 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Coordinate Reconstruction Priors
Oct 14, 2025Scene coordinate regression (SCR) models have proven to be powerful implicit scene representations for 3D vision, enabling visual relocalization and structure-from-motion. SCR models are trained specifically for one scene. If training images imply insufficient multi-view constraints SCR models degenerate. We present a probabilistic reinterpretation of training SCR models, which allows us to infuse high-level reconstruction priors. We investigate multiple such priors, ranging from simple priors over the distribution of reconstructed depth values to learned priors over plausible scene coordinate configurations. For the latter, we train a 3D point cloud diffusion model on a large corpus of indoor scans. Our priors push predicted 3D scene points towards plausible geometry at each training step to increase their likelihood. On three indoor datasets our priors help learning better scene representations, resulting in more coherent scene point clouds, higher registration rates and better camera poses, with a positive effect on down-stream tasks such as novel view synthesis and camera relocalization.
BOP Challenge 2024 on Model-Based and Model-Free 6D Object Pose Estimation
Apr 03, 2025We present the evaluation methodology, datasets and results of the BOP Challenge 2024, the sixth in a series of public competitions organized to capture the state of the art in 6D object pose estimation and related tasks. In 2024, our goal was to transition BOP from lab-like setups to real-world scenarios. First, we introduced new model-free tasks, where no 3D object models are available and methods need to onboard objects just from provided reference videos. Second, we defined a new, more practical 6D object detection task where identities of objects visible in a test image are not provided as input. Third, we introduced new BOP-H3 datasets recorded with high-resolution sensors and AR/VR headsets, closely resembling real-world scenarios. BOP-H3 include 3D models and onboarding videos to support both model-based and model-free tasks. Participants competed on seven challenge tracks, each defined by a task, object onboarding setup, and dataset group. Notably, the best 2024 method for model-based 6D localization of unseen objects (FreeZeV2.1) achieves 22% higher accuracy on BOP-Classic-Core than the best 2023 method (GenFlow), and is only 4% behind the best 2023 method for seen objects (GPose2023) although being significantly slower (24.9 vs 2.7s per image). A more practical 2024 method for this task is Co-op which takes only 0.8s per image and is 25X faster and 13% more accurate than GenFlow. Methods have a similar ranking on 6D detection as on 6D localization but higher run time. On model-based 2D detection of unseen objects, the best 2024 method (MUSE) achieves 21% relative improvement compared to the best 2023 method (CNOS). However, the 2D detection accuracy for unseen objects is still noticealy (-53%) behind the accuracy for seen objects (GDet2023). The online evaluation system stays open and is available at http://bop.felk.cvut.cz/
Scene Coordinate Reconstruction: Posing of Image Collections via Incremental Learning of a Relocalizer
Apr 22, 2024We address the task of estimating camera parameters from a set of images depicting a scene. Popular feature-based structure-from-motion (SfM) tools solve this task by incremental reconstruction: they repeat triangulation of sparse 3D points and registration of more camera views to the sparse point cloud. We re-interpret incremental structure-from-motion as an iterated application and refinement of a visual relocalizer, that is, of a method that registers new views to the current state of the reconstruction. This perspective allows us to investigate alternative visual relocalizers that are not rooted in local feature matching. We show that scene coordinate regression, a learning-based relocalization approach, allows us to build implicit, neural scene representations from unposed images. Different from other learning-based reconstruction methods, we do not require pose priors nor sequential inputs, and we optimize efficiently over thousands of images. Our method, ACE0 (ACE Zero), estimates camera poses to an accuracy comparable to feature-based SfM, as demonstrated by novel view synthesis. Project page: https://nianticlabs.github.io/acezero/
Map-Relative Pose Regression for Visual Re-Localization
Apr 15, 2024Pose regression networks predict the camera pose of a query image relative to a known environment. Within this family of methods, absolute pose regression (APR) has recently shown promising accuracy in the range of a few centimeters in position error. APR networks encode the scene geometry implicitly in their weights. To achieve high accuracy, they require vast amounts of training data that, realistically, can only be created using novel view synthesis in a days-long process. This process has to be repeated for each new scene again and again. We present a new approach to pose regression, map-relative pose regression (marepo), that satisfies the data hunger of the pose regression network in a scene-agnostic fashion. We condition the pose regressor on a scene-specific map representation such that its pose predictions are relative to the scene map. This allows us to train the pose regressor across hundreds of scenes to learn the generic relation between a scene-specific map representation and the camera pose. Our map-relative pose regressor can be applied to new map representations immediately or after mere minutes of fine-tuning for the highest accuracy. Our approach outperforms previous pose regression methods by far on two public datasets, indoor and outdoor. Code is available: https://nianticlabs.github.io/marepo
Matching 2D Images in 3D: Metric Relative Pose from Metric Correspondences
Apr 09, 2024



Given two images, we can estimate the relative camera pose between them by establishing image-to-image correspondences. Usually, correspondences are 2D-to-2D and the pose we estimate is defined only up to scale. Some applications, aiming at instant augmented reality anywhere, require scale-metric pose estimates, and hence, they rely on external depth estimators to recover the scale. We present MicKey, a keypoint matching pipeline that is able to predict metric correspondences in 3D camera space. By learning to match 3D coordinates across images, we are able to infer the metric relative pose without depth measurements. Depth measurements are also not required for training, nor are scene reconstructions or image overlap information. MicKey is supervised only by pairs of images and their relative poses. MicKey achieves state-of-the-art performance on the Map-Free Relocalisation benchmark while requiring less supervision than competing approaches.
Robust Shape Fitting for 3D Scene Abstraction
Mar 15, 2024



Humans perceive and construct the world as an arrangement of simple parametric models. In particular, we can often describe man-made environments using volumetric primitives such as cuboids or cylinders. Inferring these primitives is important for attaining high-level, abstract scene descriptions. Previous approaches for primitive-based abstraction estimate shape parameters directly and are only able to reproduce simple objects. In contrast, we propose a robust estimator for primitive fitting, which meaningfully abstracts complex real-world environments using cuboids. A RANSAC estimator guided by a neural network fits these primitives to a depth map. We condition the network on previously detected parts of the scene, parsing it one-by-one. To obtain cuboids from single RGB images, we additionally optimise a depth estimation CNN end-to-end. Naively minimising point-to-primitive distances leads to large or spurious cuboids occluding parts of the scene. We thus propose an improved occlusion-aware distance metric correctly handling opaque scenes. Furthermore, we present a neural network based cuboid solver which provides more parsimonious scene abstractions while also reducing inference time. The proposed algorithm does not require labour-intensive labels, such as cuboid annotations, for training. Results on the NYU Depth v2 dataset demonstrate that the proposed algorithm successfully abstracts cluttered real-world 3D scene layouts.
BOP Challenge 2023 on Detection, Segmentation and Pose Estimation of Seen and Unseen Rigid Objects
Mar 14, 2024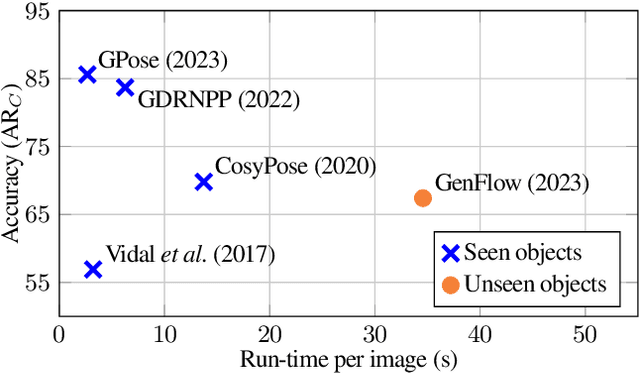
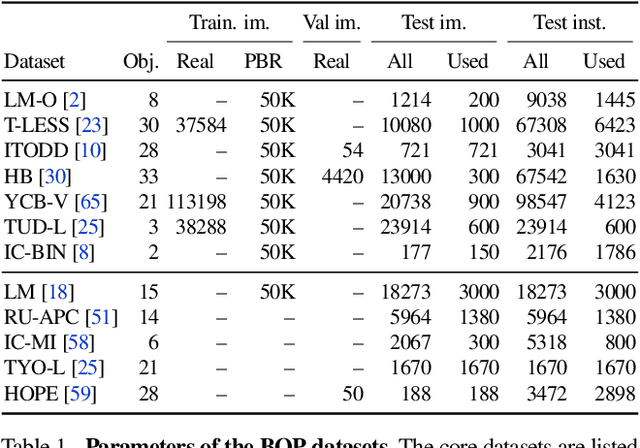


We present the evaluation methodology, datasets and results of the BOP Challenge 2023, the fifth in a series of public competitions organized to capture the state of the art in model-based 6D object pose estimation from an RGB/RGB-D image and related tasks. Besides the three tasks from 2022 (model-based 2D detection, 2D segmentation, and 6D localization of objects seen during training), the 2023 challenge introduced new variants of these tasks focused on objects unseen during training. In the new tasks, methods were required to learn new objects during a short onboarding stage (max 5 minutes, 1 GPU) from provided 3D object models. The best 2023 method for 6D localization of unseen objects (GenFlow) notably reached the accuracy of the best 2020 method for seen objects (CosyPose), although being noticeably slower. The best 2023 method for seen objects (GPose) achieved a moderate accuracy improvement but a significant 43% run-time improvement compared to the best 2022 counterpart (GDRNPP). Since 2017, the accuracy of 6D localization of seen objects has improved by more than 50% (from 56.9 to 85.6 AR_C). The online evaluation system stays open and is available at: http://bop.felk.cvut.cz/.
Two-View Geometry Scoring Without Correspondences
Jun 02, 2023Camera pose estimation for two-view geometry traditionally relies on RANSAC. Normally, a multitude of image correspondences leads to a pool of proposed hypotheses, which are then scored to find a winning model. The inlier count is generally regarded as a reliable indicator of "consensus". We examine this scoring heuristic, and find that it favors disappointing models under certain circumstances. As a remedy, we propose the Fundamental Scoring Network (FSNet), which infers a score for a pair of overlapping images and any proposed fundamental matrix. It does not rely on sparse correspondences, but rather embodies a two-view geometry model through an epipolar attention mechanism that predicts the pose error of the two images. FSNet can be incorporated into traditional RANSAC loops. We evaluate FSNet on fundamental and essential matrix estimation on indoor and outdoor datasets, and establish that FSNet can successfully identify good poses for pairs of images with few or unreliable correspondences. Besides, we show that naively combining FSNet with MAGSAC++ scoring approach achieves state of the art results.
Accelerated Coordinate Encoding: Learning to Relocalize in Minutes using RGB and Poses
May 23, 2023



Learning-based visual relocalizers exhibit leading pose accuracy, but require hours or days of training. Since training needs to happen on each new scene again, long training times make learning-based relocalization impractical for most applications, despite its promise of high accuracy. In this paper we show how such a system can actually achieve the same accuracy in less than 5 minutes. We start from the obvious: a relocalization network can be split in a scene-agnostic feature backbone, and a scene-specific prediction head. Less obvious: using an MLP prediction head allows us to optimize across thousands of view points simultaneously in each single training iteration. This leads to stable and extremely fast convergence. Furthermore, we substitute effective but slow end-to-end training using a robust pose solver with a curriculum over a reprojection loss. Our approach does not require privileged knowledge, such a depth maps or a 3D model, for speedy training. Overall, our approach is up to 300x faster in mapping than state-of-the-art scene coordinate regression, while keeping accuracy on par.
BOP Challenge 2022 on Detection, Segmentation and Pose Estimation of Specific Rigid Objects
Feb 25, 2023We present the evaluation methodology, datasets and results of the BOP Challenge 2022, the fourth in a series of public competitions organized with the goal to capture the status quo in the field of 6D object pose estimation from an RGB/RGB-D image. In 2022, we witnessed another significant improvement in the pose estimation accuracy -- the state of the art, which was 56.9 AR$_C$ in 2019 (Vidal et al.) and 69.8 AR$_C$ in 2020 (CosyPose), moved to new heights of 83.7 AR$_C$ (GDRNPP). Out of 49 pose estimation methods evaluated since 2019, the top 18 are from 2022. Methods based on point pair features, which were introduced in 2010 and achieved competitive results even in 2020, are now clearly outperformed by deep learning methods. The synthetic-to-real domain gap was again significantly reduced, with 82.7 AR$_C$ achieved by GDRNPP trained only on synthetic images from BlenderProc. The fastest variant of GDRNPP reached 80.5 AR$_C$ with an average time per image of 0.23s. Since most of the recent methods for 6D object pose estimation begin by detecting/segmenting objects, we also started evaluating 2D object detection and segmentation performance based on the COCO metrics. Compared to the Mask R-CNN results from CosyPose in 2020, detection improved from 60.3 to 77.3 AP$_C$ and segmentation from 40.5 to 58.7 AP$_C$. The online evaluation system stays open and is available at: \href{http://bop.felk.cvut.cz/}{bop.felk.cvut.cz}.