 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemVideo: Reconstructs What You Watch from Brain Activity via Hierarchical Semantic Guidance
Feb 25, 2026Reconstructing dynamic visual experiences from brain activity provides a compelling avenue for exploring the neural mechanisms of human visual perception. While recent progress in fMRI-based image reconstruction has been notable, extending this success to video reconstruction remains a significant challenge. Current fMRI-to-video reconstruction approaches consistently encounter two major shortcomings: (i) inconsistent visual representations of salient objects across frames, leading to appearance mismatches; (ii) poor temporal coherence, resulting in motion misalignment or abrupt frame transitions. To address these limitations, we introduce SemVideo, a novel fMRI-to-video reconstruction framework guided by hierarchical semantic information. At the core of SemVideo is SemMiner, a hierarchical guidance module that constructs three levels of semantic cues from the original video stimulus: static anchor descriptions, motion-oriented narratives, and holistic summaries. Leveraging this semantic guidance, SemVideo comprises three key components: a Semantic Alignment Decoder that aligns fMRI signals with CLIP-style embeddings derived from SemMiner, a Motion Adaptation Decoder that reconstructs dynamic motion patterns using a novel tripartite attention fusion architecture, and a Conditional Video Render that leverages hierarchical semantic guidance for video reconstruction. Experiments conducted on the CC2017 and HCP datasets demonstrate that SemVideo achieves superior performance in both semantic alignment and temporal consistency, setting a new state-of-the-art in fMRI-to-video reconstruction.
SynMind: Reducing Semantic Hallucination in fMRI-Based Image Reconstruction
Jan 25, 2026Recent advances in fMRI-based image reconstruction have achieved remarkable photo-realistic fidelity. Yet, a persistent limitation remains: while reconstructed images often appear naturalistic and holistically similar to the target stimuli, they frequently suffer from severe semantic misalignment -- salient objects are often replaced or hallucinated despite high visual quality. In this work, we address this limitation by rethinking the role of explicit semantic interpretation in fMRI decoding. We argue that existing methods rely too heavily on entangled visual embeddings which prioritize low-level appearance cues -- such as texture and global gist -- over explicit semantic identity. To overcome this, we parse fMRI signals into rich, sentence-level semantic descriptions that mirror the hierarchical and compositional nature of human visual understanding. We achieve this by leveraging grounded VLMs to generate synthetic, human-like, multi-granularity textual representations that capture object identities and spatial organization. Built upon this foundation, we propose SynMind, a framework that integrates these explicit semantic encodings with visual priors to condition a pretrained diffusion model. Extensive experiments demonstrate that SynMind outperforms state-of-the-art methods across most quantitative metrics. Notably, by offloading semantic reasoning to our text-alignment module, SynMind surpasses competing methods based on SDXL while using the much smaller Stable Diffusion 1.4 and a single consumer GPU. Large-scale human evaluations further confirm that SynMind produces reconstructions more consistent with human visual perception. Neurovisualization analyses reveal that SynMind engages broader and more semantically relevant brain regions, mitigating the over-reliance on high-level visual areas.
Annotation-Free Human Sketch Quality Assessment
Jul 28, 2025As lovely as bunnies are, your sketched version would probably not do them justice (Fig.~\ref{fig:intro}). This paper recognises this very problem and studies sketch quality assessment for the first time -- letting you find these badly drawn ones. Our key discovery lies in exploiting the magnitude ($L_2$ norm) of a sketch feature as a quantitative quality metric. We propose Geometry-Aware Classification Layer (GACL), a generic method that makes feature-magnitude-as-quality-metric possible and importantly does it without the need for specific quality annotations from humans. GACL sees feature magnitude and recognisability learning as a dual task, which can be simultaneously optimised under a neat cross-entropy classification loss with theoretic guarantee. This gives GACL a nice geometric interpretation (the better the quality, the easier the recognition), and makes it agnostic to both network architecture changes and the underlying sketch representation. Through a large scale human study of 160,000 \doublecheck{trials}, we confirm the agreement between our GACL-induced metric and human quality perception. We further demonstrate how such a quality assessment capability can for the first time enable three practical sketch applications. Interestingly, we show GACL not only works on abstract visual representations such as sketch but also extends well to natural images on the problem of image quality assessment (IQA). Last but not least, we spell out the general properties of GACL as general-purpose data re-weighting strategy and demonstrate its applications in vertical problems such as noisy label cleansing. Code will be made publicly available at github.com/yanglan0225/SketchX-Quantifying-Sketch-Quality.
VersaGen: Unleashing Versatile Visual Control for Text-to-Image Synthesis
Dec 17, 2024



Despite the rapid advancements in text-to-image (T2I) synthesis, enabling precise visual control remains a significant challenge. Existing works attempted to incorporate multi-facet controls (text and sketch), aiming to enhance the creative control over generated images. However, our pilot study reveals that the expressive power of humans far surpasses the capabilities of current methods. Users desire a more versatile approach that can accommodate their diverse creative intents, ranging from controlling individual subjects to manipulating the entire scene composition. We present VersaGen, a generative AI agent that enables versatile visual control in T2I synthesis. VersaGen admits four types of visual controls: i) single visual subject; ii) multiple visual subjects; iii) scene background; iv) any combination of the three above or merely no control at all. We train an adaptor upon a frozen T2I model to accommodate the visual information into the text-dominated diffusion process. We introduce three optimization strategies during the inference phase of VersaGen to improve generation results and enhance user experience. Comprehensive experiments on COCO and Sketchy validate the effectiveness and flexibility of VersaGen, as evidenced by both qualitative and quantitative results.
Wired Perspectives: Multi-View Wire Art Embraces Generative AI
Nov 26, 2023Creating multi-view wire art (MVWA), a static 3D sculpture with diverse interpretations from different viewpoints, is a complex task even for skilled artists. In response, we present DreamWire, an AI system enabling everyone to craft MVWA easily. Users express their vision through text prompts or scribbles, freeing them from intricate 3D wire organisation. Our approach synergises 3D B\'ezier curves, Prim's algorithm, and knowledge distillation from diffusion models or their variants (e.g., ControlNet). This blend enables the system to represent 3D wire art, ensuring spatial continuity and overcoming data scarcity. Extensive evaluation and analysis are conducted to shed insight on the inner workings of the proposed system, including the trade-off between connectivity and visual aesthetics.
SketchXAI: A First Look at Explainability for Human Sketches
Apr 23, 2023This paper, for the very first time, introduces human sketches to the landscape of XAI (Explainable Artificial Intelligence). We argue that sketch as a ``human-centred'' data form, represents a natural interface to study explainability. We focus on cultivating sketch-specific explainability designs. This starts by identifying strokes as a unique building block that offers a degree of flexibility in object construction and manipulation impossible in photos. Following this, we design a simple explainability-friendly sketch encoder that accommodates the intrinsic properties of strokes: shape, location, and order. We then move on to define the first ever XAI task for sketch, that of stroke location inversion SLI. Just as we have heat maps for photos, and correlation matrices for text, SLI offers an explainability angle to sketch in terms of asking a network how well it can recover stroke locations of an unseen sketch. We offer qualitative results for readers to interpret as snapshots of the SLI process in the paper, and as GIFs on the project page. A minor but interesting note is that thanks to its sketch-specific design, our sketch encoder also yields the best sketch recognition accuracy to date while having the smallest number of parameters. The code is available at \url{https://sketchxai.github.io}.
Making a Bird AI Expert Work for You and Me
Dec 06, 2021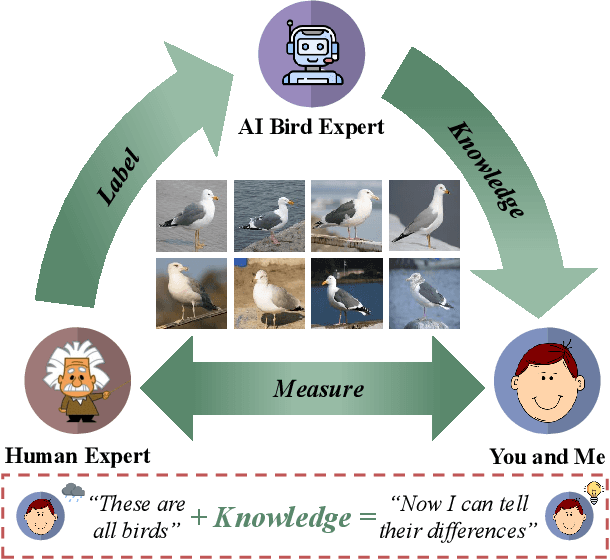



As powerful as fine-grained visual classification (FGVC) is, responding your query with a bird name of "Whip-poor-will" or "Mallard" probably does not make much sense. This however commonly accepted in the literature, underlines a fundamental question interfacing AI and human -- what constitutes transferable knowledge for human to learn from AI? This paper sets out to answer this very question using FGVC as a test bed. Specifically, we envisage a scenario where a trained FGVC model (the AI expert) functions as a knowledge provider in enabling average people (you and me) to become better domain experts ourselves, i.e. those capable in distinguishing between "Whip-poor-will" and "Mallard". Fig. 1 lays out our approach in answering this question. Assuming an AI expert trained using expert human labels, we ask (i) what is the best transferable knowledge we can extract from AI, and (ii) what is the most practical means to measure the gains in expertise given that knowledge? On the former, we propose to represent knowledge as highly discriminative visual regions that are expert-exclusive. For that, we devise a multi-stage learning framework, which starts with modelling visual attention of domain experts and novices before discriminatively distilling their differences to acquire the expert exclusive knowledge. For the latter, we simulate the evaluation process as book guide to best accommodate the learning practice of what is accustomed to humans. A comprehensive human study of 15,000 trials shows our method is able to consistently improve people of divergent bird expertise to recognise once unrecognisable birds. Interestingly, our approach also leads to improved conventional FGVC performance when the extracted knowledge defined is utilised as means to achieve discriminative localisation. Codes are available at: https://github.com/PRIS-CV/Making-a-Bird-AI-Expert-Work-for-You-and-Me
Your "Labrador" is My "Dog": Fine-Grained, or Not
Nov 18, 2020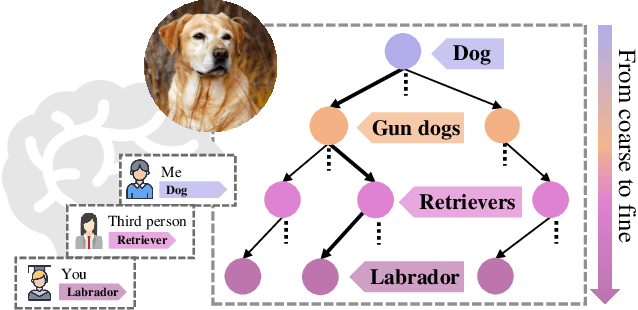

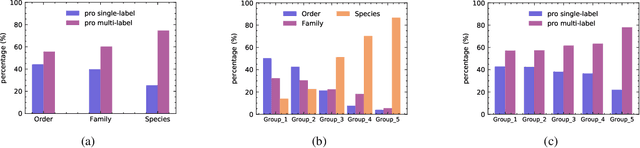
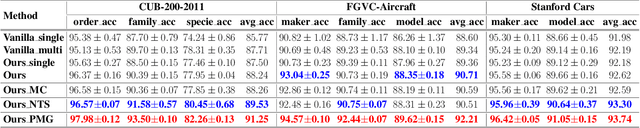
Whether what you see in Figure 1 is a "labrador" or a "dog", is the question we ask in this paper. While fine-grained visual classification (FGVC) strives to arrive at the former, for the majority of us non-experts just "dog" would probably suffice. The real question is therefore -- how can we tailor for different fine-grained definitions under divergent levels of expertise. For that, we re-envisage the traditional setting of FGVC, from single-label classification, to that of top-down traversal of a pre-defined coarse-to-fine label hierarchy -- so that our answer becomes "dog"-->"gun dog"-->"retriever"-->"labrador". To approach this new problem, we first conduct a comprehensive human study where we confirm that most participants prefer multi-granularity labels, regardless whether they consider themselves experts. We then discover the key intuition that: coarse-level label prediction exacerbates fine-grained feature learning, yet fine-level feature betters the learning of coarse-level classifier. This discovery enables us to design a very simple albeit surprisingly effective solution to our new problem, where we (i) leverage level-specific classification heads to disentangle coarse-level features with fine-grained ones, and (ii) allow finer-grained features to participate in coarser-grained label predictions, which in turn helps with better disentanglement. Experiments show that our method achieves superior performance in the new FGVC setting, and performs better than state-of-the-art on traditional single-label FGVC problem as well. Thanks to its simplicity, our method can be easily implemented on top of any existing FGVC frameworks and is parameter-free.
Deep Factorised Inverse-Sketching
Aug 07, 2018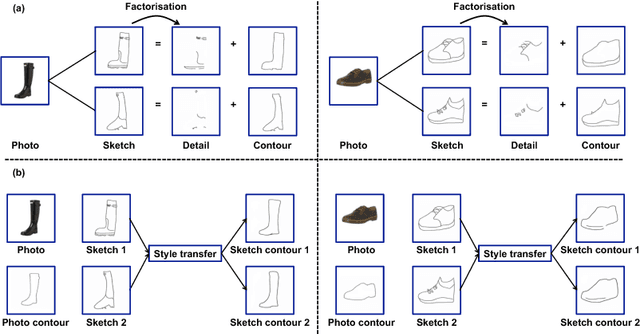
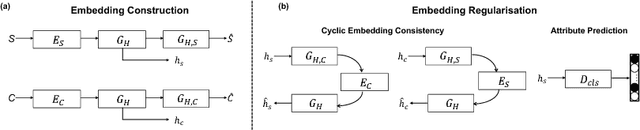
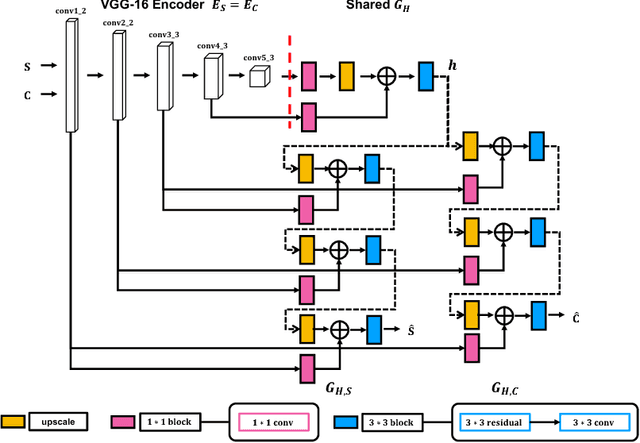
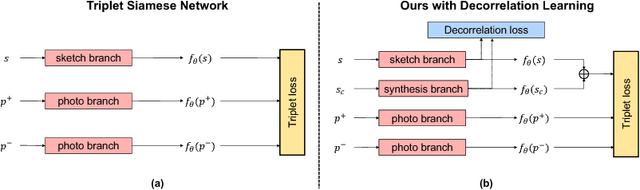
Modelling human free-hand sketches has become topical recently, driven by practical applications such as fine-grained sketch based image retrieval (FG-SBIR). Sketches are clearly related to photo edge-maps, but a human free-hand sketch of a photo is not simply a clean rendering of that photo's edge map. Instead there is a fundamental process of abstraction and iconic rendering, where overall geometry is warped and salient details are selectively included. In this paper we study this sketching process and attempt to invert it. We model this inversion by translating iconic free-hand sketches to contours that resemble more geometrically realistic projections of object boundaries, and separately factorise out the salient added details. This factorised re-representation makes it easier to match a free-hand sketch to a photo instance of an object. Specifically, we propose a novel unsupervised image style transfer model based on enforcing a cyclic embedding consistency constraint. A deep FG-SBIR model is then formulated to accommodate complementary discriminative detail from each factorised sketch for better matching with the corresponding photo. Our method is evaluated both qualitatively and quantitatively to demonstrate its superiority over a number of state-of-the-art alternatives for style transfer and FG-SBIR.
Universal Perceptual Grouping
Aug 07, 2018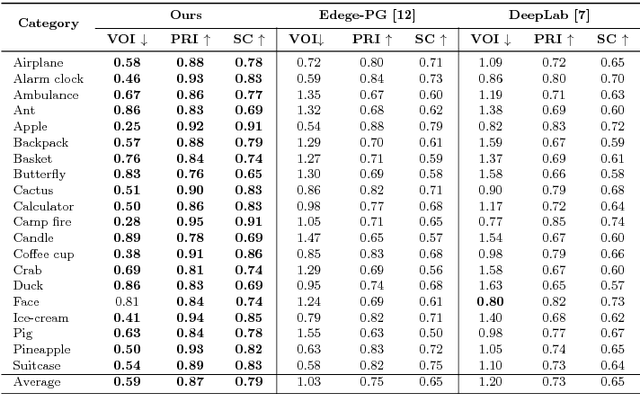
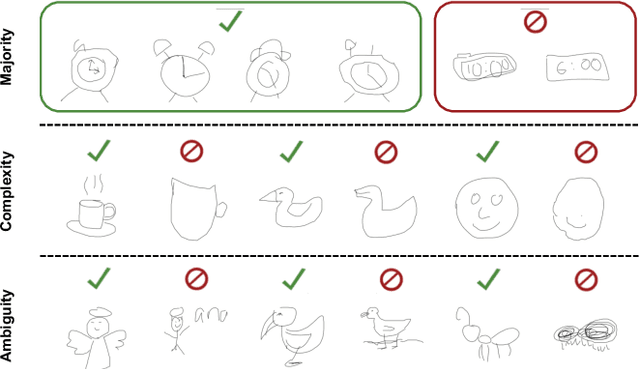
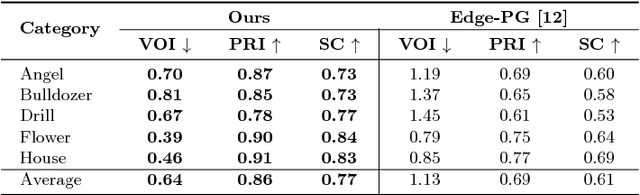
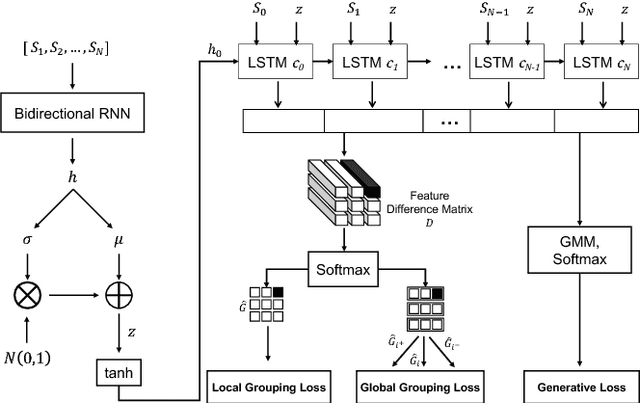
In this work we aim to develop a universal sketch grouper. That is, a grouper that can be applied to sketches of any category in any domain to group constituent strokes/segments into semantically meaningful object parts. The first obstacle to this goal is the lack of large-scale datasets with grouping annotation. To overcome this, we contribute the largest sketch perceptual grouping (SPG) dataset to date, consisting of 20,000 unique sketches evenly distributed over 25 object categories. Furthermore, we propose a novel deep universal perceptual grouping model. The model is learned with both generative and discriminative losses. The generative losses improve the generalisation ability of the model to unseen object categories and datasets. The discriminative losses include a local grouping loss and a novel global grouping loss to enforce global grouping consistency. We show that the proposed model significantly outperforms the state-of-the-art groupers. Further, we show that our grouper is useful for a number of sketch analysis tasks including sketch synthesis and fine-grained sketch-based image retrieval (FG-SBIR).