 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHLA: Hadamard Linear Attention
Feb 12, 2026The attention mechanism is an important reason for the success of transformers. It relies on computing pairwise relations between tokens. To reduce the high computational cost of standard quadratic attention, linear attention has been proposed as an efficient approximation. It employs kernel functions that are applied independently to the inputs before the pairwise similarities are calculated. That allows for an efficient computational procedure which, however, amounts to a low-degree rational function approximating softmax. We propose Hadamard Linear Attention (HLA). Unlike previous works on linear attention, the nonlinearity in HLA is not applied separately to queries and keys, but, analogously to standard softmax attention, after the pairwise similarities have been computed. It will be shown that the proposed nonlinearity amounts to a higher-degree rational function to approximate softmax. An efficient computational scheme for the proposed method is derived that is similar to that of standard linear attention. In contrast to other approaches, no time-consuming tensor reshaping is necessary to apply the proposed algorithm. The effectiveness of the approach is demonstrated by applying it to a large diffusion transformer model for video generation, an application that involves very large amounts of tokens.
Planar Gaussian Splatting
Dec 02, 2024



This paper presents Planar Gaussian Splatting (PGS), a novel neural rendering approach to learn the 3D geometry and parse the 3D planes of a scene, directly from multiple RGB images. The PGS leverages Gaussian primitives to model the scene and employ a hierarchical Gaussian mixture approach to group them. Similar Gaussians are progressively merged probabilistically in the tree-structured Gaussian mixtures to identify distinct 3D plane instances and form the overall 3D scene geometry. In order to enable the grouping, the Gaussian primitives contain additional parameters, such as plane descriptors derived by lifting 2D masks from a general 2D segmentation model and surface normals. Experiments show that the proposed PGS achieves state-of-the-art performance in 3D planar reconstruction without requiring either 3D plane labels or depth supervision. In contrast to existing supervised methods that have limited generalizability and struggle under domain shift, PGS maintains its performance across datasets thanks to its neural rendering and scene-specific optimization mechanism, while also being significantly faster than existing optimization-based approaches.
Deconfounded Imitation Learning
Nov 04, 2022Standard imitation learning can fail when the expert demonstrators have different sensory inputs than the imitating agent. This is because partial observability gives rise to hidden confounders in the causal graph. We break down the space of confounded imitation learning problems and identify three settings with different data requirements in which the correct imitation policy can be identified. We then introduce an algorithm for deconfounded imitation learning, which trains an inference model jointly with a latent-conditional policy. At test time, the agent alternates between updating its belief over the latent and acting under the belief. We show in theory and practice that this algorithm converges to the correct interventional policy, solves the confounding issue, and can under certain assumptions achieve an asymptotically optimal imitation performance.
Spatial-Temporal Transformer for Dynamic Scene Graph Generation
Aug 08, 2021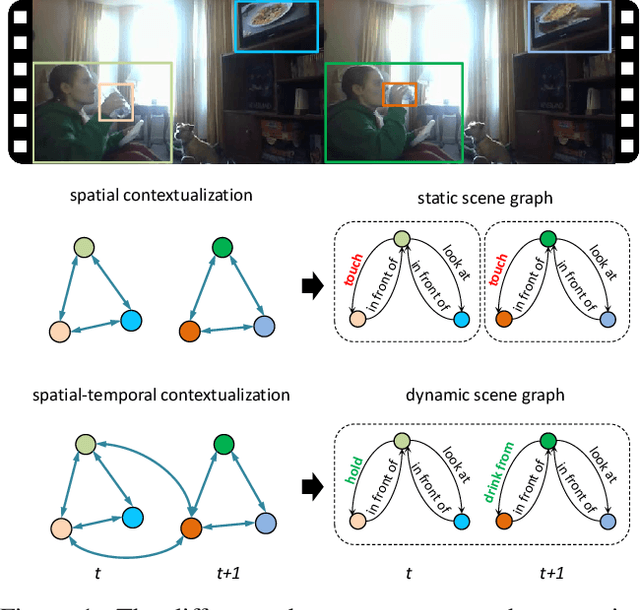

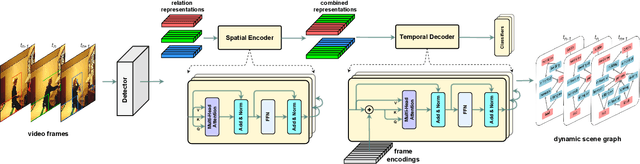
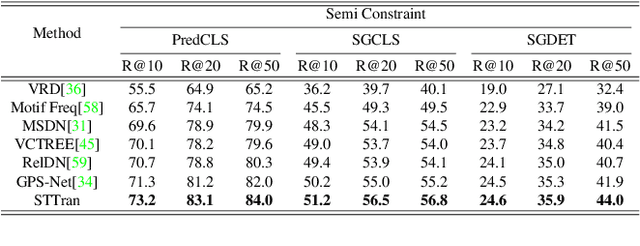
Dynamic scene graph generation aims at generating a scene graph of the given video. Compared to the task of scene graph generation from images, it is more challenging because of the dynamic relationships between objects and the temporal dependencies between frames allowing for a richer semantic interpretation. In this paper, we propose Spatial-temporal Transformer (STTran), a neural network that consists of two core modules: (1) a spatial encoder that takes an input frame to extract spatial context and reason about the visual relationships within a frame, and (2) a temporal decoder which takes the output of the spatial encoder as input in order to capture the temporal dependencies between frames and infer the dynamic relationships. Furthermore, STTran is flexible to take varying lengths of videos as input without clipping, which is especially important for long videos. Our method is validated on the benchmark dataset Action Genome (AG). The experimental results demonstrate the superior performance of our method in terms of dynamic scene graphs. Moreover, a set of ablative studies is conducted and the effect of each proposed module is justified. Code available at: https://github.com/yrcong/STTran.
Cuboids Revisited: Learning Robust 3D Shape Fitting to Single RGB Images
May 05, 2021
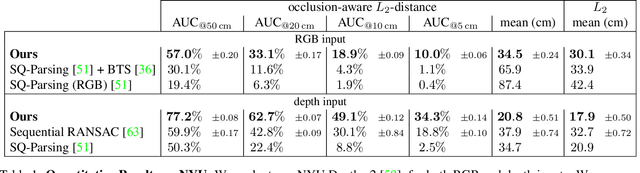

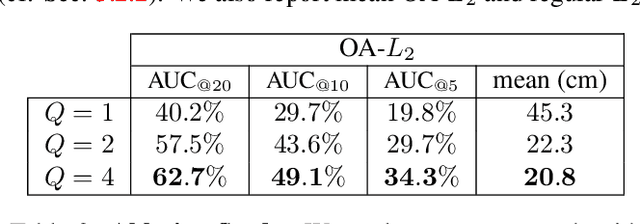
Humans perceive and construct the surrounding world as an arrangement of simple parametric models. In particular, man-made environments commonly consist of volumetric primitives such as cuboids or cylinders. Inferring these primitives is an important step to attain high-level, abstract scene descriptions. Previous approaches directly estimate shape parameters from a 2D or 3D input, and are only able to reproduce simple objects, yet unable to accurately parse more complex 3D scenes. In contrast, we propose a robust estimator for primitive fitting, which can meaningfully abstract real-world environments using cuboids. A RANSAC estimator guided by a neural network fits these primitives to 3D features, such as a depth map. We condition the network on previously detected parts of the scene, thus parsing it one-by-one. To obtain 3D features from a single RGB image, we additionally optimise a feature extraction CNN in an end-to-end manner. However, naively minimising point-to-primitive distances leads to large or spurious cuboids occluding parts of the scene behind. We thus propose an occlusion-aware distance metric correctly handling opaque scenes. The proposed algorithm does not require labour-intensive labels, such as cuboid annotations, for training. Results on the challenging NYU Depth v2 dataset demonstrate that the proposed algorithm successfully abstracts cluttered real-world 3D scene layouts.
NODIS: Neural Ordinary Differential Scene Understanding
Jan 14, 2020



Semantic image understanding is a challenging topic in computer vision. It requires to detect all objects in an image, but also to identify all the relations between them. Detected objects, their labels and the discovered relations can be used to construct a scene graph which provides an abstract semantic interpretation of an image. In previous works, relations were identified by solving an assignment problem formulated as Mixed-Integer Linear Programs. In this work, we interpret that formulation as Ordinary Differential Equation (ODE). The proposed architecture performs scene graph inference by solving a neural variant of an ODE by end-to-end learning. It achieves state-of-the-art results on all three benchmark tasks: scene graph generation (SGGen), classification (SGCls) and visual relationship detection (PredCls) on Visual Genome benchmark.
CONSAC: Robust Multi-Model Fitting by Conditional Sample Consensus
Jan 08, 2020
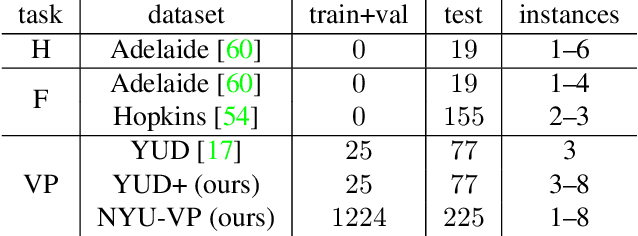
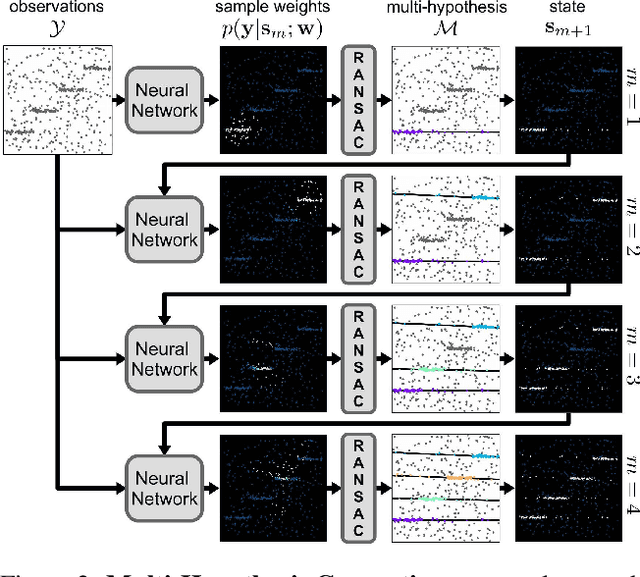
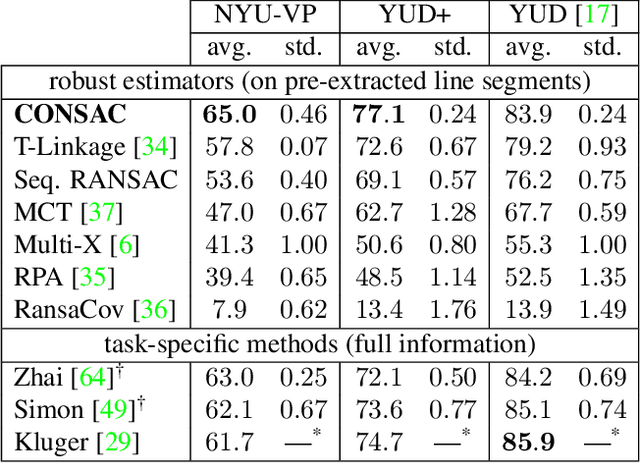
We present a robust estimator for fitting multiple parametric models of the same form to noisy measurements. Applications include finding multiple vanishing points in man-made scenes, fitting planes to architectural imagery, or estimating multiple rigid motions within the same sequence. In contrast to previous works, which resorted to hand-crafted search strategies for multiple model detection, we learn the search strategy from data. A neural network conditioned on previously detected models guides a RANSAC estimator to different subsets of all measurements, thereby finding model instances one after another. We train our method supervised as well as self-supervised. For supervised training of the search strategy, we contribute a new dataset for vanishing point estimation. Leveraging this dataset, the proposed algorithm is superior with respect to other robust estimators as well as to designated vanishing point estimation algorithms. For self-supervised learning of the search, we evaluate the proposed algorithm on multi-homography estimation and demonstrate an accuracy that is superior to state-of-the-art methods.
Learning Disentangled Representations via Independent Subspaces
Aug 26, 2019



Image generating neural networks are mostly viewed as black boxes, where any change in the input can have a number of globally effective changes on the output. In this work, we propose a method for learning disentangled representations to allow for localized image manipulations. We use face images as our example of choice. Depending on the image region, identity and other facial attributes can be modified. The proposed network can transfer parts of a face such as shape and color of eyes, hair, mouth, etc.~directly between persons while all other parts of the face remain unchanged. The network allows to generate modified images which appear like realistic images. Our model learns disentangled representations by weak supervision. We propose a localized resnet autoencoder optimized using several loss functions including a loss based on the semantic segmentation, which we interpret as masks, and a loss which enforces disentanglement by decomposition of the latent space into statistically independent subspaces. We evaluate the proposed solution w.r.t. disentanglement and generated image quality. Convincing results are demonstrated using the CelebA dataset.
Temporally Consistent Horizon Lines
Jul 23, 2019

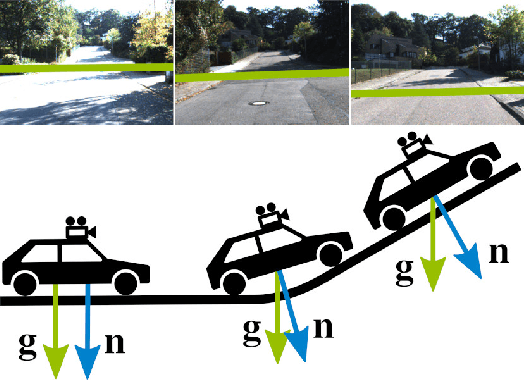

The horizon line is an important geometric feature for many image processing and scene understanding tasks in computer vision. For instance, in navigation of autonomous vehicles or driver assistance, it can be used to improve 3D reconstruction as well as for semantic interpretation of dynamic environments. While both algorithms and datasets exist for single images, the problem of horizon line estimation from video sequences has not gained attention. In this paper, we show how convolutional neural networks are able to utilise the temporal consistency imposed by video sequences in order to increase the accuracy and reduce the variance of horizon line estimates. A novel CNN architecture with an improved residual convolutional LSTM is presented for temporally consistent horizon line estimation. We propose an adaptive loss function that ensures stable training as well as accurate results. Furthermore, we introduce an extension of the KITTI dataset which contains precise horizon line labels for 43699 images across 72 video sequences. A comprehensive evaluation shows that the proposed approach consistently achieves superior performance compared with existing methods.
Non-Rigid Structure-From-Motion by Rank-One Basis Shapes
Apr 30, 2019



In this paper, we show that the affine, non-rigid structure-from-motion problem can be solved by rank-one, thus degenerate, basis shapes. It is a natural reformulation of the classic low-rank method by Bregler et al., where it was assumed that the deformable 3D structure is generated by a linear combination of rigid basis shapes. The non-rigid shape will be decomposed into the mean shape and the degenerate shapes, constructed from the right singular vectors of the low-rank decomposition. The right singular vectors are affinely back-projected into the 3D space, and the affine back-projections will also be solved as part of the factorisation. By construction, a direct interpretation for the right singular vectors of the low-rank decomposition will also follow: they can be seen as principal components, hence, the first variant of our method is referred to as Rank-1-PCA. The second variant, referred to as Rank-1-ICA, additionally estimates the orthogonal transform which maps the deformation modes into as statistically independent modes as possible. It has the advantage of pinpointing statistically dependent subspaces related to, for instance, lip movements on human faces. Moreover, in contrast to prior works, no predefined dimensionality for the subspaces is imposed. The experiments on several datasets show that the method achieves better results than the state-of-the-art, it can be computed faster, and it provides an intuitive interpretation for the deformation modes.