 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Switching Beamformer for Highly Non-Stationary Environments
Jun 07, 2026Adaptive beamforming is a cornerstone of array signal processing, yet its performance often collapses in the face of complex, rapidly changing interference. When interferers appear or move unpredictably, conventional estimators encounter a fundamental memory trade-off: short windows enable rapid tracking but suffer from high estimation variance, while long windows provide stable rejection but fail to adapt to shifts. This challenge is resolved by introducing the Universal Switching Beamformer (USB), which integrates competitive sequential prediction into the beamforming architecture. By employing a linear transition diagram, the USB implicitly maintains an exponentially large family of candidate covariance histories and dynamically re-weights them based on their cumulative output power. This mechanism allows the beamformer to automatically vary its effective memory length without explicit change detection or heuristic parameter tuning. A theoretical upper bound is proven on the regret relative to an omniscient oracle that selects the best piecewise-stationary covariance model in hindsight. Extensive simulations and experiments on the SwellEx-96 dataset demonstrate that the USB achieves the agility of short-window estimators and the precision of long-term integration, providing a principled solution for tracking highly non-stationary scenes.
Time Segmented Beamforming via Dynamic Programming: Theory and Implementation
May 24, 2026In dynamic acoustic environments with time-varying interferers, effective beamforming requires identifying stationary regions over time. The Capon beamformer, a whitened matched filter constrained to maintain unity gain in the desired direction, theoretically relies on the instantaneous ensemble covariance matrix. Practical implementations rely on the batch Capon (or Sample Matrix Inversion), which estimates the sample covariance matrix (SCM) by averaging over a block of snapshots. This practical approach implicitly assumes that the data within the batch window is stationary and can be coherently combined. In non-stationary settings, a batch approach that averages over fixed or excessively long windows fails, as moving interferers smear the SCM and degrade the beamformer's nulling capabilities. To address this, this paper introduces a temporally segmented distortionless response beamformer. Inspired by the segmented least squares method, which fits piecewise polynomials to data while penalizing excessive segmentation to prevent overfitting, the framework extends practical Capon beamforming by incorporating data-driven temporal segmentation. This formulation minimizes output power while dynamically adapting the SCM estimation windows to local stationarity, offering a principled approach to tracking time-varying interferers.
Guitar-TECHS: An Electric Guitar Dataset Covering Techniques, Musical Excerpts, Chords and Scales Using a Diverse Array of Hardware
Jan 07, 2025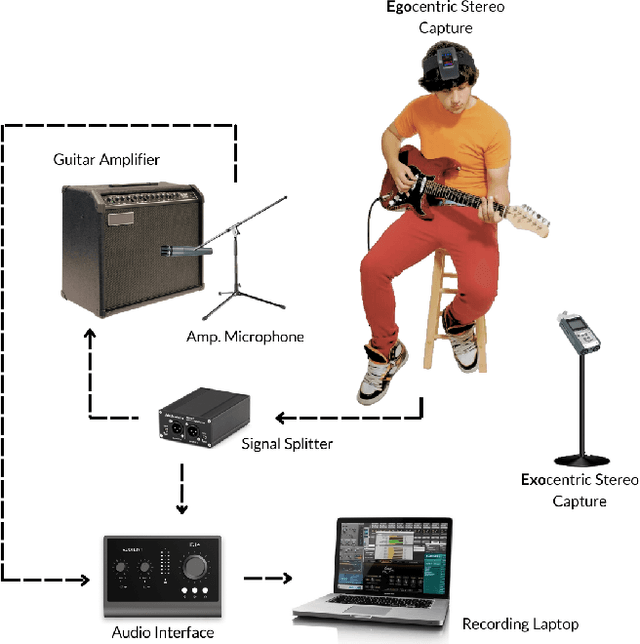
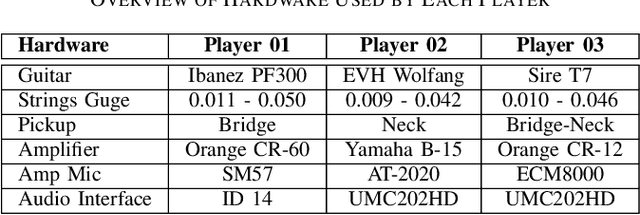


Guitar-related machine listening research involves tasks like timbre transfer, performance generation, and automatic transcription. However, small datasets often limit model robustness due to insufficient acoustic diversity and musical content. To address these issues, we introduce Guitar-TECHS, a comprehensive dataset featuring a variety of guitar techniques, musical excerpts, chords, and scales. These elements are performed by diverse musicians across various recording settings. Guitar-TECHS incorporates recordings from two stereo microphones: an egocentric microphone positioned on the performer's head and an exocentric microphone placed in front of the performer. It also includes direct input recordings and microphoned amplifier outputs, offering a wide spectrum of audio inputs and recording qualities. All signals and MIDI labels are properly synchronized. Its multi-perspective and multi-modal content makes Guitar-TECHS a valuable resource for advancing data-driven guitar research, and to develop robust guitar listening algorithms. We provide empirical data to demonstrate the dataset's effectiveness in training robust models for Guitar Tablature Transcription.
Mechatronic Generation of Datasets for Acoustics Research
Oct 01, 2023We address the challenge of making spatial audio datasets by proposing a shared mechanized recording space that can run custom acoustic experiments: a Mechatronic Acoustic Research System (MARS). To accommodate a wide variety of experiments, we implement an extensible architecture for wireless multi-robot coordination which enables synchronized robot motion for dynamic scenes with moving speakers and microphones. Using a virtual control interface, we can remotely design automated experiments to collect large-scale audio data. This data is shown to be similar across repeated runs, demonstrating the reliability of MARS. We discuss the potential for MARS to make audio data collection accessible for researchers without dedicated acoustic research spaces.