 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurveillanceVQA-589K: A Benchmark for Comprehensive Surveillance Video-Language Understanding with Large Models
May 19, 2025Understanding surveillance video content remains a critical yet underexplored challenge in vision-language research, particularly due to its real-world complexity, irregular event dynamics, and safety-critical implications. In this work, we introduce SurveillanceVQA-589K, the largest open-ended video question answering benchmark tailored to the surveillance domain. The dataset comprises 589,380 QA pairs spanning 12 cognitively diverse question types, including temporal reasoning, causal inference, spatial understanding, and anomaly interpretation, across both normal and abnormal video scenarios. To construct the benchmark at scale, we design a hybrid annotation pipeline that combines temporally aligned human-written captions with Large Vision-Language Model-assisted QA generation using prompt-based techniques. We also propose a multi-dimensional evaluation protocol to assess contextual, temporal, and causal comprehension. We evaluate eight LVLMs under this framework, revealing significant performance gaps, especially in causal and anomaly-related tasks, underscoring the limitations of current models in real-world surveillance contexts. Our benchmark provides a practical and comprehensive resource for advancing video-language understanding in safety-critical applications such as intelligent monitoring, incident analysis, and autonomous decision-making.
HiMix: Reducing Computational Complexity in Large Vision-Language Models
Jan 17, 2025Benefiting from recent advancements in large language models and modality alignment techniques, existing Large Vision-Language Models(LVLMs) have achieved prominent performance across a wide range of scenarios. However, the excessive computational complexity limits the widespread use of these models in practical applications. We argue that one main bottleneck in computational complexity is caused by the involvement of redundant vision sequences in model computation. This is inspired by a reassessment of the efficiency of vision and language information transmission in the language decoder of LVLMs. Then, we propose a novel hierarchical vision-language interaction mechanism called Hierarchical Vision injection for Mixture Attention (HiMix). In HiMix, only the language sequence undergoes full forward propagation, while the vision sequence interacts with the language at specific stages within each language decoder layer. It is striking that our approach significantly reduces computational complexity with minimal performance loss. Specifically, HiMix achieves a 10x reduction in the computational cost of the language decoder across multiple LVLM models while maintaining comparable performance. This highlights the advantages of our method, and we hope our research brings new perspectives to the field of vision-language understanding. Project Page: https://xuange923.github.io/HiMix
UCF-Crime Annotation: A Benchmark for Surveillance Video-and-Language Understanding
Sep 25, 2023Surveillance videos are an essential component of daily life with various critical applications, particularly in public security. However, current surveillance video tasks mainly focus on classifying and localizing anomalous events. Existing methods are limited to detecting and classifying the predefined events with unsatisfactory generalization ability and semantic understanding, although they have obtained considerable performance. To address this issue, we propose constructing the first multimodal surveillance video dataset by manually annotating the real-world surveillance dataset UCF-Crime with fine-grained event content and timing. Our newly annotated dataset, UCA (UCF-Crime Annotation), provides a novel benchmark for multimodal surveillance video analysis. It not only describes events in detailed descriptions but also provides precise temporal grounding of the events in 0.1-second intervals. UCA contains 20,822 sentences, with an average length of 23 words, and its annotated videos are as long as 102 hours. Furthermore, we benchmark the state-of-the-art models of multiple multimodal tasks on this newly created dataset, including temporal sentence grounding in videos, video captioning, and dense video captioning. Through our experiments, we found that mainstream models used in previously publicly available datasets perform poorly on multimodal surveillance video scenarios, which highlights the necessity of constructing this dataset. The link to our dataset and code is provided at: https://github.com/Xuange923/UCA-dataset.
On Learning Semantic Representations for Million-Scale Free-Hand Sketches
Jul 07, 2020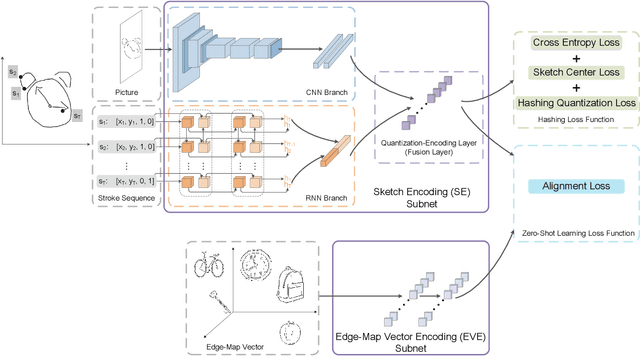
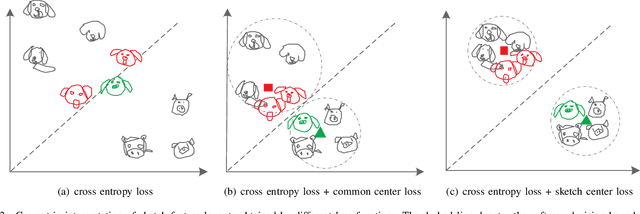
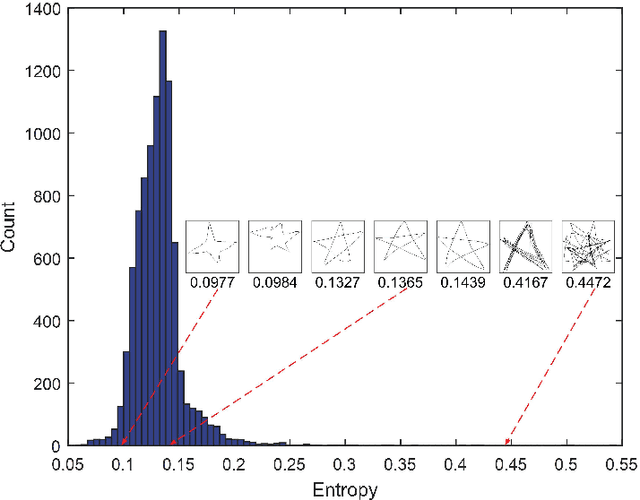

In this paper, we study learning semantic representations for million-scale free-hand sketches. This is highly challenging due to the domain-unique traits of sketches, e.g., diverse, sparse, abstract, noisy. We propose a dual-branch CNNRNN network architecture to represent sketches, which simultaneously encodes both the static and temporal patterns of sketch strokes. Based on this architecture, we further explore learning the sketch-oriented semantic representations in two challenging yet practical settings, i.e., hashing retrieval and zero-shot recognition on million-scale sketches. Specifically, we use our dual-branch architecture as a universal representation framework to design two sketch-specific deep models: (i) We propose a deep hashing model for sketch retrieval, where a novel hashing loss is specifically designed to accommodate both the abstract and messy traits of sketches. (ii) We propose a deep embedding model for sketch zero-shot recognition, via collecting a large-scale edge-map dataset and proposing to extract a set of semantic vectors from edge-maps as the semantic knowledge for sketch zero-shot domain alignment. Both deep models are evaluated by comprehensive experiments on million-scale sketches and outperform the state-of-the-art competitors.
Signal-to-Noise Ratio: A Robust Distance Metric for Deep Metric Learning
Apr 04, 2019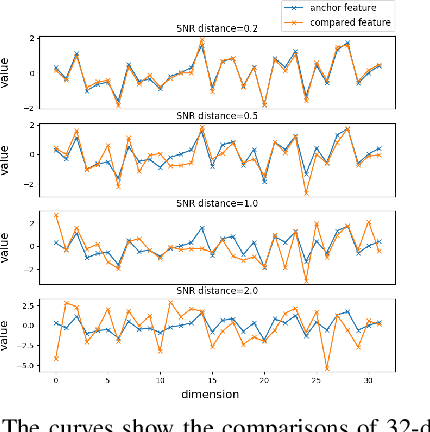
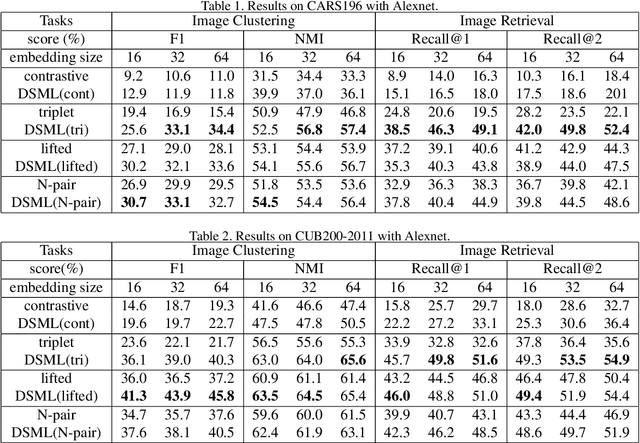
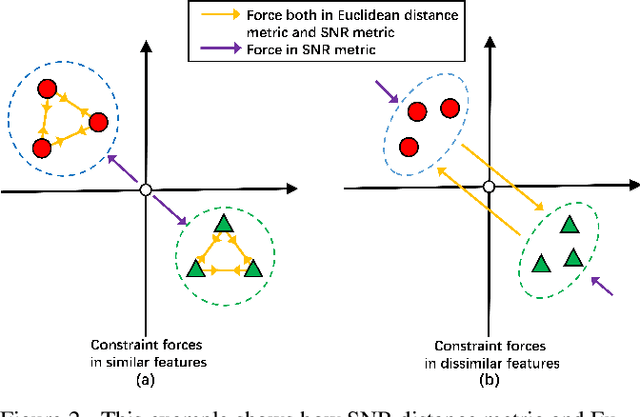
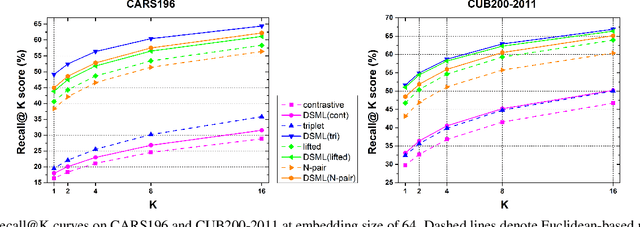
Deep metric learning, which learns discriminative features to process image clustering and retrieval tasks, has attracted extensive attention in recent years. A number of deep metric learning methods, which ensure that similar examples are mapped close to each other and dissimilar examples are mapped farther apart, have been proposed to construct effective structures for loss functions and have shown promising results. In this paper, different from the approaches on learning the loss structures, we propose a robust SNR distance metric based on Signal-to-Noise Ratio (SNR) for measuring the similarity of image pairs for deep metric learning. By exploring the properties of our SNR distance metric from the view of geometry space and statistical theory, we analyze the properties of our metric and show that it can preserve the semantic similarity between image pairs, which well justify its suitability for deep metric learning. Compared with Euclidean distance metric, our SNR distance metric can further jointly reduce the intra-class distances and enlarge the inter-class distances for learned features. Leveraging our SNR distance metric, we propose Deep SNR-based Metric Learning (DSML) to generate discriminative feature embeddings. By extensive experiments on three widely adopted benchmarks, including CARS196, CUB200-2011 and CIFAR10, our DSML has shown its superiority over other state-of-the-art methods. Additionally, we extend our SNR distance metric to deep hashing learning, and conduct experiments on two benchmarks, including CIFAR10 and NUS-WIDE, to demonstrate the effectiveness and generality of our SNR distance metric.
SketchMate: Deep Hashing for Million-Scale Human Sketch Retrieval
Apr 04, 2018
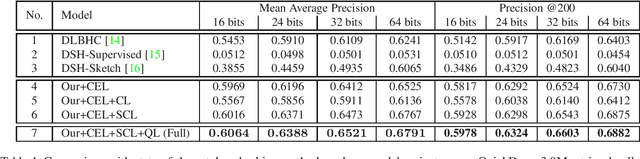
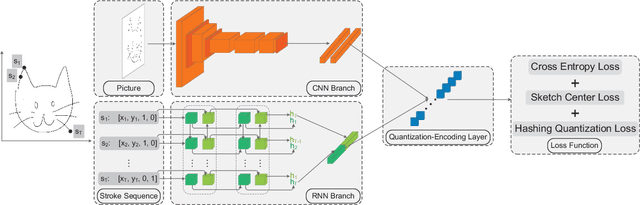
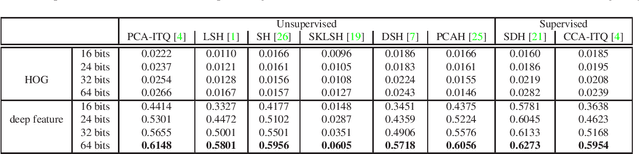
We propose a deep hashing framework for sketch retrieval that, for the first time, works on a multi-million scale human sketch dataset. Leveraging on this large dataset, we explore a few sketch-specific traits that were otherwise under-studied in prior literature. Instead of following the conventional sketch recognition task, we introduce the novel problem of sketch hashing retrieval which is not only more challenging, but also offers a better testbed for large-scale sketch analysis, since: (i) more fine-grained sketch feature learning is required to accommodate the large variations in style and abstraction, and (ii) a compact binary code needs to be learned at the same time to enable efficient retrieval. Key to our network design is the embedding of unique characteristics of human sketch, where (i) a two-branch CNN-RNN architecture is adapted to explore the temporal ordering of strokes, and (ii) a novel hashing loss is specifically designed to accommodate both the temporal and abstract traits of sketches. By working with a 3.8M sketch dataset, we show that state-of-the-art hashing models specifically engineered for static images fail to perform well on temporal sketch data. Our network on the other hand not only offers the best retrieval performance on various code sizes, but also yields the best generalization performance under a zero-shot setting and when re-purposed for sketch recognition. Such superior performances effectively demonstrate the benefit of our sketch-specific design.