 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Potential of Diffusion Priors in Blind Face Restoration
Aug 12, 2025
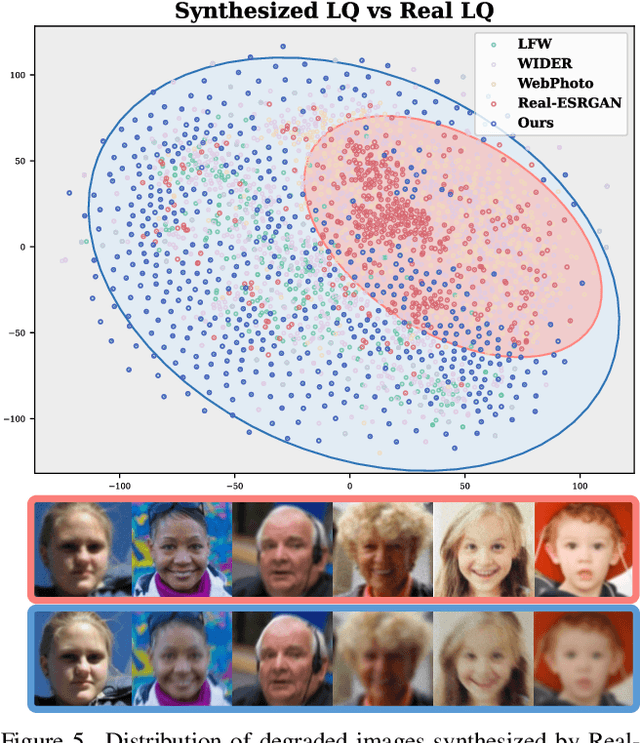
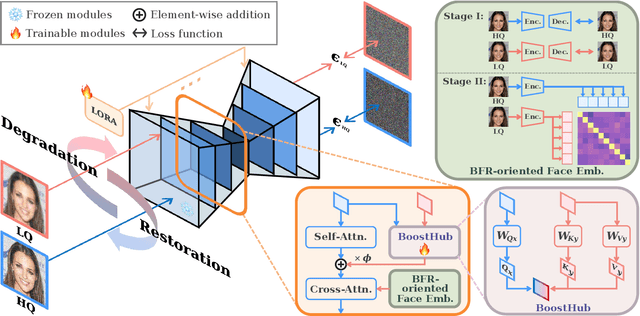
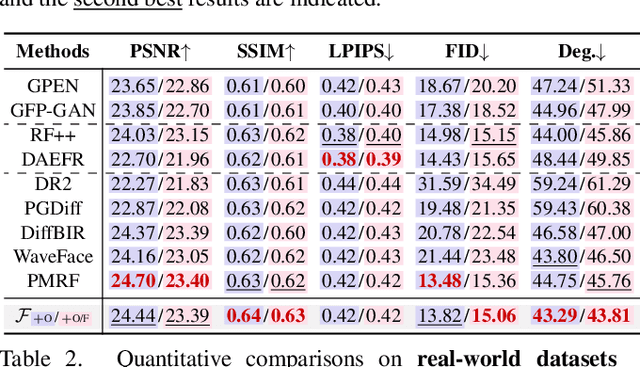
Although diffusion prior is rising as a powerful solution for blind face restoration (BFR), the inherent gap between the vanilla diffusion model and BFR settings hinders its seamless adaptation. The gap mainly stems from the discrepancy between 1) high-quality (HQ) and low-quality (LQ) images and 2) synthesized and real-world images. The vanilla diffusion model is trained on images with no or less degradations, whereas BFR handles moderately to severely degraded images. Additionally, LQ images used for training are synthesized by a naive degradation model with limited degradation patterns, which fails to simulate complex and unknown degradations in real-world scenarios. In this work, we use a unified network FLIPNET that switches between two modes to resolve specific gaps. In Restoration mode, the model gradually integrates BFR-oriented features and face embeddings from LQ images to achieve authentic and faithful face restoration. In Degradation mode, the model synthesizes real-world like degraded images based on the knowledge learned from real-world degradation datasets. Extensive evaluations on benchmark datasets show that our model 1) outperforms previous diffusion prior based BFR methods in terms of authenticity and fidelity, and 2) outperforms the naive degradation model in modeling the real-world degradations.
Wired Perspectives: Multi-View Wire Art Embraces Generative AI
Nov 26, 2023Creating multi-view wire art (MVWA), a static 3D sculpture with diverse interpretations from different viewpoints, is a complex task even for skilled artists. In response, we present DreamWire, an AI system enabling everyone to craft MVWA easily. Users express their vision through text prompts or scribbles, freeing them from intricate 3D wire organisation. Our approach synergises 3D B\'ezier curves, Prim's algorithm, and knowledge distillation from diffusion models or their variants (e.g., ControlNet). This blend enables the system to represent 3D wire art, ensuring spatial continuity and overcoming data scarcity. Extensive evaluation and analysis are conducted to shed insight on the inner workings of the proposed system, including the trade-off between connectivity and visual aesthetics.
SketchDreamer: Interactive Text-Augmented Creative Sketch Ideation
Aug 27, 2023Artificial Intelligence Generated Content (AIGC) has shown remarkable progress in generating realistic images. However, in this paper, we take a step "backward" and address AIGC for the most rudimentary visual modality of human sketches. Our objective is on the creative nature of sketches, and that creative sketching should take the form of an interactive process. We further enable text to drive the sketch ideation process, allowing creativity to be freely defined, while simultaneously tackling the challenge of "I can't sketch". We present a method to generate controlled sketches using a text-conditioned diffusion model trained on pixel representations of images. Our proposed approach, referred to as SketchDreamer, integrates a differentiable rasteriser of Bezier curves that optimises an initial input to distil abstract semantic knowledge from a pretrained diffusion model. We utilise Score Distillation Sampling to learn a sketch that aligns with a given caption, which importantly enable both text and sketch to interact with the ideation process. Our objective is to empower non-professional users to create sketches and, through a series of optimisation processes, transform a narrative into a storyboard by expanding the text prompt while making minor adjustments to the sketch input. Through this work, we hope to aspire the way we create visual content, democratise the creative process, and inspire further research in enhancing human creativity in AIGC. The code is available at \url{https://github.com/WinKawaks/SketchDreamer}.
SketchXAI: A First Look at Explainability for Human Sketches
Apr 23, 2023This paper, for the very first time, introduces human sketches to the landscape of XAI (Explainable Artificial Intelligence). We argue that sketch as a ``human-centred'' data form, represents a natural interface to study explainability. We focus on cultivating sketch-specific explainability designs. This starts by identifying strokes as a unique building block that offers a degree of flexibility in object construction and manipulation impossible in photos. Following this, we design a simple explainability-friendly sketch encoder that accommodates the intrinsic properties of strokes: shape, location, and order. We then move on to define the first ever XAI task for sketch, that of stroke location inversion SLI. Just as we have heat maps for photos, and correlation matrices for text, SLI offers an explainability angle to sketch in terms of asking a network how well it can recover stroke locations of an unseen sketch. We offer qualitative results for readers to interpret as snapshots of the SLI process in the paper, and as GIFs on the project page. A minor but interesting note is that thanks to its sketch-specific design, our sketch encoder also yields the best sketch recognition accuracy to date while having the smallest number of parameters. The code is available at \url{https://sketchxai.github.io}.
Large-Scale Product Retrieval with Weakly Supervised Representation Learning
Aug 01, 2022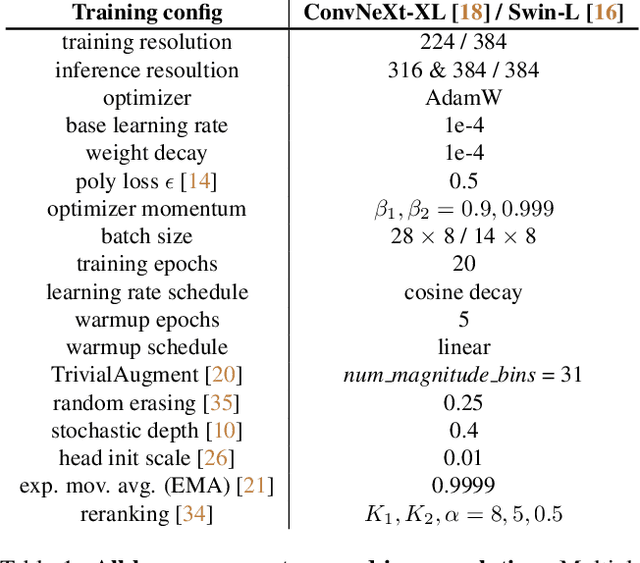
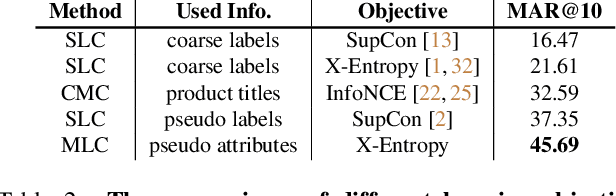
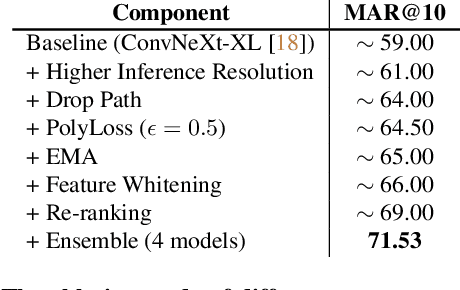
Large-scale weakly supervised product retrieval is a practically useful yet computationally challenging problem. This paper introduces a novel solution for the eBay Visual Search Challenge (eProduct) held at the Ninth Workshop on Fine-Grained Visual Categorisation workshop (FGVC9) of CVPR 2022. This competition presents two challenges: (a) E-commerce is a drastically fine-grained domain including many products with subtle visual differences; (b) A lacking of target instance-level labels for model training, with only coarse category labels and product titles available. To overcome these obstacles, we formulate a strong solution by a set of dedicated designs: (a) Instead of using text training data directly, we mine thousands of pseudo-attributes from product titles and use them as the ground truths for multi-label classification. (b) We incorporate several strong backbones with advanced training recipes for more discriminative representation learning. (c) We further introduce a number of post-processing techniques including whitening, re-ranking and model ensemble for retrieval enhancement. By achieving 71.53% MAR, our solution "Involution King" achieves the second position on the leaderboard.