 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MUSE Benchmark: Probing Music Perception and Auditory Relational Reasoning in Audio LLMS
Oct 21, 2025Multimodal Large Language Models (MLLMs) have demonstrated capabilities in audio understanding, but current evaluations may obscure fundamental weaknesses in relational reasoning. We introduce the Music Understanding and Structural Evaluation (MUSE) Benchmark, an open-source resource with 10 tasks designed to probe fundamental music perception skills. We evaluate four SOTA models (Gemini Pro and Flash, Qwen2.5-Omni, and Audio-Flamingo 3) against a large human baseline (N=200). Our results reveal a wide variance in SOTA capabilities and a persistent gap with human experts. While Gemini Pro succeeds on basic perception, Qwen and Audio Flamingo 3 perform at or near chance, exposing severe perceptual deficits. Furthermore, we find Chain-of-Thought (CoT) prompting provides inconsistent, often detrimental results. Our work provides a critical tool for evaluating invariant musical representations and driving development of more robust AI systems.
Spectrotemporal Modulation: Efficient and Interpretable Feature Representation for Classifying Speech, Music, and Environmental Sounds
May 29, 2025Audio DNNs have demonstrated impressive performance on various machine listening tasks; however, most of their representations are computationally costly and uninterpretable, leaving room for optimization. Here, we propose a novel approach centered on spectrotemporal modulation (STM) features, a signal processing method that mimics the neurophysiological representation in the human auditory cortex. The classification performance of our STM-based model, without any pretraining, is comparable to that of pretrained audio DNNs across diverse naturalistic speech, music, and environmental sounds, which are essential categories for both human cognition and machine perception. These results show that STM is an efficient and interpretable feature representation for audio classification, advancing the development of machine listening and unlocking exciting new possibilities for basic understanding of speech and auditory sciences, as well as developing audio BCI and cognitive computing.
Guitar-TECHS: An Electric Guitar Dataset Covering Techniques, Musical Excerpts, Chords and Scales Using a Diverse Array of Hardware
Jan 07, 2025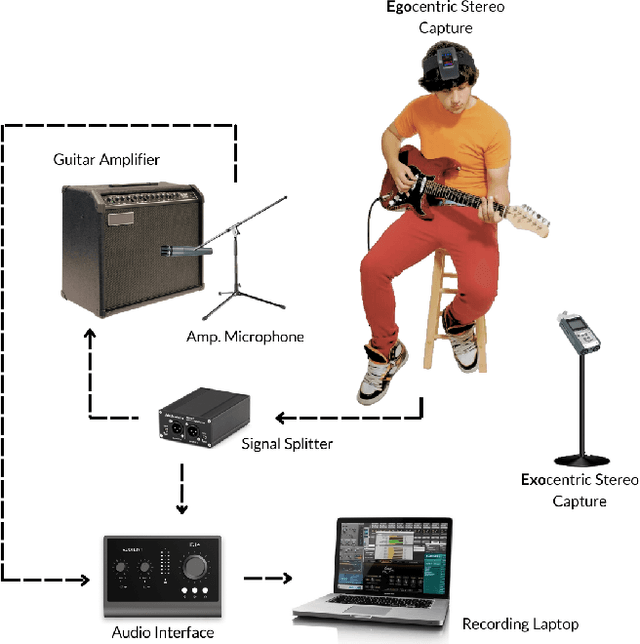
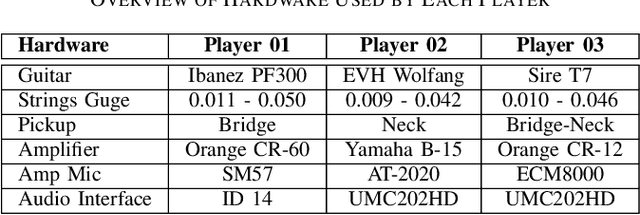


Guitar-related machine listening research involves tasks like timbre transfer, performance generation, and automatic transcription. However, small datasets often limit model robustness due to insufficient acoustic diversity and musical content. To address these issues, we introduce Guitar-TECHS, a comprehensive dataset featuring a variety of guitar techniques, musical excerpts, chords, and scales. These elements are performed by diverse musicians across various recording settings. Guitar-TECHS incorporates recordings from two stereo microphones: an egocentric microphone positioned on the performer's head and an exocentric microphone placed in front of the performer. It also includes direct input recordings and microphoned amplifier outputs, offering a wide spectrum of audio inputs and recording qualities. All signals and MIDI labels are properly synchronized. Its multi-perspective and multi-modal content makes Guitar-TECHS a valuable resource for advancing data-driven guitar research, and to develop robust guitar listening algorithms. We provide empirical data to demonstrate the dataset's effectiveness in training robust models for Guitar Tablature Transcription.
Spatial Scaper: A Library to Simulate and Augment Soundscapes for Sound Event Localization and Detection in Realistic Rooms
Jan 19, 2024Sound event localization and detection (SELD) is an important task in machine listening. Major advancements rely on simulated data with sound events in specific rooms and strong spatio-temporal labels. SELD data is simulated by convolving spatialy-localized room impulse responses (RIRs) with sound waveforms to place sound events in a soundscape. However, RIRs require manual collection in specific rooms. We present SpatialScaper, a library for SELD data simulation and augmentation. Compared to existing tools, SpatialScaper emulates virtual rooms via parameters such as size and wall absorption. This allows for parameterized placement (including movement) of foreground and background sound sources. SpatialScaper also includes data augmentation pipelines that can be applied to existing SELD data. As a case study, we use SpatialScaper to add rooms to the DCASE SELD data. Training a model with our data led to progressive performance improves as a direct function of acoustic diversity. These results show that SpatialScaper is valuable to train robust SELD models.
Robust DOA estimation using deep acoustic imaging
Jan 16, 2024Direction of arrival estimation (DoAE) aims at tracking a sound in azimuth and elevation. Recent advancements include data-driven models with inputs derived from ambisonics intensity vectors or correlations between channels in a microphone array. A spherical intensity map (SIM), or acoustic image, is an alternative input representation that remains underexplored. SIMs benefit from high-resolution microphone arrays, yet most DoAE datasets use low-resolution ones. Therefore, we first propose a super-resolution method to upsample low-resolution microphones. Next, we benchmark DoAE models that use SIMs as input. We arrive to a model that uses SIMs for DoAE estimation and outperforms a baseline and a state-of-the-art model. Our study highlights the relevance of acoustic imaging for DoAE tasks.
F0 analysis of Ghanaian pop singing reveals progressive alignment with equal temperament over the past three decades: a case study
Oct 02, 2023



Contemporary Ghanaian popular singing combines European and traditional Ghanaian influences. We hypothesize that access to technology embedded with equal temperament catalyzed a progressive alignment of Ghanaian singing with equal-tempered scales over time. To test this, we study the Ghanaian singer Daddy Lumba, whose work spans from the earliest Ghanaian electronic style in the late 1980s to the present. Studying a singular musician as a case study allows us to refine our analysis without over-interpreting the findings. We curated a collection of his songs, distributed between 1989 and 2016, to extract F0 values from isolated vocals. We used Gaussian mixture modeling (GMM) to approximate each song's scale and found that the pitch variance has been decreasing over time. We also determined whether the GMM components follow the arithmetic relationships observed in equal-tempered scales, and observed that Daddy Lumba's singing better aligns with equal temperament in recent years. Together, results reveal the impact of exposure to equal-tempered scales, resulting in lessened microtonal content in Daddy Lumba's singing. Our study highlights a potential vulnerability of Ghanaian musical scales and implies a need for research that maps and archives singing styles.
Sound Source Distance Estimation in Diverse and Dynamic Acoustic Conditions
Sep 17, 2023



Localizing a moving sound source in the real world involves determining its direction-of-arrival (DOA) and distance relative to a microphone. Advancements in DOA estimation have been facilitated by data-driven methods optimized with large open-source datasets with microphone array recordings in diverse environments. In contrast, estimating a sound source's distance remains understudied. Existing approaches assume recordings by non-coincident microphones to use methods that are susceptible to differences in room reverberation. We present a CRNN able to estimate the distance of moving sound sources across multiple datasets featuring diverse rooms, outperforming a recently-published approach. We also characterize our model's performance as a function of sound source distance and different training losses. This analysis reveals optimal training using a loss that weighs model errors as an inverse function of the sound source true distance. Our study is the first to demonstrate that sound source distance estimation can be performed across diverse acoustic conditions using deep learning.