 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMEB: Long-horizon Memory Embedding Benchmark
Mar 19, 2026Memory embeddings are crucial for memory-augmented systems, such as OpenClaw, but their evaluation is underexplored in current text embedding benchmarks, which narrowly focus on traditional passage retrieval and fail to assess models' ability to handle long-horizon memory retrieval tasks involving fragmented, context-dependent, and temporally distant information. To address this, we introduce the Long-horizon Memory Embedding Benchmark (LMEB), a comprehensive framework that evaluates embedding models' capabilities in handling complex, long-horizon memory retrieval tasks. LMEB spans 22 datasets and 193 zero-shot retrieval tasks across 4 memory types: episodic, dialogue, semantic, and procedural, with both AI-generated and human-annotated data. These memory types differ in terms of level of abstraction and temporal dependency, capturing distinct aspects of memory retrieval that reflect the diverse challenges of the real world. We evaluate 15 widely used embedding models, ranging from hundreds of millions to ten billion parameters. The results reveal that (1) LMEB provides a reasonable level of difficulty; (2) Larger models do not always perform better; (3) LMEB and MTEB exhibit orthogonality. This suggests that the field has yet to converge on a universal model capable of excelling across all memory retrieval tasks, and that performance in traditional passage retrieval may not generalize to long-horizon memory retrieval. In summary, by providing a standardized and reproducible evaluation framework, LMEB fills a crucial gap in memory embedding evaluation, driving further advancements in text embedding for handling long-term, context-dependent memory retrieval. LMEB is available at https://github.com/KaLM-Embedding/LMEB.
From Shallow to Deep: Pinning Semantic Intent via Causal GRPO
Mar 03, 2026Large Language Models remain vulnerable to adversarial prefix attacks (e.g., ``Sure, here is'') despite robust standard safety. We diagnose this vulnerability as Shallow Safety Alignment, stemming from a pathology we term semantic representation decay: as the model generates compliant prefixes, its internal malicious intent signal fades. To address this, we propose Two-Stage Causal-GRPO (TSC-GRPO), a framework designed to achieve intent pinning. First, grounded in causal identifiability theory, we train a causal intent probe to disentangle invariant intent from stylistic perturbations. Second, we internalize this causal awareness into the policy via Group Relative Policy Optimization. By employing a cumulative causal penalty within ``fork-in-the-road'' training scenarios, we force the model to learn that accumulating harmful tokens monotonically decreases reward, enabling robust late-stage refusals. Experiments show that TSC-GRPO significantly outperforms baselines in defending against jailbreak attacks while preserving general utility.
Causal Front-Door Adjustment for Robust Jailbreak Attacks on LLMs
Feb 05, 2026Safety alignment mechanisms in Large Language Models (LLMs) often operate as latent internal states, obscuring the model's inherent capabilities. Building on this observation, we model the safety mechanism as an unobserved confounder from a causal perspective. Then, we propose the \textbf{C}ausal \textbf{F}ront-Door \textbf{A}djustment \textbf{A}ttack ({\textbf{CFA}}$^2$) to jailbreak LLM, which is a framework that leverages Pearl's Front-Door Criterion to sever the confounding associations for robust jailbreaking. Specifically, we employ Sparse Autoencoders (SAEs) to physically strip defense-related features, isolating the core task intent. We further reduce computationally expensive marginalization to a deterministic intervention with low inference complexity. Experiments demonstrate that {CFA}$^2$ achieves state-of-the-art attack success rates while offering a mechanistic interpretation of the jailbreaking process.
A Specialized Large Language Model for Clinical Reasoning and Diagnosis in Rare Diseases
Nov 18, 2025Rare diseases affect hundreds of millions worldwide, yet diagnosis often spans years. Convectional pipelines decouple noisy evidence extraction from downstream inferential diagnosis, and general/medical large language models (LLMs) face scarce real world electronic health records (EHRs), stale domain knowledge, and hallucinations. We assemble a large, domain specialized clinical corpus and a clinician validated reasoning set, and develop RareSeek R1 via staged instruction tuning, chain of thought learning, and graph grounded retrieval. Across multicenter EHR narratives and public benchmarks, RareSeek R1 attains state of the art accuracy, robust generalization, and stability under noisy or overlapping phenotypes. Augmented retrieval yields the largest gains when narratives pair with prioritized variants by resolving ambiguity and aligning candidates to mechanisms. Human studies show performance on par with experienced physicians and consistent gains in assistive use. Notably, transparent reasoning highlights decisive non phenotypic evidence (median 23.1%, such as imaging, interventions, functional tests) underpinning many correct diagnoses. This work advances a narrative first, knowledge integrated reasoning paradigm that shortens the diagnostic odyssey and enables auditable, clinically translatable decision support.
LM-mixup: Text Data Augmentation via Language Model based Mixup
Oct 23, 2025Instruction tuning is crucial for aligning Large Language Models (LLMs), yet the quality of instruction-following data varies significantly. While high-quality data is paramount, it is often scarce; conversely, abundant low-quality data is frequently discarded, leading to substantial information loss. Existing data augmentation methods struggle to augment this low-quality data effectively, and the evaluation of such techniques remains poorly defined. To address this, we formally define the task of Instruction Distillation: distilling multiple low-quality and redundant inputs into high-quality and coherent instruction-output pairs. Specifically, we introduce a comprehensive data construction pipeline to create MIXTURE, a 144K-sample dataset pairing low-quality or semantically redundant imperfect instruction clusters with their high-quality distillations. We then introduce LM-Mixup, by first performing supervised fine-tuning on MIXTURE and then optimizing it with reinforcement learning. This process uses three complementary reward signals: quality, semantic alignment, and format compliance, via Group Relative Policy Optimization (GRPO). We demonstrate that LM-Mixup effectively augments imperfect datasets: fine-tuning LLMs on its distilled data, which accounts for only about 3% of the entire dataset, not only surpasses full-dataset training but also competes with state-of-the-art high-quality data selection methods across multiple benchmarks. Our work establishes that low-quality data is a valuable resource when properly distilled and augmented with LM-Mixup, significantly enhancing the efficiency and performance of instruction-tuned LLMs.
KaLM-Embedding-V2: Superior Training Techniques and Data Inspire A Versatile Embedding Model
Jun 26, 2025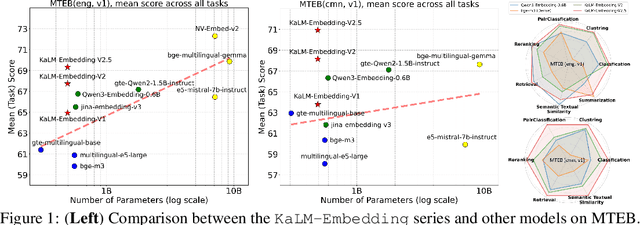
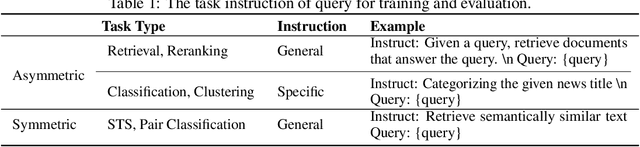


In this paper, we propose KaLM-Embedding-V2, a versatile and compact embedding model, which achieves impressive performance in general-purpose text embedding tasks by leveraging superior training techniques and data. Our key innovations include: (1) To better align the architecture with representation learning, we remove the causal attention mask and adopt a fully bidirectional transformer with simple yet effective mean-pooling to produce fixed-length embeddings; (2) We employ a multi-stage training pipeline: (i) pre-training on large-scale weakly supervised open-source corpora; (ii) fine-tuning on high-quality retrieval and non-retrieval datasets; and (iii) model-soup parameter averaging for robust generalization. Besides, we introduce a focal-style reweighting mechanism that concentrates learning on difficult samples and an online hard-negative mixing strategy to continuously enrich hard negatives without expensive offline mining; (3) We collect over 20 categories of data for pre-training and 100 categories of data for fine-tuning, to boost both the performance and generalization of the embedding model. Extensive evaluations on the Massive Text Embedding Benchmark (MTEB) Chinese and English show that our model significantly outperforms others of comparable size, and competes with 3x, 14x, 18x, and 26x larger embedding models, setting a new standard for a versatile and compact embedding model with less than 1B parameters.
Recognition through Reasoning: Reinforcing Image Geo-localization with Large Vision-Language Models
Jun 17, 2025Previous methods for image geo-localization have typically treated the task as either classification or retrieval, often relying on black-box decisions that lack interpretability. The rise of large vision-language models (LVLMs) has enabled a rethinking of geo-localization as a reasoning-driven task grounded in visual cues. However, two major challenges persist. On the data side, existing reasoning-focused datasets are primarily based on street-view imagery, offering limited scene diversity and constrained viewpoints. On the modeling side, current approaches predominantly rely on supervised fine-tuning, which yields only marginal improvements in reasoning capabilities. To address these challenges, we propose a novel pipeline that constructs a reasoning-oriented geo-localization dataset, MP16-Reason, using diverse social media images. We introduce GLOBE, Group-relative policy optimization for Locatability assessment and Optimized visual-clue reasoning, yielding Bi-objective geo-Enhancement for the VLM in recognition and reasoning. GLOBE incorporates task-specific rewards that jointly enhance locatability assessment, visual clue reasoning, and geolocation accuracy. Both qualitative and quantitative results demonstrate that GLOBE outperforms state-of-the-art open-source LVLMs on geo-localization tasks, particularly in diverse visual scenes, while also generating more insightful and interpretable reasoning trajectories.
Optimizing Singular Spectrum for Large Language Model Compression
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable capabilities, yet prohibitive parameter complexity often hinders their deployment. Existing singular value decomposition (SVD) based compression methods simply deem singular values as importance scores of decomposed components. However, this importance ordered by singular values does not necessarily correlate with the performance of a downstream task. In this work, we introduce SoCo (Singular spectrum optimization for large language model Compression), a novel compression framework that learns to rescale the decomposed components of SVD in a data-driven manner. Concretely, we employ a learnable diagonal matrix to assign importance scores for singular spectrum and develop a three-stage training process that progressively refines these scores from initial coarse compression to fine-grained sparsification-thereby striking an effective balance between aggressive model compression and performance preservation. Thanks to the learnable singular spectrum, SoCo adaptively prunes components according to the sparsified importance scores, rather than relying on the fixed order of singular values. More importantly, the remaining components with amplified importance scores can compensate for the loss of the pruned ones. Experimental evaluations across multiple LLMs and benchmarks demonstrate that SoCo surpasses the state-of-the-art methods in model compression.
Collaborative Diffusion Model for Recommender System
Jan 31, 2025



Diffusion-based recommender systems (DR) have gained increasing attention for their advanced generative and denoising capabilities. However, existing DR face two central limitations: (i) a trade-off between enhancing generative capacity via noise injection and retaining the loss of personalized information. (ii) the underutilization of rich item-side information. To address these challenges, we present a Collaborative Diffusion model for Recommender System (CDiff4Rec). Specifically, CDiff4Rec generates pseudo-users from item features and leverages collaborative signals from both real and pseudo personalized neighbors identified through behavioral similarity, thereby effectively reconstructing nuanced user preferences. Experimental results on three public datasets show that CDiff4Rec outperforms competitors by effectively mitigating the loss of personalized information through the integration of item content and collaborative signals.
HiMix: Reducing Computational Complexity in Large Vision-Language Models
Jan 17, 2025Benefiting from recent advancements in large language models and modality alignment techniques, existing Large Vision-Language Models(LVLMs) have achieved prominent performance across a wide range of scenarios. However, the excessive computational complexity limits the widespread use of these models in practical applications. We argue that one main bottleneck in computational complexity is caused by the involvement of redundant vision sequences in model computation. This is inspired by a reassessment of the efficiency of vision and language information transmission in the language decoder of LVLMs. Then, we propose a novel hierarchical vision-language interaction mechanism called Hierarchical Vision injection for Mixture Attention (HiMix). In HiMix, only the language sequence undergoes full forward propagation, while the vision sequence interacts with the language at specific stages within each language decoder layer. It is striking that our approach significantly reduces computational complexity with minimal performance loss. Specifically, HiMix achieves a 10x reduction in the computational cost of the language decoder across multiple LVLM models while maintaining comparable performance. This highlights the advantages of our method, and we hope our research brings new perspectives to the field of vision-language understanding. Project Page: https://xuange923.github.io/HiMix