 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSS-BRPE: Self-Supervised Blind Room Parameter Estimation Using Attention Mechanisms
Sep 08, 2024



In recent years, dynamic parameterization of acoustic environments has garnered attention in audio processing. This focus includes room volume and reverberation time (RT60), which define local acoustics independent of sound source and receiver orientation. Previous studies show that purely attention-based models can achieve advanced results in room parameter estimation. However, their success relies on supervised pretrainings that require a large amount of labeled true values for room parameters and complex training pipelines. In light of this, we propose a novel Self-Supervised Blind Room Parameter Estimation (SS-BRPE) system. This system combines a purely attention-based model with self-supervised learning to estimate room acoustic parameters, from single-channel noisy speech signals. By utilizing unlabeled audio data for pretraining, the proposed system significantly reduces dependencies on costly labeled datasets. Our model also incorporates dynamic feature augmentation during fine-tuning to enhance adaptability and generalizability. Experimental results demonstrate that the SS-BRPE system not only achieves more superior performance in estimating room parameters than state-of-the-art (SOTA) methods but also effectively maintains high accuracy under conditions with limited labeled data. Code available at https://github.com/bjut-chunxiwang/SS-BRPE.
Target Speaker Extraction by Directly Exploiting Contextual Information in the Time-Frequency Domain
Feb 27, 2024



In target speaker extraction, many studies rely on the speaker embedding which is obtained from an enrollment of the target speaker and employed as the guidance. However, solely using speaker embedding may not fully utilize the contextual information contained in the enrollment. In this paper, we directly exploit this contextual information in the time-frequency (T-F) domain. Specifically, the T-F representations of the enrollment and the mixed signal are interacted to compute the weighting matrices through an attention mechanism. These weighting matrices reflect the similarity among different frames of the T-F representations and are further employed to obtain the consistent T-F representations of the enrollment. These consistent representations are served as the guidance, allowing for better exploitation of the contextual information. Furthermore, the proposed method achieves the state-of-the-art performance on the benchmark dataset and shows its effectiveness in the complex scenarios.
Exploring the Power of Pure Attention Mechanisms in Blind Room Parameter Estimation
Feb 25, 2024Dynamic parameterization of acoustic environments has drawn widespread attention in the field of audio processing. Precise representation of local room acoustic characteristics is crucial when designing audio filters for various audio rendering applications. Key parameters in this context include reverberation time (RT60) and geometric room volume. In recent years, neural networks have been extensively applied in the task of blind room parameter estimation. However, there remains a question of whether pure attention mechanisms can achieve superior performance in this task. To address this issue, this study employs blind room parameter estimation based on monaural noisy speech signals. Various model architectures are investigated, including a proposed attention-based model. This model is a convolution-free Audio Spectrogram Transformer, utilizing patch splitting, attention mechanisms, and cross-modality transfer learning from a pretrained Vision Transformer. Experimental results suggest that the proposed attention mechanism-based model, relying purely on attention mechanisms without using convolution, exhibits significantly improved performance across various room parameter estimation tasks, especially with the help of dedicated pretraining and data augmentation schemes. Additionally, the model demonstrates more advantageous adaptability and robustness when handling variable-length audio inputs compared to existing methods.
Attention Is All You Need For Blind Room Volume Estimation
Sep 23, 2023



In recent years, dynamic parameterization of acoustic environments has raised increasing attention in the field of audio processing. One of the key parameters that characterize the local room acoustics in isolation from orientation and directivity of sources and receivers is the geometric room volume. Convolutional neural networks (CNNs) have been widely selected as the main models for conducting blind room acoustic parameter estimation, which aims to learn a direct mapping from audio spectrograms to corresponding labels. With the recent trend of self-attention mechanisms, this paper introduces a purely attention-based model to blindly estimate room volumes based on single-channel noisy speech signals. We demonstrate the feasibility of eliminating the reliance on CNN for this task and the proposed Transformer architecture takes Gammatone magnitude spectral coefficients and phase spectrograms as inputs. To enhance the model performance given the task-specific dataset, cross-modality transfer learning is also applied. Experimental results demonstrate that the proposed model outperforms traditional CNN models across a wide range of real-world acoustics spaces, especially with the help of the dedicated pretraining and data augmentation schemes.
An Effective Dereverberation Algorithm by Fusing MVDR and MCLP
Mar 28, 2022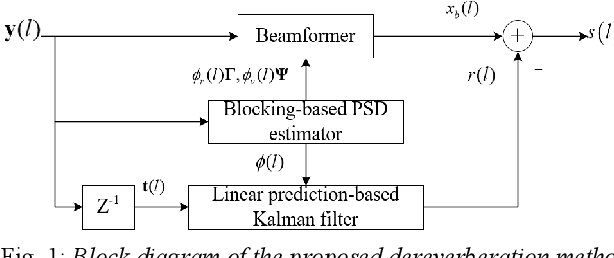
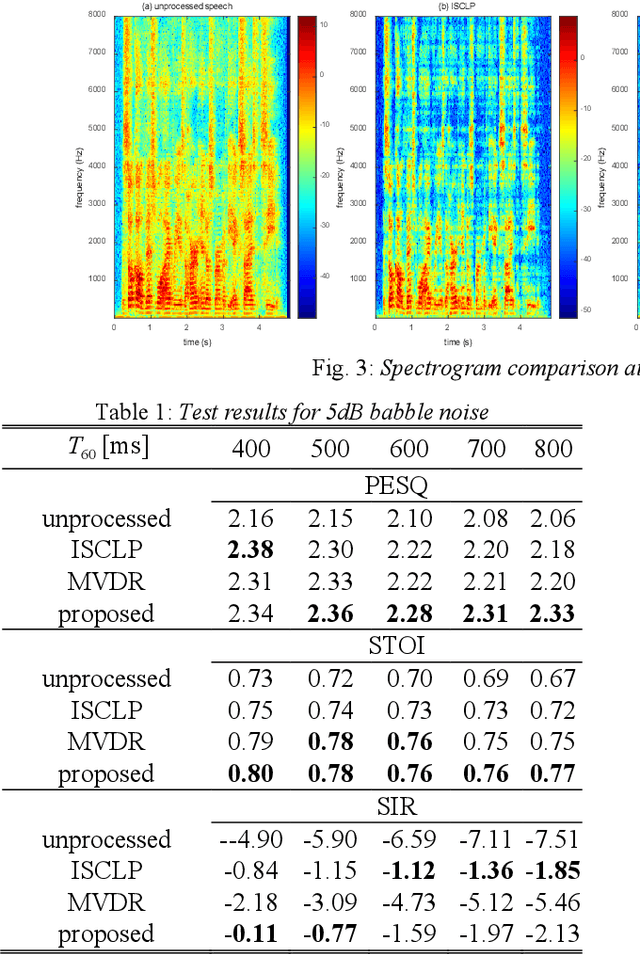
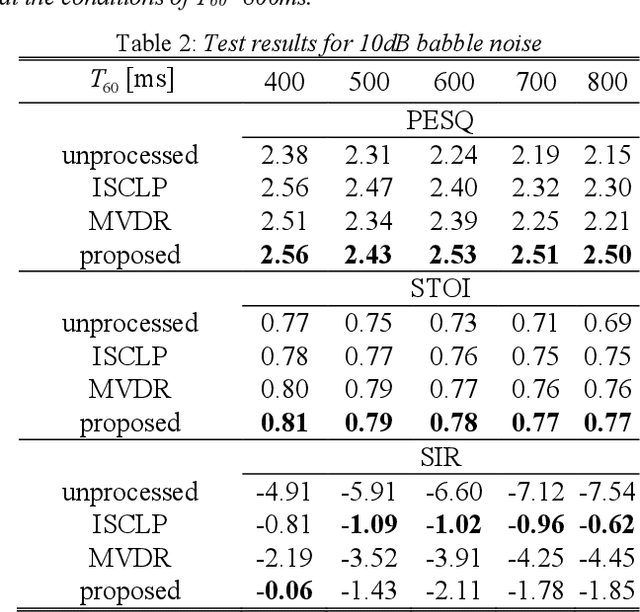
In the scenario with reverberation, the experience of human-machine interaction will become worse. In order to solve this problem, many methods for the dereverberation have emerged. At present, how to update the parameters of the Kalman filter in the existing dereverberation methods based on multichannel linear prediction (MCLP) is a challenging task, especially, accurate power spectral density (PSD) estimation of target speech. In this paper, minimum variance distortionless response (MVDR) beamformer and MCLP are effectively fused in the dereverberation, where the PSD of target speech used for Kalman filter is modified in the MCLP. In order to construct a MVDR beamformer, the PSD of late reverberation and the PSD of the noise are estimated simultaneously by the blocking-based PSD estimator. Thus, the PSD of target speech used for Kalman filter can be obtained by subtracting the PSD of late reverberation and the PSD of the noise from the PSD of observation signal. Compared to the reference methods, the proposed method shows an outstanding performance.
Multi-source wideband doa estimation method by frequency focusing and error weighting
Mar 28, 2022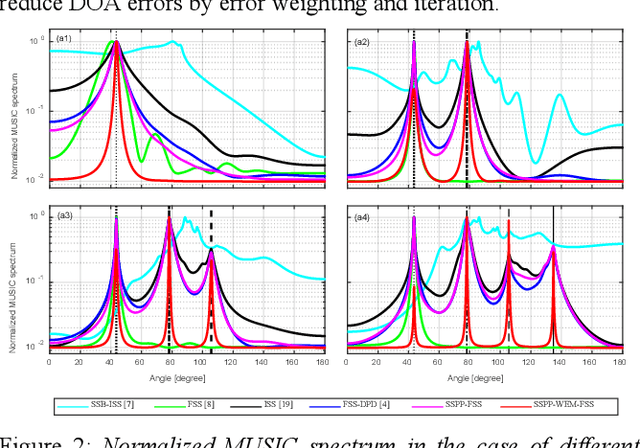
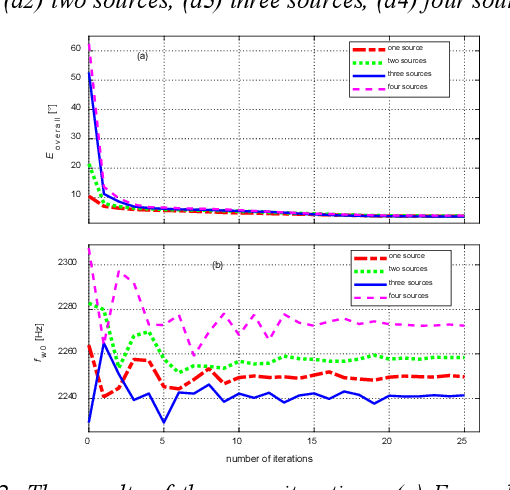
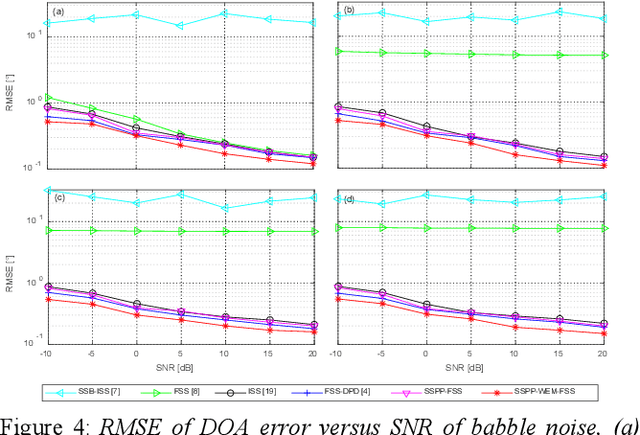
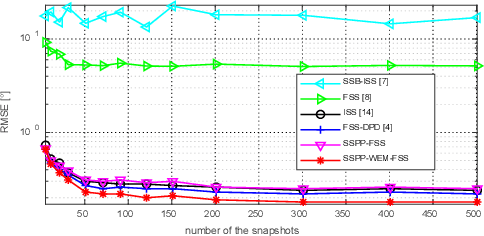
In this paper, a new multi-source wideband direction of arrival (MSW-DOA) estimation method is proposed for the signal with non-uniform distribution using the sub-array of uniform linear array. Different from conventional methods, based on the free far-field model, the proposed method mainly makes two contributions. One is that the sub-array decomposition is adopted to improve the accuracy of MSW-DOA estimation by minimizing the weighted error, and the other one is that the frequency focusing procedure is optimized according to the presence probability of sound sources for reducing the influence of the sub-bands with low signal to noise ratio (SNR). Simulation results show that the proposed method can effectively improve the performance of wideband DOA estimation in the case of multiple sound sources.
A Neural Vocoder Based Packet Loss Concealment Algorithm
Mar 26, 2022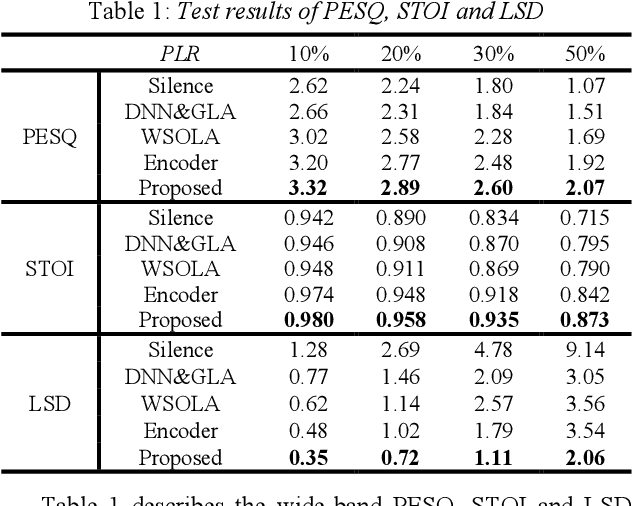
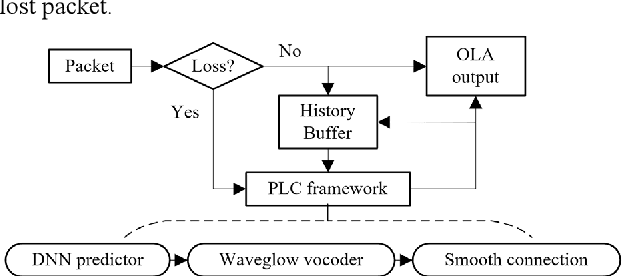
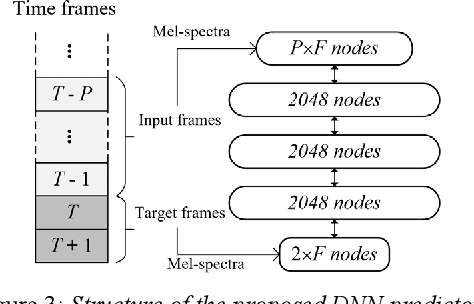
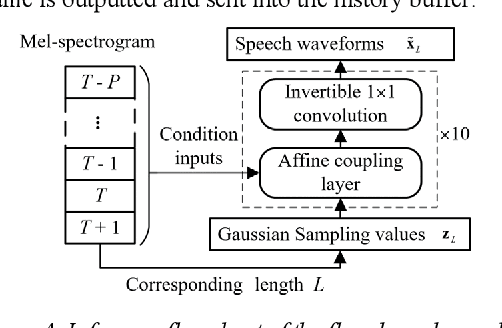
The packet loss problem seriously affects the quality of service in Voice over IP (VoIP) sceneries. In this paper, we investigated online receiver-based packet loss concealment which is much more portable and applicable. For ensuring the speech naturalness, rather than directly processing time-domain waveforms or separately reconstructing amplitudes and phases in frequency domain, a flow-based neural vocoder is adopted to generate the substitution waveform of lost packet from Mel-spectrogram which is generated from history contents by a well-designed neural predictor. Furthermore, a waveform similarity-based smoothing post-process is created to mitigate the discontinuity of speech and avoid the artifacts. The experimental results show the outstanding performance of the proposed method.
Embedding Recurrent Layers with Dual-Path Strategy in a Variant of Convolutional Network for Speaker-Independent Speech Separation
Mar 25, 2022
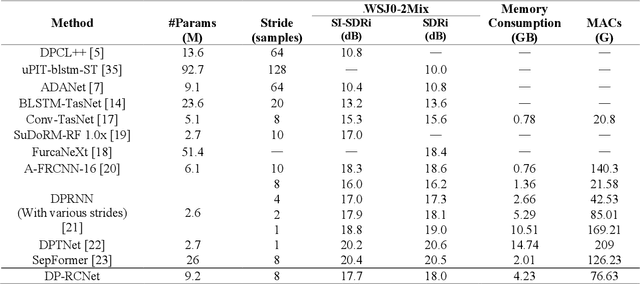
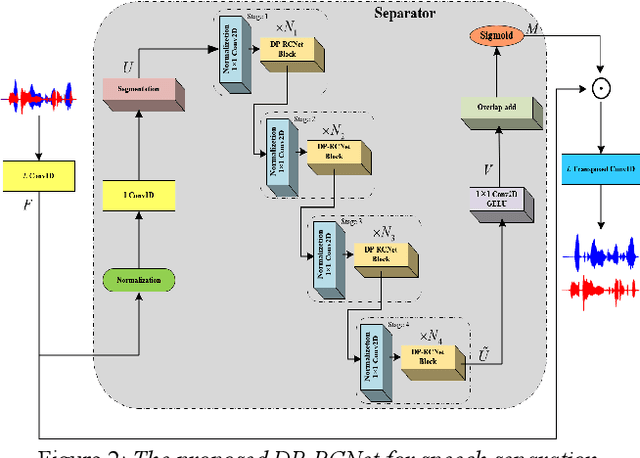
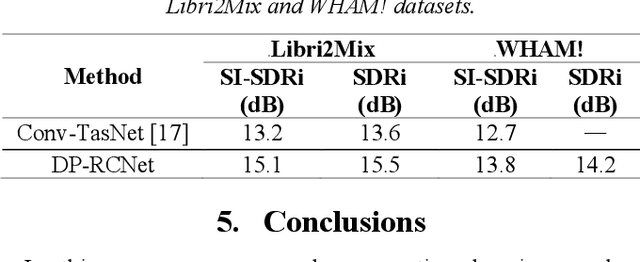
Speaker-independent speech separation has achieved remarkable performance in recent years with the development of deep neural network (DNN). Various network architectures, from traditional convolutional neural network (CNN) and recurrent neural network (RNN) to advanced transformer, have been designed sophistically to improve separation performance. However, the state-of-the-art models usually suffer from several flaws related to the computation, such as large model size, huge memory consumption and computational complexity. To find the balance between the performance and computational efficiency and to further explore the modeling ability of traditional network structure, we combine RNN and a newly proposed variant of convolutional network to cope with speech separation problem. By embedding two RNNs into basic block of this variant with the help of dual-path strategy, the proposed network can effectively learn the local information and global dependency. Besides, a four-staged structure enables the separation procedure to be performed gradually at finer and finer scales as the feature dimension increases. The experimental results on various datasets have proven the effectiveness of the proposed method and shown that a trade-off between the separation performance and computational efficiency is well achieved.