 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelTR: Relation Transformer for Scene Graph Generation
Paper and Code

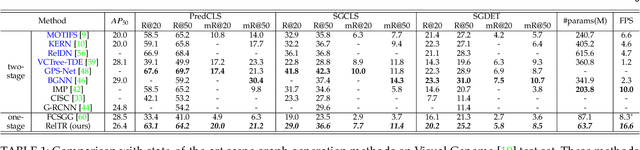
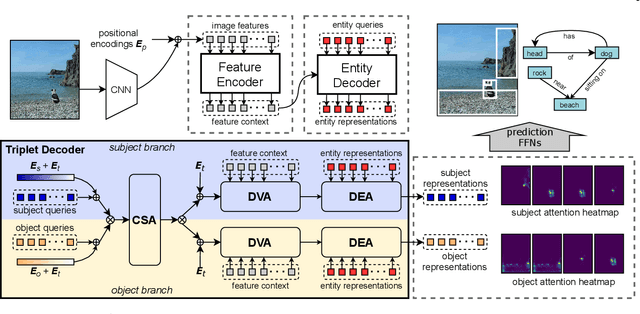
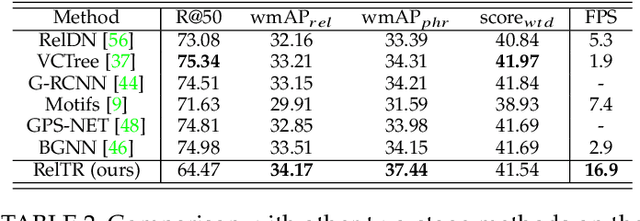
Different objects in the same scene are more or less related to each other, but only a limited number of these relationships are noteworthy. Inspired by DETR, which excels in object detection, we view scene graph generation as a set prediction problem and propose an end-to-end scene graph generation model RelTR which has an encoder-decoder architecture. The encoder reasons about the visual feature context while the decoder infers a fixed-size set of triplets subject-predicate-object using different types of attention mechanisms with coupled subject and object queries. We design a set prediction loss performing the matching between the ground truth and predicted triplets for the end-to-end training. In contrast to most existing scene graph generation methods, RelTR is a one-stage method that predicts a set of relationships directly only using visual appearance without combining entities and labeling all possible predicates. Extensive experiments on the Visual Genome and Open Images V6 datasets demonstrate the superior performance and fast inference of our model.