 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMap-free Visual Relocalization: Metric Pose Relative to a Single Image
Oct 11, 2022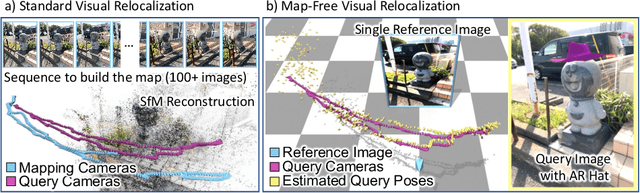

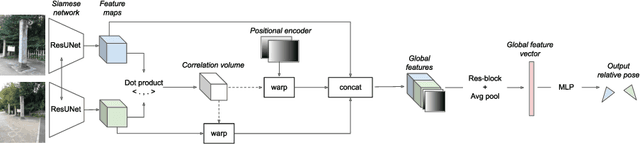

Can we relocalize in a scene represented by a single reference image? Standard visual relocalization requires hundreds of images and scale calibration to build a scene-specific 3D map. In contrast, we propose Map-free Relocalization, i.e., using only one photo of a scene to enable instant, metric scaled relocalization. Existing datasets are not suitable to benchmark map-free relocalization, due to their focus on large scenes or their limited variability. Thus, we have constructed a new dataset of 655 small places of interest, such as sculptures, murals and fountains, collected worldwide. Each place comes with a reference image to serve as a relocalization anchor, and dozens of query images with known, metric camera poses. The dataset features changing conditions, stark viewpoint changes, high variability across places, and queries with low to no visual overlap with the reference image. We identify two viable families of existing methods to provide baseline results: relative pose regression, and feature matching combined with single-image depth prediction. While these methods show reasonable performance on some favorable scenes in our dataset, map-free relocalization proves to be a challenge that requires new, innovative solutions.
Fast and Robust Registration of Partially Overlapping Point Clouds
Dec 18, 2021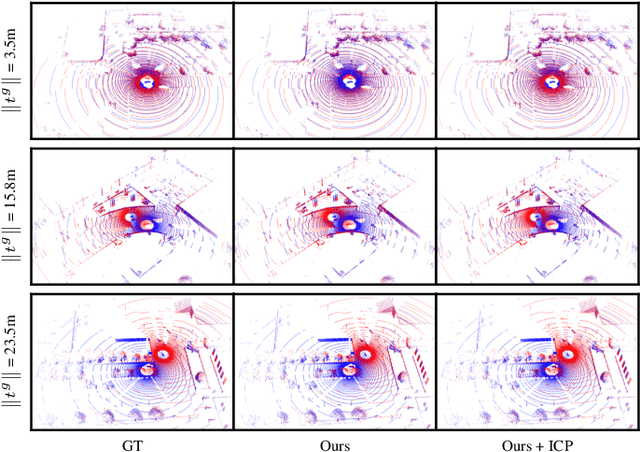

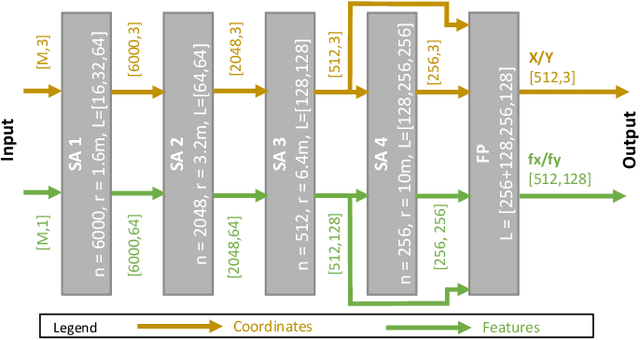
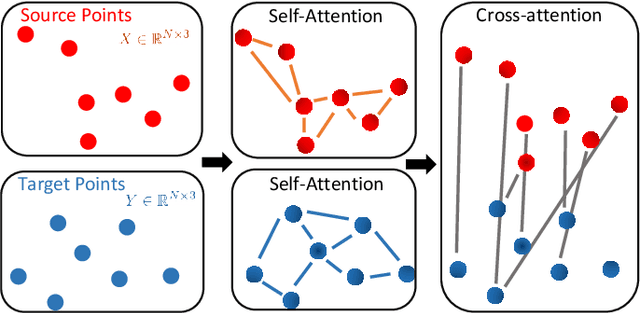
Real-time registration of partially overlapping point clouds has emerging applications in cooperative perception for autonomous vehicles and multi-agent SLAM. The relative translation between point clouds in these applications is higher than in traditional SLAM and odometry applications, which challenges the identification of correspondences and a successful registration. In this paper, we propose a novel registration method for partially overlapping point clouds where correspondences are learned using an efficient point-wise feature encoder, and refined using a graph-based attention network. This attention network exploits geometrical relationships between key points to improve the matching in point clouds with low overlap. At inference time, the relative pose transformation is obtained by robustly fitting the correspondences through sample consensus. The evaluation is performed on the KITTI dataset and a novel synthetic dataset including low-overlapping point clouds with displacements of up to 30m. The proposed method achieves on-par performance with state-of-the-art methods on the KITTI dataset, and outperforms existing methods for low overlapping point clouds. Additionally, the proposed method achieves significantly faster inference times, as low as 410ms, between 5 and 35 times faster than competing methods. Our code and dataset are available at https://github.com/eduardohenriquearnold/fastreg.
Early Lane Change Prediction for Automated Driving Systems Using Multi-Task Attention-based Convolutional Neural Networks
Sep 22, 2021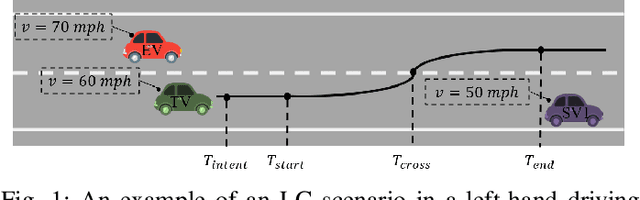
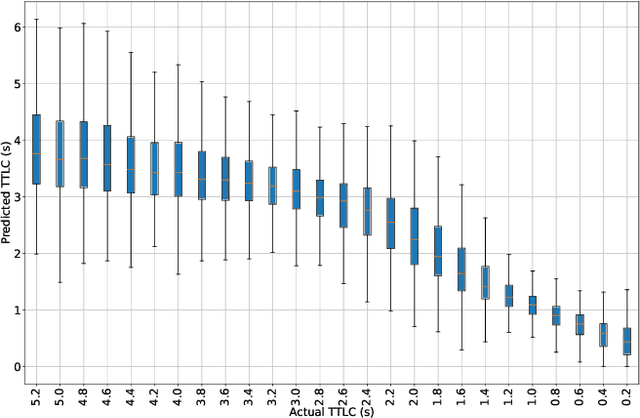
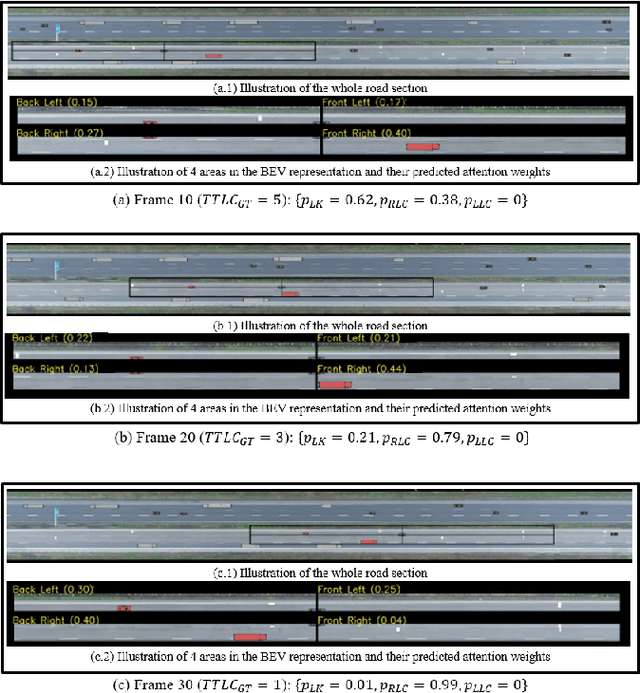

Lane change (LC) is one of the safety-critical manoeuvres in highway driving according to various road accident records. Thus, reliably predicting such manoeuvre in advance is critical for the safe and comfortable operation of automated driving systems. The majority of previous studies rely on detecting a manoeuvre that has been already started, rather than predicting the manoeuvre in advance. Furthermore, most of the previous works do not estimate the key timings of the manoeuvre (e.g., crossing time), which can actually yield more useful information for the decision making in the ego vehicle. To address these shortcomings, this paper proposes a novel multi-task model to simultaneously estimate the likelihood of LC manoeuvres and the time-to-lane-change (TTLC). In both tasks, an attention-based convolutional neural network (CNN) is used as a shared feature extractor from a bird's eye view representation of the driving environment. The spatial attention used in the CNN model improves the feature extraction process by focusing on the most relevant areas of the surrounding environment. In addition, two novel curriculum learning schemes are employed to train the proposed approach. The extensive evaluation and comparative analysis of the proposed method in existing benchmark datasets show that the proposed method outperforms state-of-the-art LC prediction models, particularly considering long-term prediction performance.
Visual Sensor Pose Optimisation Using Rendering-based Visibility Models for Robust Cooperative Perception
Jun 09, 2021

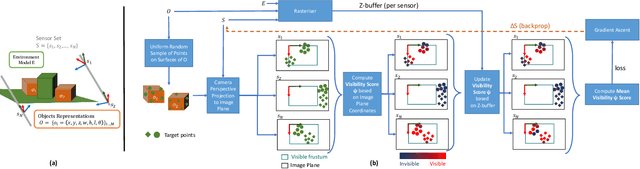
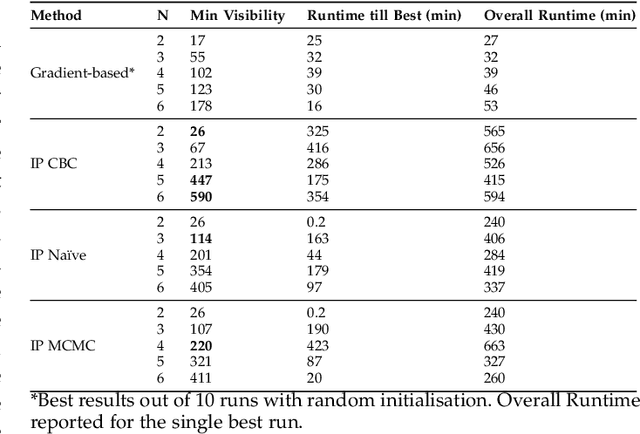
Visual Sensor Networks can be used in a variety of perception applications such as infrastructure support for autonomous driving in complex road segments. The pose of the sensors in such networks directly determines the coverage of the environment and objects therein, which impacts the performance of applications such as object detection and tracking. Existing sensor pose optimisation methods in the literature either maximise the coverage of ground surfaces, or consider the visibility of the target objects as binary variables, which cannot represent various degrees of visibility. Such formulations cannot guarantee the visibility of the target objects as they fail to consider occlusions. This paper proposes two novel sensor pose optimisation methods, based on gradient-ascent and Integer Programming techniques, which maximise the visibility of multiple target objects in cluttered environments. Both methods consider a realistic visibility model based on a rendering engine that provides pixel-level visibility information about the target objects. The proposed methods are evaluated in a complex environment and compared to existing methods in the literature. The evaluation results indicate that explicitly modelling the visibility of target objects is critical to avoid occlusions in cluttered environments. Furthermore, both methods significantly outperform existing methods in terms of object visibility.
Cooperative Perception for 3D Object Detection in Driving Scenarios using Infrastructure Sensors
Dec 18, 2019
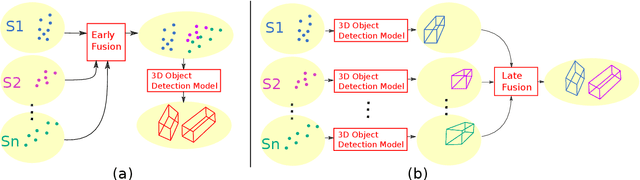


The perception system of an autonomous vehicle is responsible for mapping sensor observations into a semantic description of the vehicle's environment. 3D object detection is a common function within this system and outputs a list of 3D bounding boxes around objects of interest. Various 3D object detection methods have relied on fusion of different sensor modalities to overcome limitations of individual sensors. However, occlusion, limited field-of-view and low-point density of the sensor data cannot be reliably and cost-effectively addressed by multi-modal sensing from a single point of view. Alternatively, cooperative perception incorporates information from spatially diverse sensors distributed around the environment as a way to mitigate these limitations. This paper proposes two schemes for cooperative 3D object detection. The early fusion scheme combines point clouds from multiple spatially diverse sensing points of view before detection. In contrast, the late fusion scheme fuses the independently estimated bounding boxes from multiple spatially diverse sensors. We evaluate the performance of both schemes using a synthetic cooperative dataset created in two complex driving scenarios, a T-junction and a roundabout. The evaluation show that the early fusion approach outperforms late fusion by a significant margin at the cost of higher communication bandwidth. The results demonstrate that cooperative perception can recall more than 95% of the objects as opposed to 30% for single-point sensing in the most challenging scenario. To provide practical insights into the deployment of such system, we report how the number of sensors and their configuration impact the detection performance of the system.