 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRays as Pixels: Learning A Joint Distribution of Videos and Camera Trajectories
Apr 10, 2026Recovering camera parameters from images and rendering scenes from novel viewpoints have long been treated as separate tasks in computer vision and graphics. This separation breaks down when image coverage is sparse or poses are ambiguous, since each task needs what the other produces. We propose Rays as Pixels, a Video Diffusion Model (VDM) that learns a joint distribution over videos and camera trajectories. We represent each camera as dense ray pixels (raxels) and denoise them jointly with video frames through Decoupled Self-Cross Attention mechanism. A single trained model handles three tasks: predicting camera trajectories from video, jointly generating video and camera trajectory from input images, and generating video from input images along a target camera trajectory. Because the model can both predict trajectories from a video and generate views conditioned on its own predictions, we evaluate it through a closed-loop self-consistency test, demonstrating that its forward and inverse predictions agree. Notably, trajectory prediction requires far fewer denoising steps than video generation, even a few denoising steps suffice for self-consistency. We report results on pose estimation and camera-controlled video generation.
VecGlypher: Unified Vector Glyph Generation with Language Models
Feb 25, 2026Vector glyphs are the atomic units of digital typography, yet most learning-based pipelines still depend on carefully curated exemplar sheets and raster-to-vector postprocessing, which limits accessibility and editability. We introduce VecGlypher, a single multimodal language model that generates high-fidelity vector glyphs directly from text descriptions or image exemplars. Given a style prompt, optional reference glyph images, and a target character, VecGlypher autoregressively emits SVG path tokens, avoiding raster intermediates and producing editable, watertight outlines in one pass. A typography-aware data and training recipe makes this possible: (i) a large-scale continuation stage on 39K noisy Envato fonts to master SVG syntax and long-horizon geometry, followed by (ii) post-training on 2.5K expert-annotated Google Fonts with descriptive tags and exemplars to align language and imagery with geometry; preprocessing normalizes coordinate frames, canonicalizes paths, de-duplicates families, and quantizes coordinates for stable long-sequence decoding. On cross-family OOD evaluation, VecGlypher substantially outperforms both general-purpose LLMs and specialized vector-font baselines for text-only generation, while image-referenced generation reaches a state-of-the-art performance, with marked gains over DeepVecFont-v2 and DualVector. Ablations show that model scale and the two-stage recipe are critical and that absolute-coordinate serialization yields the best geometry. VecGlypher lowers the barrier to font creation by letting users design with words or exemplars, and provides a scalable foundation for future multimodal design tools.
Chirpy3D: Continuous Part Latents for Creative 3D Bird Generation
Jan 07, 2025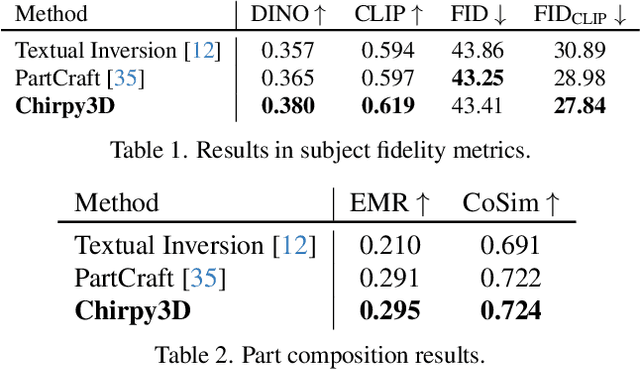
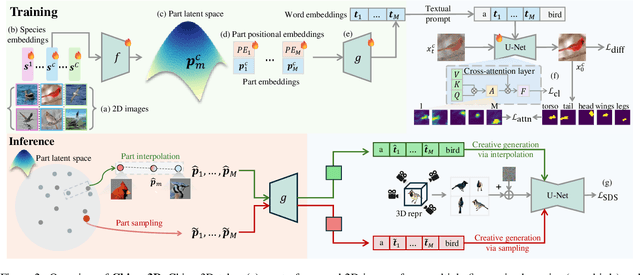
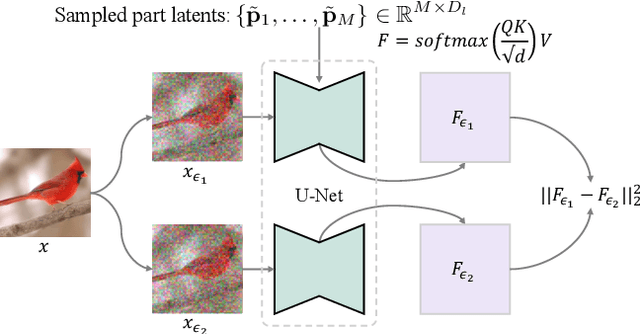
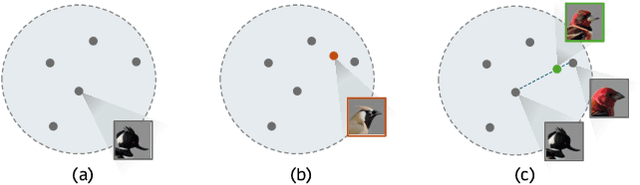
In this paper, we push the boundaries of fine-grained 3D generation into truly creative territory. Current methods either lack intricate details or simply mimic existing objects -- we enable both. By lifting 2D fine-grained understanding into 3D through multi-view diffusion and modeling part latents as continuous distributions, we unlock the ability to generate entirely new, yet plausible parts through interpolation and sampling. A self-supervised feature consistency loss further ensures stable generation of these unseen parts. The result is the first system capable of creating novel 3D objects with species-specific details that transcend existing examples. While we demonstrate our approach on birds, the underlying framework extends beyond things that can chirp! Code will be released at https://github.com/kamwoh/chirpy3d.
Learning Flow Fields in Attention for Controllable Person Image Generation
Dec 12, 2024
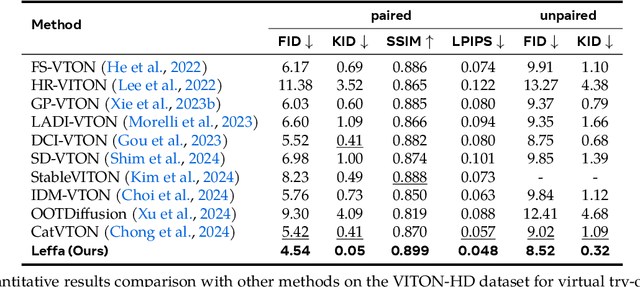
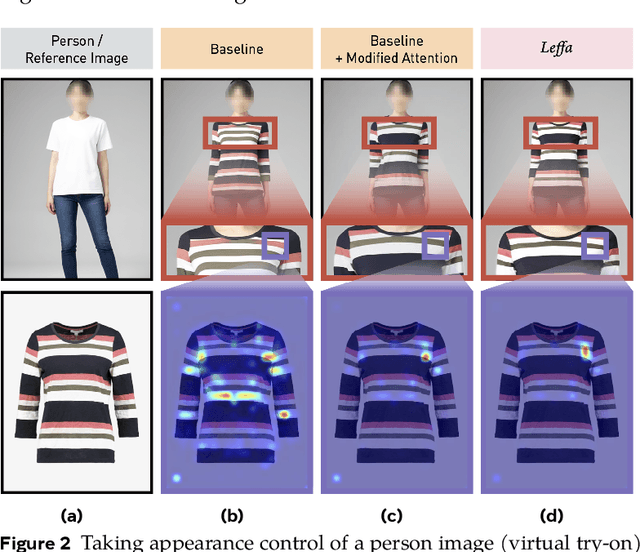
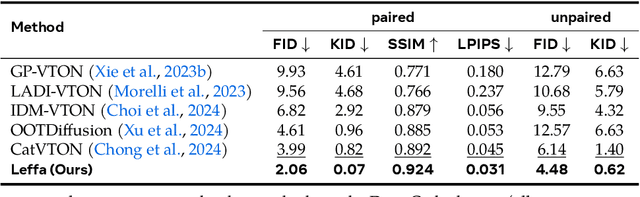
Controllable person image generation aims to generate a person image conditioned on reference images, allowing precise control over the person's appearance or pose. However, prior methods often distort fine-grained textural details from the reference image, despite achieving high overall image quality. We attribute these distortions to inadequate attention to corresponding regions in the reference image. To address this, we thereby propose learning flow fields in attention (Leffa), which explicitly guides the target query to attend to the correct reference key in the attention layer during training. Specifically, it is realized via a regularization loss on top of the attention map within a diffusion-based baseline. Our extensive experiments show that Leffa achieves state-of-the-art performance in controlling appearance (virtual try-on) and pose (pose transfer), significantly reducing fine-grained detail distortion while maintaining high image quality. Additionally, we show that our loss is model-agnostic and can be used to improve the performance of other diffusion models.
PartCraft: Crafting Creative Objects by Parts
Jul 05, 2024



This paper propels creative control in generative visual AI by allowing users to "select". Departing from traditional text or sketch-based methods, we for the first time allow users to choose visual concepts by parts for their creative endeavors. The outcome is fine-grained generation that precisely captures selected visual concepts, ensuring a holistically faithful and plausible result. To achieve this, we first parse objects into parts through unsupervised feature clustering. Then, we encode parts into text tokens and introduce an entropy-based normalized attention loss that operates on them. This loss design enables our model to learn generic prior topology knowledge about object's part composition, and further generalize to novel part compositions to ensure the generation looks holistically faithful. Lastly, we employ a bottleneck encoder to project the part tokens. This not only enhances fidelity but also accelerates learning, by leveraging shared knowledge and facilitating information exchange among instances. Visual results in the paper and supplementary material showcase the compelling power of PartCraft in crafting highly customized, innovative creations, exemplified by the "charming" and creative birds. Code is released at https://github.com/kamwoh/partcraft.
ConceptHash: Interpretable Fine-Grained Hashing via Concept Discovery
Jun 12, 2024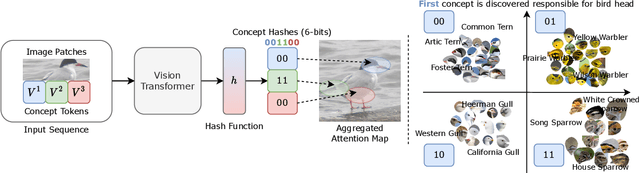
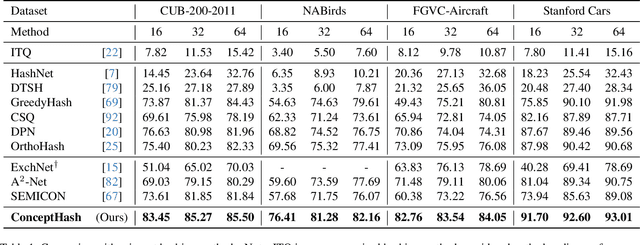
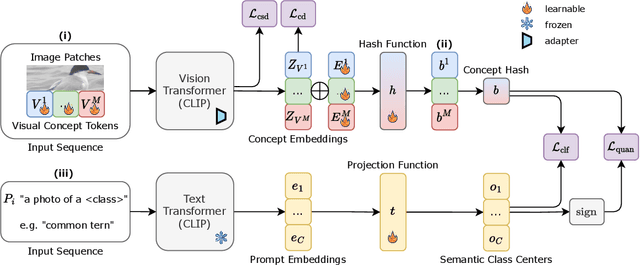

Existing fine-grained hashing methods typically lack code interpretability as they compute hash code bits holistically using both global and local features. To address this limitation, we propose ConceptHash, a novel method that achieves sub-code level interpretability. In ConceptHash, each sub-code corresponds to a human-understandable concept, such as an object part, and these concepts are automatically discovered without human annotations. Specifically, we leverage a Vision Transformer architecture and introduce concept tokens as visual prompts, along with image patch tokens as model inputs. Each concept is then mapped to a specific sub-code at the model output, providing natural sub-code interpretability. To capture subtle visual differences among highly similar sub-categories (e.g., bird species), we incorporate language guidance to ensure that the learned hash codes are distinguishable within fine-grained object classes while maintaining semantic alignment. This approach allows us to develop hash codes that exhibit similarity within families of species while remaining distinct from species in other families. Extensive experiments on four fine-grained image retrieval benchmarks demonstrate that ConceptHash outperforms previous methods by a significant margin, offering unique sub-code interpretability as an additional benefit. Code at: https://github.com/kamwoh/concepthash.
IPR-NeRF: Ownership Verification meets Neural Radiance Field
Jan 23, 2024Neural Radiance Field (NeRF) models have gained significant attention in the computer vision community in the recent past with state-of-the-art visual quality and produced impressive demonstrations. Since then, technopreneurs have sought to leverage NeRF models into a profitable business. Therefore, NeRF models make it worth the risk of plagiarizers illegally copying, re-distributing, or misusing those models. This paper proposes a comprehensive intellectual property (IP) protection framework for the NeRF model in both black-box and white-box settings, namely IPR-NeRF. In the black-box setting, a diffusion-based solution is introduced to embed and extract the watermark via a two-stage optimization process. In the white-box setting, a designated digital signature is embedded into the weights of the NeRF model by adopting the sign loss objective. Our extensive experiments demonstrate that not only does our approach maintain the fidelity (\ie, the rendering quality) of IPR-NeRF models, but it is also robust against both ambiguity and removal attacks compared to prior arts.
DreamCreature: Crafting Photorealistic Virtual Creatures from Imagination
Nov 27, 2023Recent text-to-image (T2I) generative models allow for high-quality synthesis following either text instructions or visual examples. Despite their capabilities, these models face limitations in creating new, detailed creatures within specific categories (e.g., virtual dog or bird species), which are valuable in digital asset creation and biodiversity analysis. To bridge this gap, we introduce a novel task, Virtual Creatures Generation: Given a set of unlabeled images of the target concepts (e.g., 200 bird species), we aim to train a T2I model capable of creating new, hybrid concepts within diverse backgrounds and contexts. We propose a new method called DreamCreature, which identifies and extracts the underlying sub-concepts (e.g., body parts of a specific species) in an unsupervised manner. The T2I thus adapts to generate novel concepts (e.g., new bird species) with faithful structures and photorealistic appearance by seamlessly and flexibly composing learned sub-concepts. To enhance sub-concept fidelity and disentanglement, we extend the textual inversion technique by incorporating an additional projector and tailored attention loss regularization. Extensive experiments on two fine-grained image benchmarks demonstrate the superiority of DreamCreature over prior methods in both qualitative and quantitative evaluation. Ultimately, the learned sub-concepts facilitate diverse creative applications, including innovative consumer product designs and nuanced property modifications.
Unsupervised Hashing via Similarity Distribution Calibration
Feb 15, 2023Existing unsupervised hashing methods typically adopt a feature similarity preservation paradigm. As a result, they overlook the intrinsic similarity capacity discrepancy between the continuous feature and discrete hash code spaces. Specifically, since the feature similarity distribution is intrinsically biased (e.g., moderately positive similarity scores on negative pairs), the hash code similarities of positive and negative pairs often become inseparable (i.e., the similarity collapse problem). To solve this problem, in this paper a novel Similarity Distribution Calibration (SDC) method is introduced. Instead of matching individual pairwise similarity scores, SDC aligns the hash code similarity distribution towards a calibration distribution (e.g., beta distribution) with sufficient spread across the entire similarity capacity/range, to alleviate the similarity collapse problem. Extensive experiments show that our SDC outperforms the state-of-the-art alternatives on both coarse category-level and instance-level image retrieval tasks, often by a large margin. Code is available at https://github.com/kamwoh/sdc.
Large-Scale Product Retrieval with Weakly Supervised Representation Learning
Aug 01, 2022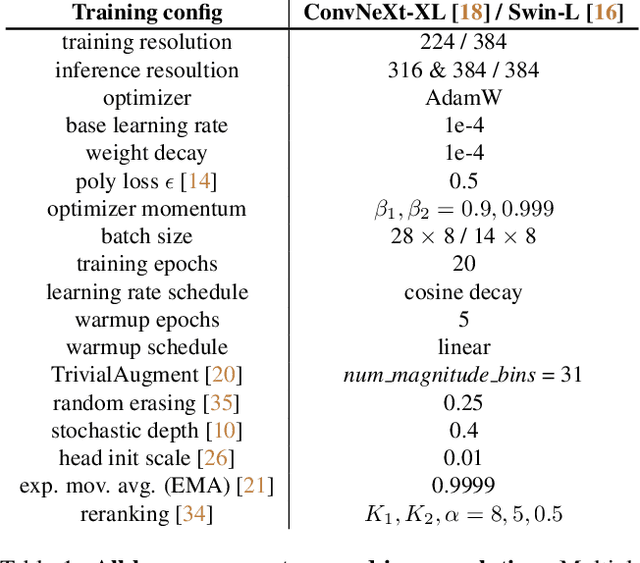
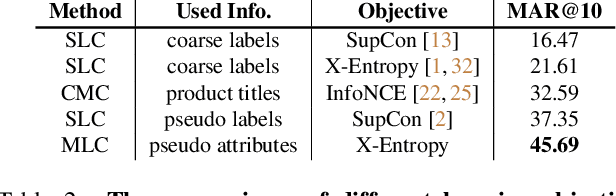
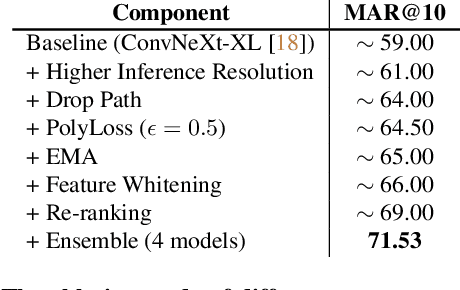
Large-scale weakly supervised product retrieval is a practically useful yet computationally challenging problem. This paper introduces a novel solution for the eBay Visual Search Challenge (eProduct) held at the Ninth Workshop on Fine-Grained Visual Categorisation workshop (FGVC9) of CVPR 2022. This competition presents two challenges: (a) E-commerce is a drastically fine-grained domain including many products with subtle visual differences; (b) A lacking of target instance-level labels for model training, with only coarse category labels and product titles available. To overcome these obstacles, we formulate a strong solution by a set of dedicated designs: (a) Instead of using text training data directly, we mine thousands of pseudo-attributes from product titles and use them as the ground truths for multi-label classification. (b) We incorporate several strong backbones with advanced training recipes for more discriminative representation learning. (c) We further introduce a number of post-processing techniques including whitening, re-ranking and model ensemble for retrieval enhancement. By achieving 71.53% MAR, our solution "Involution King" achieves the second position on the leaderboard.