 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavFlow: Audio Generation in Waveform Space
May 18, 2026Modern audio generation predominantly relies on latent-space compression, introducing additional complexity and potential information loss. In this work, we challenge this paradigm with WavFlow, a framework that generates high-fidelity audio directly in raw waveform space without intermediate representations. To overcome the inherent difficulties of modeling high-dimensional and low-energy signals, we reshape audio into 2D token grids through waveform patchify and introduce amplitude lifting to align signal scales, enabling stable optimization via direct x-prediction in flow matching. To capture complex semantic alignment and temporal synchronization, we leverage an automated data pipeline to curate 5 million high-quality video-text-audio triplets, allowing the model to learn fine-grained acoustic patterns from scratch. Experimental results show that WavFlow achieves competitive performance on the video-to-audio benchmark VGGSound (FD_PaSST: 59.98, IS_PANNs: 17.40, DeSync: 0.44) and the text-to-audio benchmark AudioCaps (FD_PANNs: 10.63, IS_PANNs: 12.62), matching or exceeding the performance of established latent-based methods. Our work demonstrates that intermediate compression is not a prerequisite for high-quality synthesis, offering a simpler and more scalable alternative for multimodal audio generation.
Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
Apr 27, 2026Unified multimodal models typically rely on pretrained vision encoders and use separate visual representations for understanding and generation, creating misalignment between the two tasks and preventing fully end-to-end optimization from raw pixels. We introduce Tuna-2, a native unified multimodal model that performs visual understanding and generation directly based on pixel embeddings. Tuna-2 drastically simplifies the model architecture by employing simple patch embedding layers to encode visual input, completely discarding the modular vision encoder designs such as the VAE or the representation encoder. Experiments show that Tuna-2 achieves state-of-the-art performance in multimodal benchmarks, demonstrating that unified pixel-space modelling can fully compete with latent-space approaches for high-quality image generation. Moreover, while the encoder-based variant converges faster in early pretraining, Tuna-2's encoder-free design achieves stronger multimodal understanding at scale, particularly on tasks requiring fine-grained visual perception. These results show that pretrained vision encoders are not necessary for multimodal modelling, and end-to-end pixel-space learning offers a scalable path toward stronger visual representations for both generation and perception.
HiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming
Dec 24, 2025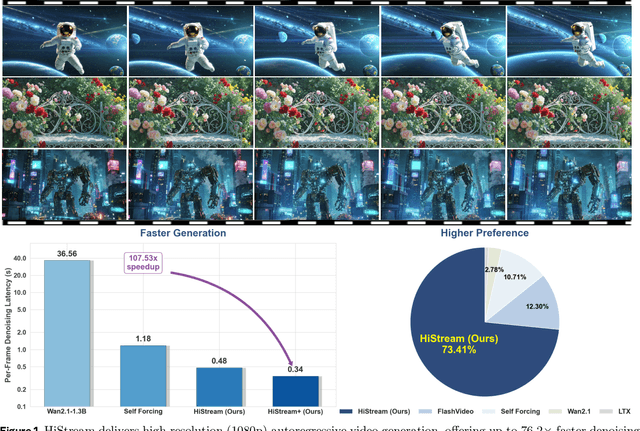
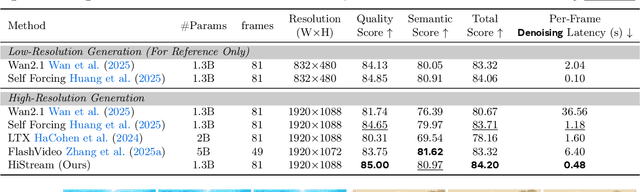
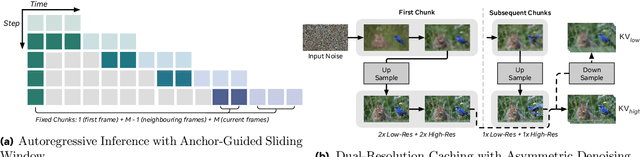
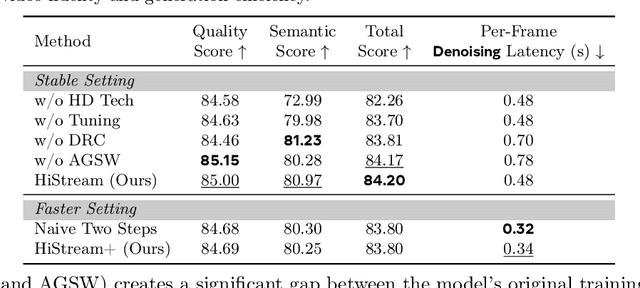
High-resolution video generation, while crucial for digital media and film, is computationally bottlenecked by the quadratic complexity of diffusion models, making practical inference infeasible. To address this, we introduce HiStream, an efficient autoregressive framework that systematically reduces redundancy across three axes: i) Spatial Compression: denoising at low resolution before refining at high resolution with cached features; ii) Temporal Compression: a chunk-by-chunk strategy with a fixed-size anchor cache, ensuring stable inference speed; and iii) Timestep Compression: applying fewer denoising steps to subsequent, cache-conditioned chunks. On 1080p benchmarks, our primary HiStream model (i+ii) achieves state-of-the-art visual quality while demonstrating up to 76.2x faster denoising compared to the Wan2.1 baseline and negligible quality loss. Our faster variant, HiStream+, applies all three optimizations (i+ii+iii), achieving a 107.5x acceleration over the baseline, offering a compelling trade-off between speed and quality, thereby making high-resolution video generation both practical and scalable.
Mixture of States: Routing Token-Level Dynamics for Multimodal Generation
Nov 15, 2025We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions. The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states, precisely aligning token-level features with the diffusion trajectory. This router sparsely selects the top-$k$ hidden states and is trained with an $ε$-greedy strategy, efficiently selecting contextual features with minimal learnable parameters and negligible computational overhead. We validate our design with text-to-image generation (MoS-Image) and editing (MoS-Editing), which achieve state-of-the-art results. With only 3B to 5B parameters, our models match or surpass counterparts up to $4\times$ larger. These findings establish MoS as a flexible and compute-efficient paradigm for scaling multimodal diffusion models.
Learning Flow Fields in Attention for Controllable Person Image Generation
Dec 12, 2024
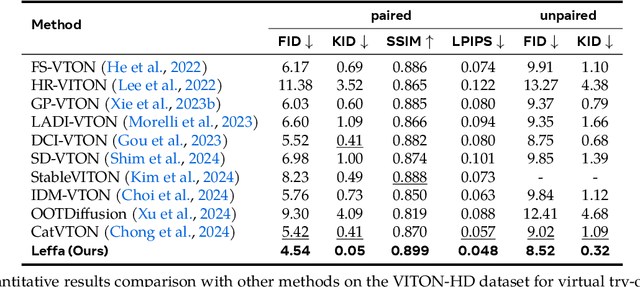
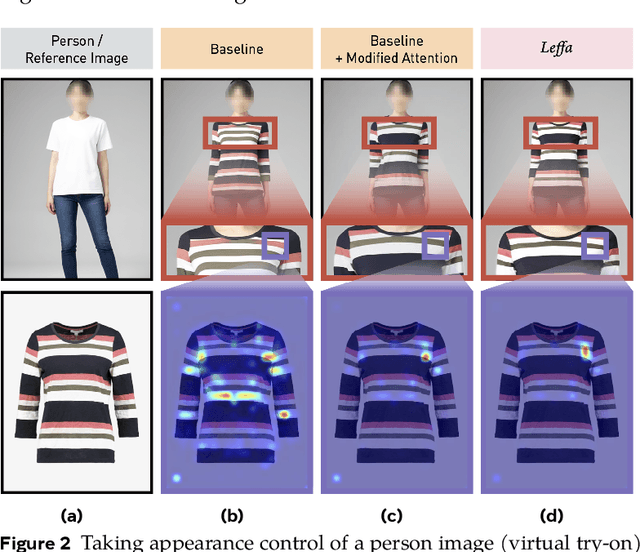
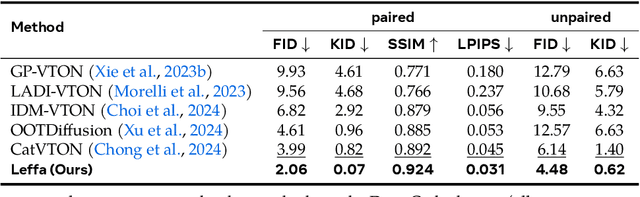
Controllable person image generation aims to generate a person image conditioned on reference images, allowing precise control over the person's appearance or pose. However, prior methods often distort fine-grained textural details from the reference image, despite achieving high overall image quality. We attribute these distortions to inadequate attention to corresponding regions in the reference image. To address this, we thereby propose learning flow fields in attention (Leffa), which explicitly guides the target query to attend to the correct reference key in the attention layer during training. Specifically, it is realized via a regularization loss on top of the attention map within a diffusion-based baseline. Our extensive experiments show that Leffa achieves state-of-the-art performance in controlling appearance (virtual try-on) and pose (pose transfer), significantly reducing fine-grained detail distortion while maintaining high image quality. Additionally, we show that our loss is model-agnostic and can be used to improve the performance of other diffusion models.
WorldAfford: Affordance Grounding based on Natural Language Instructions
May 21, 2024



Affordance grounding aims to localize the interaction regions for the manipulated objects in the scene image according to given instructions. A critical challenge in affordance grounding is that the embodied agent should understand human instructions and analyze which tools in the environment can be used, as well as how to use these tools to accomplish the instructions. Most recent works primarily supports simple action labels as input instructions for localizing affordance regions, failing to capture complex human objectives. Moreover, these approaches typically identify affordance regions of only a single object in object-centric images, ignoring the object context and struggling to localize affordance regions of multiple objects in complex scenes for practical applications. To address this concern, for the first time, we introduce a new task of affordance grounding based on natural language instructions, extending it from previously using simple labels for complex human instructions. For this new task, we propose a new framework, WorldAfford. We design a novel Affordance Reasoning Chain-of-Thought Prompting to reason about affordance knowledge from LLMs more precisely and logically. Subsequently, we use SAM and CLIP to localize the objects related to the affordance knowledge in the image. We identify the affordance regions of the objects through an affordance region localization module. To benchmark this new task and validate our framework, an affordance grounding dataset, LLMaFF, is constructed. We conduct extensive experiments to verify that WorldAfford performs state-of-the-art on both the previous AGD20K and the new LLMaFF dataset. In particular, WorldAfford can localize the affordance regions of multiple objects and provide an alternative when objects in the environment cannot fully match the given instruction.
Segment Any Object Model : Real-to-Simulation Fine-Tuning Strategy for Multi-Class Multi-Instance Segmentation
Mar 16, 2024



Multi-class multi-instance segmentation is the task of identifying masks for multiple object classes and multiple instances of the same class within an image. The foundational Segment Anything Model (SAM) is designed for promptable multi-class multi-instance segmentation but tends to output part or sub-part masks in the "everything" mode for various real-world applications. Whole object segmentation masks play a crucial role for indoor scene understanding, especially in robotics applications. We propose a new domain invariant Real-to-Simulation (Real-Sim) fine-tuning strategy for SAM. We use object images and ground truth data collected from Ai2Thor simulator during fine-tuning (real-to-sim). To allow our Segment Any Object Model (SAOM) to work in the "everything" mode, we propose the novel nearest neighbour assignment method, updating point embeddings for each ground-truth mask. SAOM is evaluated on our own dataset collected from Ai2Thor simulator. SAOM significantly improves on SAM, with a 28% increase in mIoU and a 25% increase in mAcc for 54 frequently-seen indoor object classes. Moreover, our Real-to-Simulation fine-tuning strategy demonstrates promising generalization performance in real environments without being trained on the real-world data (sim-to-real). The dataset and the code will be released after publication.
GenTron: Delving Deep into Diffusion Transformers for Image and Video Generation
Dec 07, 2023



In this study, we explore Transformer-based diffusion models for image and video generation. Despite the dominance of Transformer architectures in various fields due to their flexibility and scalability, the visual generative domain primarily utilizes CNN-based U-Net architectures, particularly in diffusion-based models. We introduce GenTron, a family of Generative models employing Transformer-based diffusion, to address this gap. Our initial step was to adapt Diffusion Transformers (DiTs) from class to text conditioning, a process involving thorough empirical exploration of the conditioning mechanism. We then scale GenTron from approximately 900M to over 3B parameters, observing significant improvements in visual quality. Furthermore, we extend GenTron to text-to-video generation, incorporating novel motion-free guidance to enhance video quality. In human evaluations against SDXL, GenTron achieves a 51.1% win rate in visual quality (with a 19.8% draw rate), and a 42.3% win rate in text alignment (with a 42.9% draw rate). GenTron also excels in the T2I-CompBench, underscoring its strengths in compositional generation. We believe this work will provide meaningful insights and serve as a valuable reference for future research.
FLATTEN: optical FLow-guided ATTENtion for consistent text-to-video editing
Oct 09, 2023

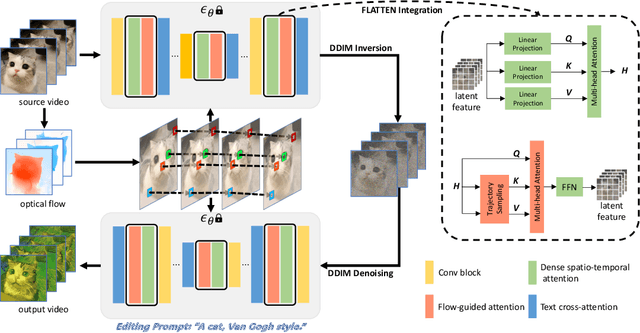

Text-to-video editing aims to edit the visual appearance of a source video conditional on textual prompts. A major challenge in this task is to ensure that all frames in the edited video are visually consistent. Most recent works apply advanced text-to-image diffusion models to this task by inflating 2D spatial attention in the U-Net into spatio-temporal attention. Although temporal context can be added through spatio-temporal attention, it may introduce some irrelevant information for each patch and therefore cause inconsistency in the edited video. In this paper, for the first time, we introduce optical flow into the attention module in the diffusion model's U-Net to address the inconsistency issue for text-to-video editing. Our method, FLATTEN, enforces the patches on the same flow path across different frames to attend to each other in the attention module, thus improving the visual consistency in the edited videos. Additionally, our method is training-free and can be seamlessly integrated into any diffusion-based text-to-video editing methods and improve their visual consistency. Experiment results on existing text-to-video editing benchmarks show that our proposed method achieves the new state-of-the-art performance. In particular, our method excels in maintaining the visual consistency in the edited videos.
Learning Similarity between Scene Graphs and Images with Transformers
Apr 02, 2023
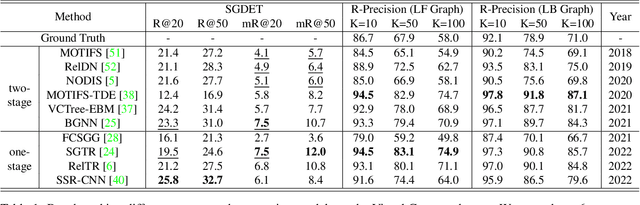
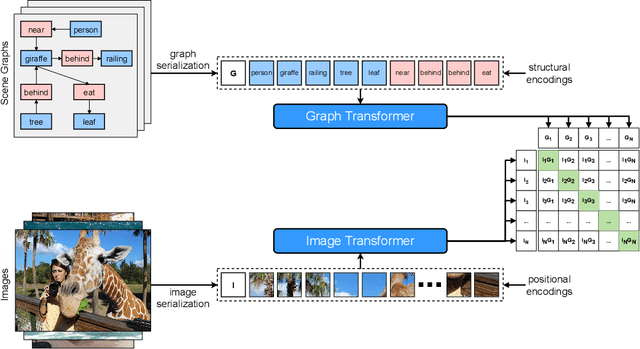

Scene graph generation is conventionally evaluated by (mean) Recall@K, which measures the ratio of correctly predicted triplets that appear in the ground truth. However, such triplet-oriented metrics cannot capture the global semantic information of scene graphs, and measure the similarity between images and generated scene graphs. The usability of scene graphs is therefore limited in downstream tasks. To address this issue, a framework that can measure the similarity of scene graphs and images is urgently required. Motivated by the successful application of Contrastive Language-Image Pre-training (CLIP), we propose a novel contrastive learning framework consisting of a graph Transformer and an image Transformer to align scene graphs and their corresponding images in the shared latent space. To enable the graph Transformer to comprehend the scene graph structure and extract representative features, we introduce a graph serialization technique that transforms a scene graph into a sequence with structural encoding. Based on our framework, we introduce R-Precision measuring image retrieval accuracy as a new evaluation metric for scene graph generation and establish new benchmarks for the Visual Genome and Open Images datasets. A series of experiments are further conducted to demonstrate the effectiveness of the graph Transformer, which shows great potential as a scene graph encoder.