 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learning Semantic Representations for Million-Scale Free-Hand Sketches
Jul 07, 2020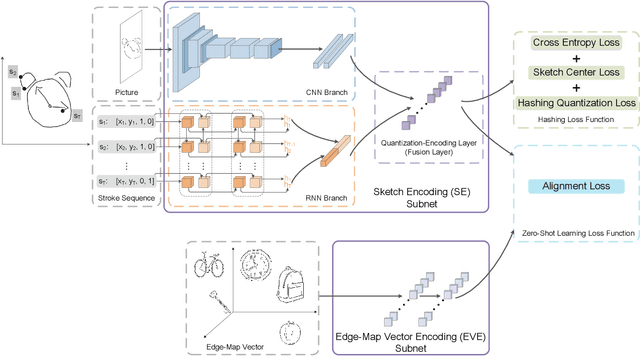
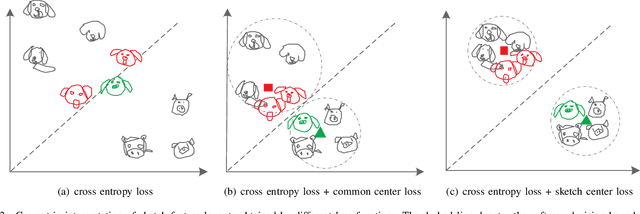
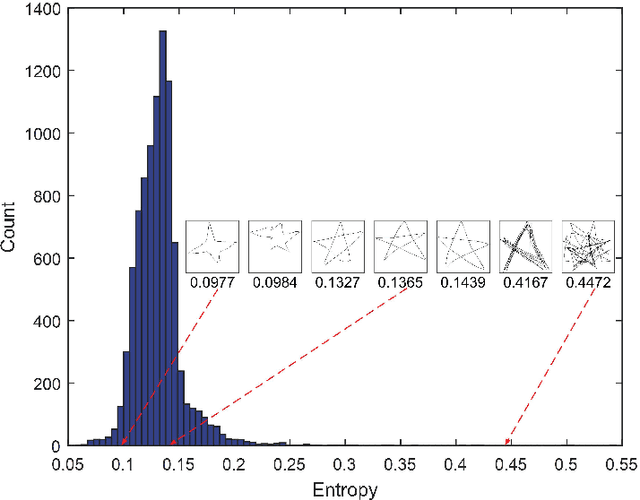

In this paper, we study learning semantic representations for million-scale free-hand sketches. This is highly challenging due to the domain-unique traits of sketches, e.g., diverse, sparse, abstract, noisy. We propose a dual-branch CNNRNN network architecture to represent sketches, which simultaneously encodes both the static and temporal patterns of sketch strokes. Based on this architecture, we further explore learning the sketch-oriented semantic representations in two challenging yet practical settings, i.e., hashing retrieval and zero-shot recognition on million-scale sketches. Specifically, we use our dual-branch architecture as a universal representation framework to design two sketch-specific deep models: (i) We propose a deep hashing model for sketch retrieval, where a novel hashing loss is specifically designed to accommodate both the abstract and messy traits of sketches. (ii) We propose a deep embedding model for sketch zero-shot recognition, via collecting a large-scale edge-map dataset and proposing to extract a set of semantic vectors from edge-maps as the semantic knowledge for sketch zero-shot domain alignment. Both deep models are evaluated by comprehensive experiments on million-scale sketches and outperform the state-of-the-art competitors.
SketchMate: Deep Hashing for Million-Scale Human Sketch Retrieval
Apr 04, 2018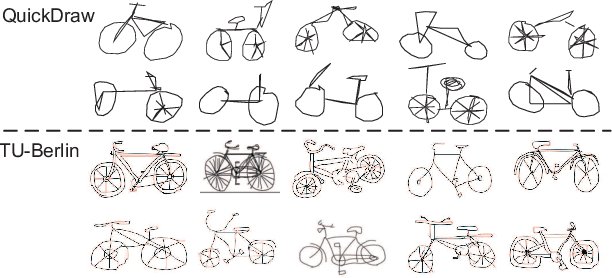
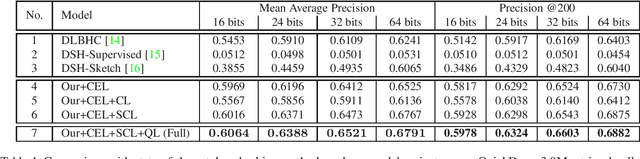
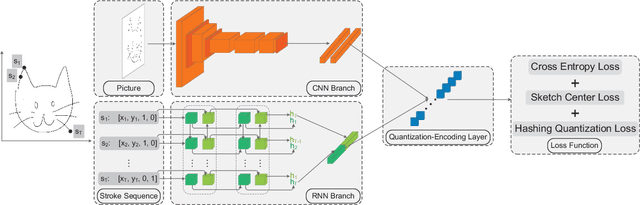
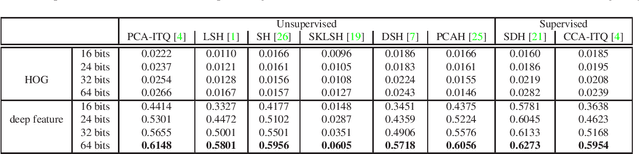
We propose a deep hashing framework for sketch retrieval that, for the first time, works on a multi-million scale human sketch dataset. Leveraging on this large dataset, we explore a few sketch-specific traits that were otherwise under-studied in prior literature. Instead of following the conventional sketch recognition task, we introduce the novel problem of sketch hashing retrieval which is not only more challenging, but also offers a better testbed for large-scale sketch analysis, since: (i) more fine-grained sketch feature learning is required to accommodate the large variations in style and abstraction, and (ii) a compact binary code needs to be learned at the same time to enable efficient retrieval. Key to our network design is the embedding of unique characteristics of human sketch, where (i) a two-branch CNN-RNN architecture is adapted to explore the temporal ordering of strokes, and (ii) a novel hashing loss is specifically designed to accommodate both the temporal and abstract traits of sketches. By working with a 3.8M sketch dataset, we show that state-of-the-art hashing models specifically engineered for static images fail to perform well on temporal sketch data. Our network on the other hand not only offers the best retrieval performance on various code sizes, but also yields the best generalization performance under a zero-shot setting and when re-purposed for sketch recognition. Such superior performances effectively demonstrate the benefit of our sketch-specific design.
Cross-modal Subspace Learning for Fine-grained Sketch-based Image Retrieval
May 28, 2017

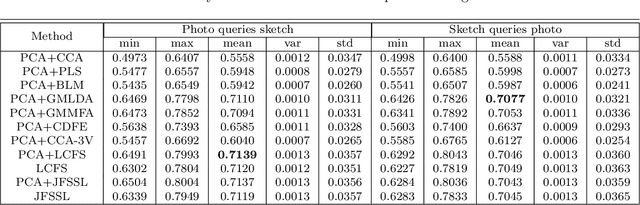
Sketch-based image retrieval (SBIR) is challenging due to the inherent domain-gap between sketch and photo. Compared with pixel-perfect depictions of photos, sketches are iconic renderings of the real world with highly abstract. Therefore, matching sketch and photo directly using low-level visual clues are unsufficient, since a common low-level subspace that traverses semantically across the two modalities is non-trivial to establish. Most existing SBIR studies do not directly tackle this cross-modal problem. This naturally motivates us to explore the effectiveness of cross-modal retrieval methods in SBIR, which have been applied in the image-text matching successfully. In this paper, we introduce and compare a series of state-of-the-art cross-modal subspace learning methods and benchmark them on two recently released fine-grained SBIR datasets. Through thorough examination of the experimental results, we have demonstrated that the subspace learning can effectively model the sketch-photo domain-gap. In addition we draw a few key insights to drive future research.