear algebra primitives that appear in Kernel K-means. Our 1.5D algorithm consistently achieves the highest performance, enabling Kernel K-means to scale to data one to two orders of magnitude larger than previously practical. On 256 GPUs, it achieves a geometric mean weak scaling efficiency of $79.7\%$ and a geometric mean strong scaling speedup of $4.2\times$. Compared to our 1D algorithm, the 1.5D approach achieves up to a $3.6\times$ speedup on 256 GPUs and reduces clustering time from over an hour to under two seconds relative to a single-GPU sliding window implementation. Our results show that distributed algorithms designed with application-specific linear algebraic formulations can achieve substantial performance improvement.
Spectrotemporal Modulation: Efficient and Interpretable Feature Representation for Classifying Speech, Music, and Environmental Sounds
May 29, 2025Audio DNNs have demonstrated impressive performance on various machine listening tasks; however, most of their representations are computationally costly and uninterpretable, leaving room for optimization. Here, we propose a novel approach centered on spectrotemporal modulation (STM) features, a signal processing method that mimics the neurophysiological representation in the human auditory cortex. The classification performance of our STM-based model, without any pretraining, is comparable to that of pretrained audio DNNs across diverse naturalistic speech, music, and environmental sounds, which are essential categories for both human cognition and machine perception. These results show that STM is an efficient and interpretable feature representation for audio classification, advancing the development of machine listening and unlocking exciting new possibilities for basic understanding of speech and auditory sciences, as well as developing audio BCI and cognitive computing.
Multimodal Machine Learning Can Predict Videoconference Fluidity and Enjoyment
Jan 07, 2025Videoconferencing is now a frequent mode of communication in both professional and informal settings, yet it often lacks the fluidity and enjoyment of in-person conversation. This study leverages multimodal machine learning to predict moments of negative experience in videoconferencing. We sampled thousands of short clips from the RoomReader corpus, extracting audio embeddings, facial actions, and body motion features to train models for identifying low conversational fluidity, low enjoyment, and classifying conversational events (backchanneling, interruption, or gap). Our best models achieved an ROC-AUC of up to 0.87 on hold-out videoconference sessions, with domain-general audio features proving most critical. This work demonstrates that multimodal audio-video signals can effectively predict high-level subjective conversational outcomes. In addition, this is a contribution to research on videoconferencing user experience by showing that multimodal machine learning can be used to identify rare moments of negative user experience for further study or mitigation.
HLSTransform: Energy-Efficient Llama 2 Inference on FPGAs Via High Level Synthesis
Apr 29, 2024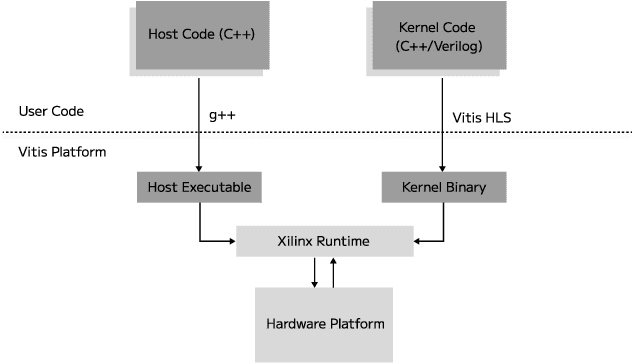

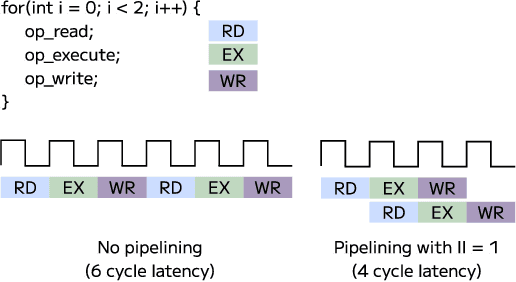

Graphics Processing Units (GPUs) have become the leading hardware accelerator for deep learning applications and are used widely in training and inference of transformers; transformers have achieved state-of-the-art performance in many areas of machine learning and are especially used in most modern Large Language Models (LLMs). However, GPUs require large amounts of energy, which poses environmental concerns, demands high operational costs, and causes GPUs to be unsuitable for edge computing. We develop an accelerator for transformers, namely, Llama 2, an open-source state-of-the-art LLM, using high level synthesis (HLS) on Field Programmable Gate Arrays (FPGAs). HLS allows us to rapidly prototype FPGA designs without writing code at the register-transfer level (RTL). We name our method HLSTransform, and the FPGA designs we synthesize with HLS achieve up to a 12.75x reduction and 8.25x reduction in energy used per token on the Xilinx Virtex UltraScale+ VU9P FPGA compared to an Intel Xeon Broadwell E5-2686 v4 CPU and NVIDIA RTX 3090 GPU respectively, while increasing inference speeds by up to 2.46x compared to CPU and maintaining 0.53x the speed of an RTX 3090 GPU despite the GPU's 4 times higher base clock rate. With the lack of existing open-source FPGA accelerators for transformers, we open-source our code and document our steps for synthesis. We hope this work will serve as a step in democratizing the use of FPGAs in transformer inference and inspire research into energy-efficient inference methods as a whole. The code can be found on https://github.com/HLSTransform/submission.