 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Direction-Aware Neural Acoustic Fields
Jul 09, 2025This paper presents a physics-informed neural network (PINN) for modeling first-order Ambisonic (FOA) room impulse responses (RIRs). PINNs have demonstrated promising performance in sound field interpolation by combining the powerful modeling capability of neural networks and the physical principles of sound propagation. In room acoustics, PINNs have typically been trained to represent the sound pressure measured by omnidirectional microphones where the wave equation or its frequency-domain counterpart, i.e., the Helmholtz equation, is leveraged. Meanwhile, FOA RIRs additionally provide spatial characteristics and are useful for immersive audio generation with a wide range of applications. In this paper, we extend the PINN framework to model FOA RIRs. We derive two physics-informed priors for FOA RIRs based on the correspondence between the particle velocity and the (X, Y, Z)-channels of FOA. These priors associate the predicted W-channel and other channels through their partial derivatives and impose the physically feasible relationship on the four channels. Our experiments confirm the effectiveness of the proposed method compared with a neural network without the physics-informed prior.
Direction-Aware Neural Acoustic Fields for Few-Shot Interpolation of Ambisonic Impulse Responses
May 19, 2025The characteristics of a sound field are intrinsically linked to the geometric and spatial properties of the environment surrounding a sound source and a listener. The physics of sound propagation is captured in a time-domain signal known as a room impulse response (RIR). Prior work using neural fields (NFs) has allowed learning spatially-continuous representations of RIRs from finite RIR measurements. However, previous NF-based methods have focused on monaural omnidirectional or at most binaural listeners, which does not precisely capture the directional characteristics of a real sound field at a single point. We propose a direction-aware neural field (DANF) that more explicitly incorporates the directional information by Ambisonic-format RIRs. While DANF inherently captures spatial relations between sources and listeners, we further propose a direction-aware loss. In addition, we investigate the ability of DANF to adapt to new rooms in various ways including low-rank adaptation.
Data Augmentation Using Neural Acoustic Fields With Retrieval-Augmented Pre-training
Apr 19, 2025


This report details MERL's system for room impulse response (RIR) estimation submitted to the Generative Data Augmentation Workshop at ICASSP 2025 for Augmenting RIR Data (Task 1) and Improving Speaker Distance Estimation (Task 2). We first pre-train a neural acoustic field conditioned by room geometry on an external large-scale dataset in which pairs of RIRs and the geometries are provided. The neural acoustic field is then adapted to each target room by using the enrollment data, where we leverage either the provided room geometries or geometries retrieved from the external dataset, depending on availability. Lastly, we predict the RIRs for each pair of source and receiver locations specified by Task 1, and use these RIRs to train the speaker distance estimation model in Task 2.
Spatial Scaper: A Library to Simulate and Augment Soundscapes for Sound Event Localization and Detection in Realistic Rooms
Jan 19, 2024Sound event localization and detection (SELD) is an important task in machine listening. Major advancements rely on simulated data with sound events in specific rooms and strong spatio-temporal labels. SELD data is simulated by convolving spatialy-localized room impulse responses (RIRs) with sound waveforms to place sound events in a soundscape. However, RIRs require manual collection in specific rooms. We present SpatialScaper, a library for SELD data simulation and augmentation. Compared to existing tools, SpatialScaper emulates virtual rooms via parameters such as size and wall absorption. This allows for parameterized placement (including movement) of foreground and background sound sources. SpatialScaper also includes data augmentation pipelines that can be applied to existing SELD data. As a case study, we use SpatialScaper to add rooms to the DCASE SELD data. Training a model with our data led to progressive performance improves as a direct function of acoustic diversity. These results show that SpatialScaper is valuable to train robust SELD models.
Leveraging Geometrical Acoustic Simulations of Spatial Room Impulse Responses for Improved Sound Event Detection and Localization
Sep 06, 2023As deeper and more complex models are developed for the task of sound event localization and detection (SELD), the demand for annotated spatial audio data continues to increase. Annotating field recordings with 360$^{\circ}$ video takes many hours from trained annotators, while recording events within motion-tracked laboratories are bounded by cost and expertise. Because of this, localization models rely on a relatively limited amount of spatial audio data in the form of spatial room impulse response (SRIR) datasets, which limits the progress of increasingly deep neural network based approaches. In this work, we demonstrate that simulated geometrical acoustics can provide an appealing solution to this problem. We use simulated geometrical acoustics to generate a novel SRIR dataset that can train a SELD model to provide similar performance to that of a real SRIR dataset. Furthermore, we demonstrate using simulated data to augment existing datasets, improving on benchmarks set by state of the art SELD models. We explore the potential and limitations of geometric acoustic simulation for localization and event detection. We also propose further studies to verify the limitations of this method, as well as further methods to generate synthetic data for SELD tasks without the need to record more data.
Blind Acoustic Room Parameter Estimation Using Phase Features
Mar 13, 2023Modeling room acoustics in a field setting involves some degree of blind parameter estimation from noisy and reverberant audio. Modern approaches leverage convolutional neural networks (CNNs) in tandem with time-frequency representation. Using short-time Fourier transforms to develop these spectrogram-like features has shown promising results, but this method implicitly discards a significant amount of audio information in the phase domain. Inspired by recent works in speech enhancement, we propose utilizing novel phase-related features to extend recent approaches to blindly estimate the so-called "reverberation fingerprint" parameters, namely, volume and RT60. The addition of these features is shown to outperform existing methods that rely solely on magnitude-based spectral features across a wide range of acoustics spaces. We evaluate the effectiveness of the deployment of these novel features in both single-parameter and multi-parameter estimation strategies, using a novel dataset that consists of publicly available room impulse responses (RIRs), synthesized RIRs, and in-house measurements of real acoustic spaces.
Sound Event Detection in Urban Audio With Single and Multi-Rate PCEN
Feb 06, 2021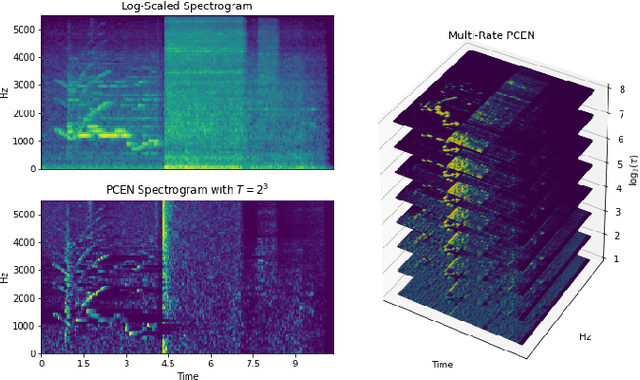
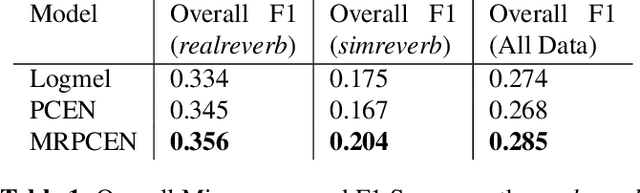
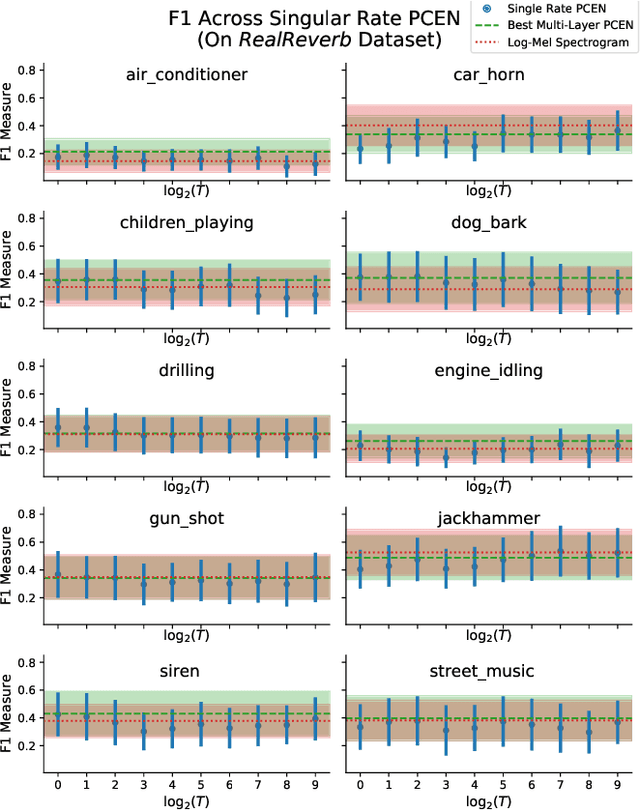
Recent literature has demonstrated that the use of per-channel energy normalization (PCEN), has significant performance improvements over traditional log-scaled mel-frequency spectrograms in acoustic sound event detection (SED) in a multi-class setting with overlapping events. However, the configuration of PCEN's parameters is sensitive to the recording environment, the characteristics of the class of events of interest, and the presence of multiple overlapping events. This leads to improvements on a class-by-class basis, but poor cross-class performance. In this article, we experiment using PCEN spectrograms as an alternative method for SED in urban audio using the UrbanSED dataset, demonstrating per-class improvements based on parameter configuration. Furthermore, we address cross-class performance with PCEN using a novel method, Multi-Rate PCEN (MRPCEN). We demonstrate cross-class SED performance with MRPCEN, demonstrating improvements to cross-class performance compared to traditional single-rate PCEN.