 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSS-BRPE: Self-Supervised Blind Room Parameter Estimation Using Attention Mechanisms
Sep 08, 2024



In recent years, dynamic parameterization of acoustic environments has garnered attention in audio processing. This focus includes room volume and reverberation time (RT60), which define local acoustics independent of sound source and receiver orientation. Previous studies show that purely attention-based models can achieve advanced results in room parameter estimation. However, their success relies on supervised pretrainings that require a large amount of labeled true values for room parameters and complex training pipelines. In light of this, we propose a novel Self-Supervised Blind Room Parameter Estimation (SS-BRPE) system. This system combines a purely attention-based model with self-supervised learning to estimate room acoustic parameters, from single-channel noisy speech signals. By utilizing unlabeled audio data for pretraining, the proposed system significantly reduces dependencies on costly labeled datasets. Our model also incorporates dynamic feature augmentation during fine-tuning to enhance adaptability and generalizability. Experimental results demonstrate that the SS-BRPE system not only achieves more superior performance in estimating room parameters than state-of-the-art (SOTA) methods but also effectively maintains high accuracy under conditions with limited labeled data. Code available at https://github.com/bjut-chunxiwang/SS-BRPE.
Exploring the Power of Pure Attention Mechanisms in Blind Room Parameter Estimation
Feb 25, 2024Dynamic parameterization of acoustic environments has drawn widespread attention in the field of audio processing. Precise representation of local room acoustic characteristics is crucial when designing audio filters for various audio rendering applications. Key parameters in this context include reverberation time (RT60) and geometric room volume. In recent years, neural networks have been extensively applied in the task of blind room parameter estimation. However, there remains a question of whether pure attention mechanisms can achieve superior performance in this task. To address this issue, this study employs blind room parameter estimation based on monaural noisy speech signals. Various model architectures are investigated, including a proposed attention-based model. This model is a convolution-free Audio Spectrogram Transformer, utilizing patch splitting, attention mechanisms, and cross-modality transfer learning from a pretrained Vision Transformer. Experimental results suggest that the proposed attention mechanism-based model, relying purely on attention mechanisms without using convolution, exhibits significantly improved performance across various room parameter estimation tasks, especially with the help of dedicated pretraining and data augmentation schemes. Additionally, the model demonstrates more advantageous adaptability and robustness when handling variable-length audio inputs compared to existing methods.
Attention Is All You Need For Blind Room Volume Estimation
Sep 23, 2023



In recent years, dynamic parameterization of acoustic environments has raised increasing attention in the field of audio processing. One of the key parameters that characterize the local room acoustics in isolation from orientation and directivity of sources and receivers is the geometric room volume. Convolutional neural networks (CNNs) have been widely selected as the main models for conducting blind room acoustic parameter estimation, which aims to learn a direct mapping from audio spectrograms to corresponding labels. With the recent trend of self-attention mechanisms, this paper introduces a purely attention-based model to blindly estimate room volumes based on single-channel noisy speech signals. We demonstrate the feasibility of eliminating the reliance on CNN for this task and the proposed Transformer architecture takes Gammatone magnitude spectral coefficients and phase spectrograms as inputs. To enhance the model performance given the task-specific dataset, cross-modality transfer learning is also applied. Experimental results demonstrate that the proposed model outperforms traditional CNN models across a wide range of real-world acoustics spaces, especially with the help of the dedicated pretraining and data augmentation schemes.
Blind Acoustic Room Parameter Estimation Using Phase Features
Mar 13, 2023Modeling room acoustics in a field setting involves some degree of blind parameter estimation from noisy and reverberant audio. Modern approaches leverage convolutional neural networks (CNNs) in tandem with time-frequency representation. Using short-time Fourier transforms to develop these spectrogram-like features has shown promising results, but this method implicitly discards a significant amount of audio information in the phase domain. Inspired by recent works in speech enhancement, we propose utilizing novel phase-related features to extend recent approaches to blindly estimate the so-called "reverberation fingerprint" parameters, namely, volume and RT60. The addition of these features is shown to outperform existing methods that rely solely on magnitude-based spectral features across a wide range of acoustics spaces. We evaluate the effectiveness of the deployment of these novel features in both single-parameter and multi-parameter estimation strategies, using a novel dataset that consists of publicly available room impulse responses (RIRs), synthesized RIRs, and in-house measurements of real acoustic spaces.
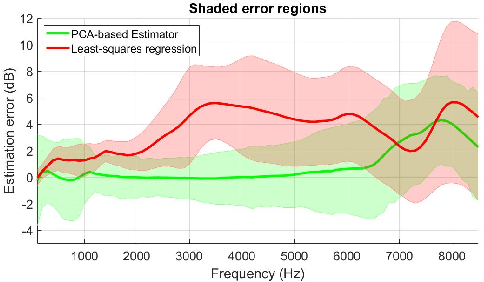
Acoustic Room Compensation Using Local PCA-based Room Average PSD Estimation
Jun 30, 2022
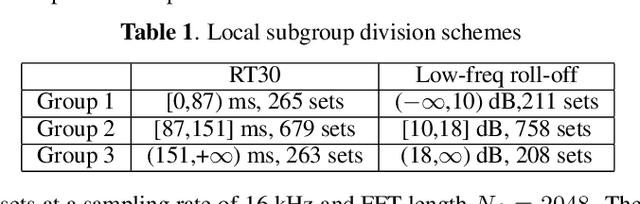
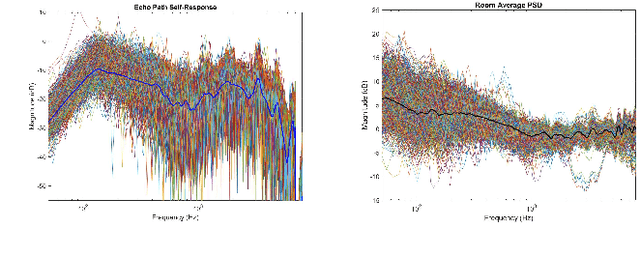

Acoustic room compensation techniques, which allow a sound reproduction system to counteract undesired alteration to the sound scene due to excessive room resonances, have been widely studied. Extensive efforts have been reported to enlarge the region over which room equalization is effective and to contrast variations of room transfer functions in space. A speaker-tuning technology "Trueplay" allows users to compensate for undesired room effects over an extended listening area based on a spatially averaged power spectral density (PSD) of the room, which is conventionally measured using microphones on portable devices when users move around the room. In this work, we propose a novel system that leverages the measurement of the speaker echo path self-response to predict the room average PSD using a local PCA based approach. Experimental results confirm the effectiveness of the proposed estimation method, which further leads to a room compensation filter design that achieves a good sound similarity compared to the reference system with the ground-truth room average PSD while outperforming other systems that do not leverage the proposed estimator.
Individualized Hear-through For Acoustic Transparency Using PCA-Based Sound Pressure Estimation At The Eardrum
Oct 12, 2021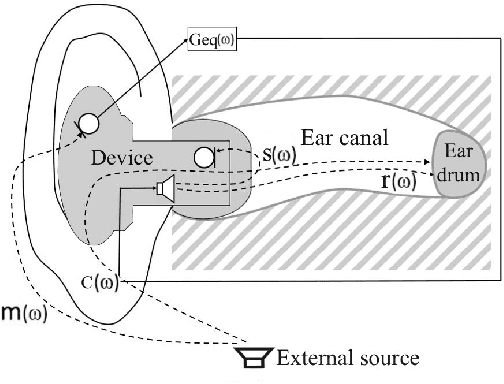
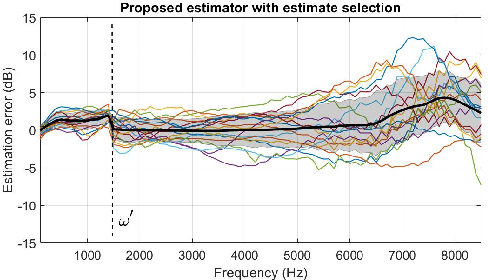
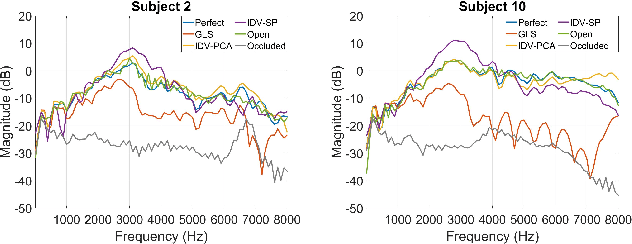
The hear-through functionality on hearing devices, which allows hearing equivalent to the open-ear while providing the possibility to modify the sound pressure at the eardrum in a desired manner, has drawn great attention from researchers in recent years. To this end, the output of the device is processed by means of an equalization filter, such that the transfer function between external sound sources and the eardrum is equivalent for the open-ear and the aided condition with the device in the ear. To achieve an ideal performance, the equalization filter design assumes the exact knowledge of all the relevant acoustic transfer functions. A particular challenge is the transfer function between the hearing device receiver and the eardrum, which is difficult to obtain in practice as it requires additional probe-tube measurements. In this work, we address this issue by proposing an individualized hear-through equalization filter design that leverages the measurement of the so-called secondary path to predict the sound pressure at the eardrum. Experimental results using real-ear measured transfer functions confirm that the proposed method achieves a good sound quality compared to the open-ear while outperforming filter designs that do not leverage the proposed estimator.
Classification of Huntington Disease using Acoustic and Lexical Features
Aug 07, 2020
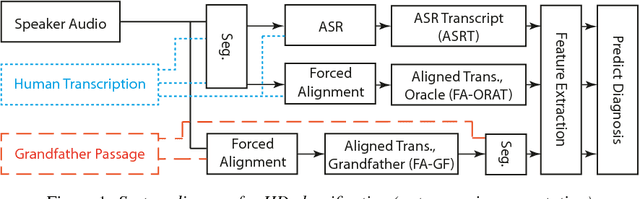

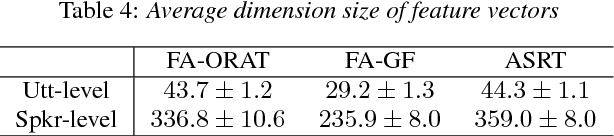
Speech is a critical biomarker for Huntington Disease (HD), with changes in speech increasing in severity as the disease progresses. Speech analyses are currently conducted using either transcriptions created manually by trained professionals or using global rating scales. Manual transcription is both expensive and time-consuming and global rating scales may lack sufficient sensitivity and fidelity. Ultimately, what is needed is an unobtrusive measure that can cheaply and continuously track disease progression. We present first steps towards the development of such a system, demonstrating the ability to automatically differentiate between healthy controls and individuals with HD using speech cues. The results provide evidence that objective analyses can be used to support clinical diagnoses, moving towards the tracking of symptomatology outside of laboratory and clinical environments.
Deep Learning for Environmentally Robust Speech Recognition: An Overview of Recent Developments
Sep 21, 2018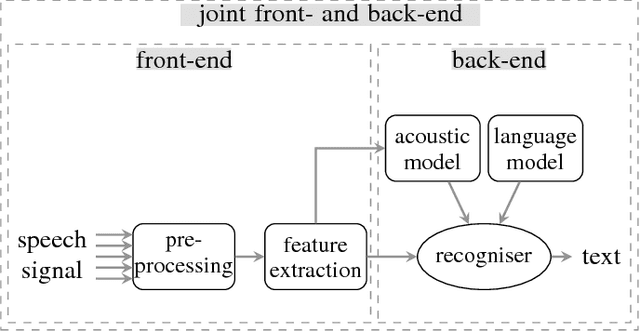

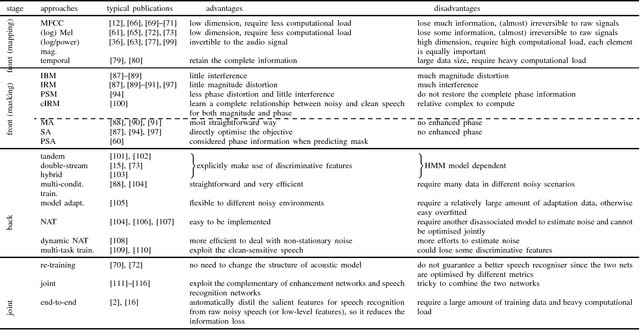

Eliminating the negative effect of non-stationary environmental noise is a long-standing research topic for automatic speech recognition that stills remains an important challenge. Data-driven supervised approaches, including ones based on deep neural networks, have recently emerged as potential alternatives to traditional unsupervised approaches and with sufficient training, can alleviate the shortcomings of the unsupervised methods in various real-life acoustic environments. In this light, we review recently developed, representative deep learning approaches for tackling non-stationary additive and convolutional degradation of speech with the aim of providing guidelines for those involved in the development of environmentally robust speech recognition systems. We separately discuss single- and multi-channel techniques developed for the front-end and back-end of speech recognition systems, as well as joint front-end and back-end training frameworks.