 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget Speaker Extraction by Directly Exploiting Contextual Information in the Time-Frequency Domain
Feb 27, 2024



In target speaker extraction, many studies rely on the speaker embedding which is obtained from an enrollment of the target speaker and employed as the guidance. However, solely using speaker embedding may not fully utilize the contextual information contained in the enrollment. In this paper, we directly exploit this contextual information in the time-frequency (T-F) domain. Specifically, the T-F representations of the enrollment and the mixed signal are interacted to compute the weighting matrices through an attention mechanism. These weighting matrices reflect the similarity among different frames of the T-F representations and are further employed to obtain the consistent T-F representations of the enrollment. These consistent representations are served as the guidance, allowing for better exploitation of the contextual information. Furthermore, the proposed method achieves the state-of-the-art performance on the benchmark dataset and shows its effectiveness in the complex scenarios.
THUEE system description for NIST 2019 SRE CTS Challenge
Dec 25, 2019
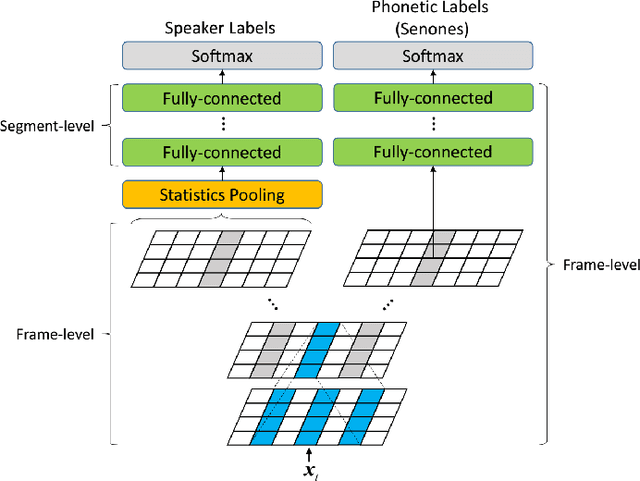
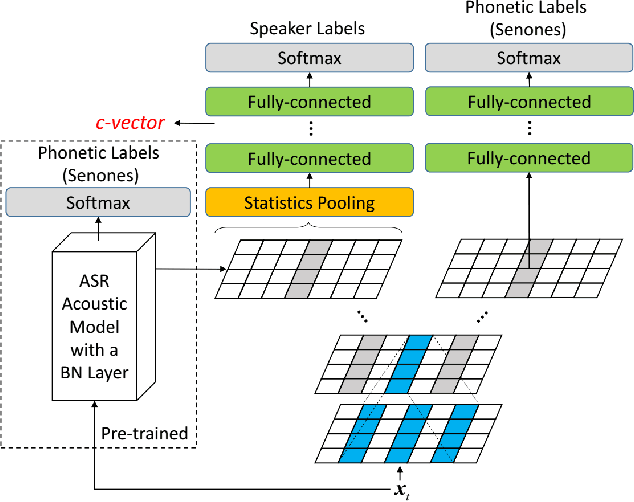

This paper describes the systems submitted by the department of electronic engineering, institute of microelectronics of Tsinghua university and TsingMicro Co. Ltd. (THUEE) to the NIST 2019 speaker recognition evaluation CTS challenge. Six subsystems, including etdnn/ams, ftdnn/as, eftdnn/ams, resnet, multitask and c-vector are developed in this evaluation.
Multiobjective Optimization Training of PLDA for Speaker Verification
Aug 25, 2018
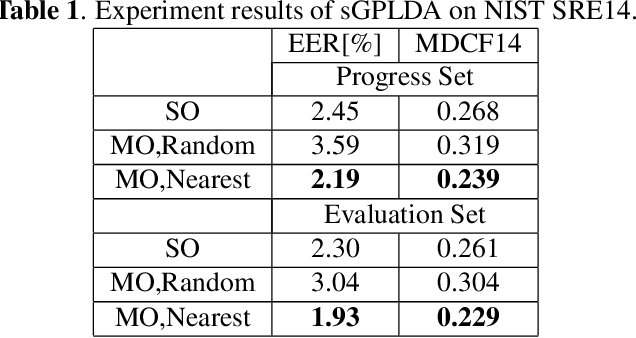
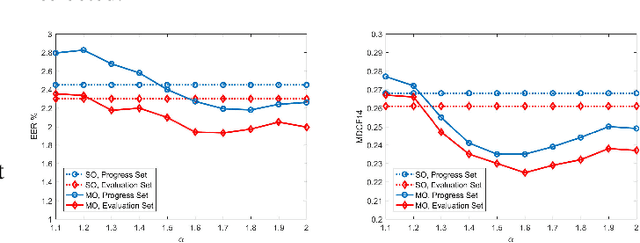
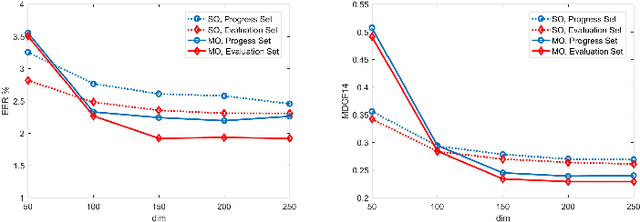
Most current state-of-the-art text-independent speaker verification systems take probabilistic linear discriminant analysis (PLDA) as their backend classifiers. The model parameters of PLDA is often estimated by maximizing the log-likelihood function. This training procedure focuses on increasing the log-likelihood, while ignoring the distinction between speakers. In order to better distinguish speakers, we propose a multiobjective optimization training for PLDA. Experiment results show that the proposed method has more than 10% relative performance improvement for both EER and the MinDCF on the NIST SRE 2014 i-vector challenge dataset.