 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity Analysis of Generative Spatial Audio Metrics: A Study on Responsiveness, Smoothness, and Symmetry
Jun 10, 2026Evaluating generative spatial audio for First-Order Ambisonics (FOA) remains challenging due to a limited understanding of how metrics respond to changes in spatial parameters such as azimuth and elevation. We propose a framework to analyze metric sensitivity along continuous spatial trajectories, drawing on principles of sensitivity analysis in parametric sound synthesis. Using controlled FOA scenes with increasing scene complexity, we define three desiderata for metric behavior: Responsiveness, Smoothness, and Symmetry. We assess standard distribution-based and sample-based metrics, including Fréchet Audio Distance (FAD), intensity vectors, and acoustic maps. Our findings show that FAD using localization-specific embeddings and acoustic maps yield high Responsiveness and robust Smoothness and Symmetry across conditions, while intensity vectors degrade with increasing scene complexity. This is the first step towards investigating the sensitivity of metrics for generative spatial audio.
Spatial Scaper: A Library to Simulate and Augment Soundscapes for Sound Event Localization and Detection in Realistic Rooms
Jan 19, 2024Sound event localization and detection (SELD) is an important task in machine listening. Major advancements rely on simulated data with sound events in specific rooms and strong spatio-temporal labels. SELD data is simulated by convolving spatialy-localized room impulse responses (RIRs) with sound waveforms to place sound events in a soundscape. However, RIRs require manual collection in specific rooms. We present SpatialScaper, a library for SELD data simulation and augmentation. Compared to existing tools, SpatialScaper emulates virtual rooms via parameters such as size and wall absorption. This allows for parameterized placement (including movement) of foreground and background sound sources. SpatialScaper also includes data augmentation pipelines that can be applied to existing SELD data. As a case study, we use SpatialScaper to add rooms to the DCASE SELD data. Training a model with our data led to progressive performance improves as a direct function of acoustic diversity. These results show that SpatialScaper is valuable to train robust SELD models.
Robust DOA estimation using deep acoustic imaging
Jan 16, 2024Direction of arrival estimation (DoAE) aims at tracking a sound in azimuth and elevation. Recent advancements include data-driven models with inputs derived from ambisonics intensity vectors or correlations between channels in a microphone array. A spherical intensity map (SIM), or acoustic image, is an alternative input representation that remains underexplored. SIMs benefit from high-resolution microphone arrays, yet most DoAE datasets use low-resolution ones. Therefore, we first propose a super-resolution method to upsample low-resolution microphones. Next, we benchmark DoAE models that use SIMs as input. We arrive to a model that uses SIMs for DoAE estimation and outperforms a baseline and a state-of-the-art model. Our study highlights the relevance of acoustic imaging for DoAE tasks.
Exploring modality-agnostic representations for music classification
Jun 02, 2021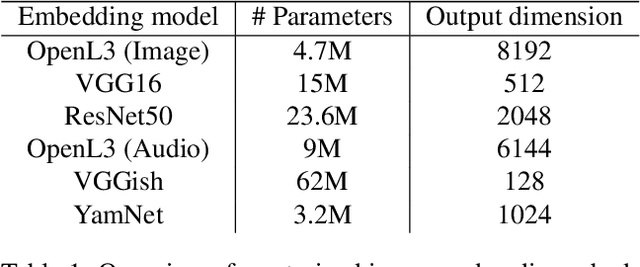
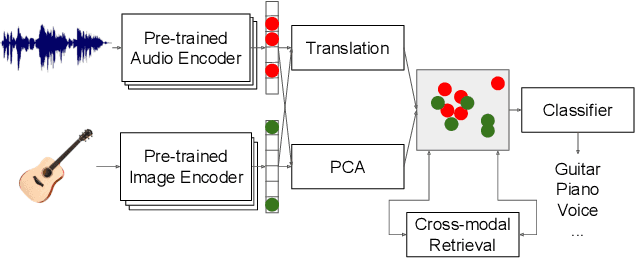
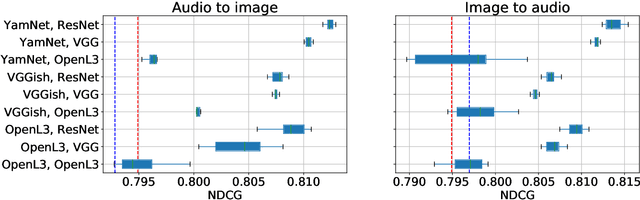
Music information is often conveyed or recorded across multiple data modalities including but not limited to audio, images, text and scores. However, music information retrieval research has almost exclusively focused on single modality recognition, requiring development of separate models for each modality. Some multi-modal works require multiple coexisting modalities given to the model as inputs, constraining the use of these models to the few cases where data from all modalities are available. To the best of our knowledge, no existing model has the ability to take inputs from varying modalities, e.g. images or sounds, and classify them into unified music categories. We explore the use of cross-modal retrieval as a pretext task to learn modality-agnostic representations, which can then be used as inputs to classifiers that are independent of modality. We select instrument classification as an example task for our study as both visual and audio components provide relevant semantic information. We train music instrument classifiers that can take both images or sounds as input, and perform comparably to sound-only or image-only classifiers. Furthermore, we explore the case when there is limited labeled data for a given modality, and the impact in performance by using labeled data from other modalities. We are able to achieve almost 70% of best performing system in a zero-shot setting. We provide a detailed analysis of experimental results to understand the potential and limitations of the approach, and discuss future steps towards modality-agnostic classifiers.
Multitask Learning for Fundamental Frequency Estimation in Music
Sep 02, 2018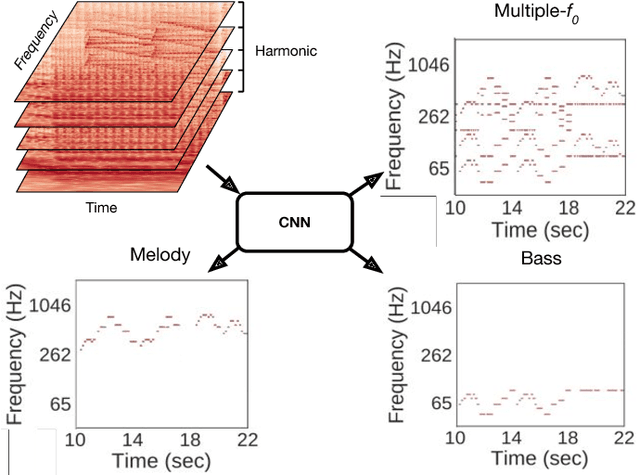
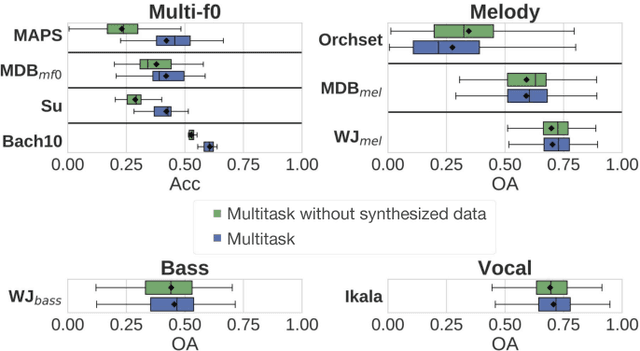
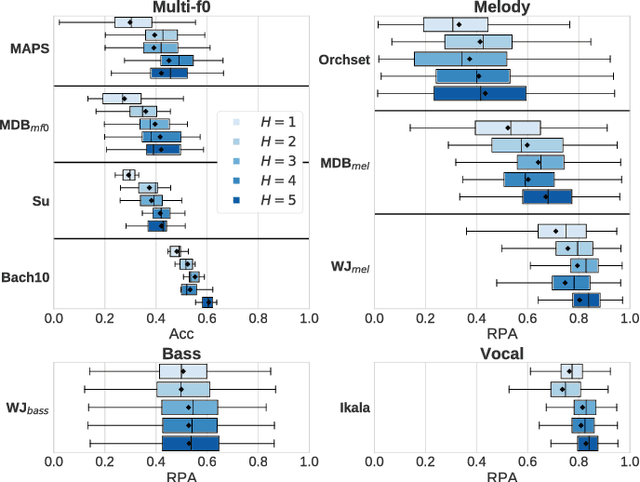
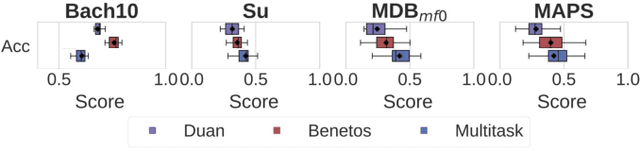
Fundamental frequency (f0) estimation from polyphonic music includes the tasks of multiple-f0, melody, vocal, and bass line estimation. Historically these problems have been approached separately, and only recently, using learning-based approaches. We present a multitask deep learning architecture that jointly estimates outputs for various tasks including multiple-f0, melody, vocal and bass line estimation, and is trained using a large, semi-automatically annotated dataset. We show that the multitask model outperforms its single-task counterparts, and explore the effect of various design decisions in our approach, and show that it performs better or at least competitively when compared against strong baseline methods.